ISA Mapper: A Compute and Hardware Agnostic Deep Learning Compiler
Domain specific accelerators present new challenges and opportunities for code generation onto novel instruction sets, communication fabrics, and memory architectures. In this paper we introduce an intermediate representation (IR) which enables both deep learning computational kernels and hardware capabilities to be described in the same IR. We then formulate and apply instruction mapping to determine the possible ways a computation can be performed on a hardware system. Next, our scheduler chooses a specific mapping and determines the data movement and computation order. In order to manage the large search space of mappings and schedules, we developed a flexible framework that allows heuristics, cost models, and potentially machine learning to facilitate this search problem. With this system, we demonstrate the automated extraction of matrix multiplication kernels out of recent deep learning kernels such as depthwise-separable convolution. In addition, we demonstrate two to five times better performance on DeepBench sized GEMMs and GRU RNN execution when compared to state-of-the-art (SOTA) implementations on new hardware and up to 85% of the performance for SOTA implementations on existing hardware.
Pyro: Deep Universal Probabilistic Programming
Pyro is a probabilistic programming language built on Python as a platform for developing advanced probabilistic models in AI research. To scale to large datasets and high-dimensional models, Pyro uses stochastic variational inference algorithms and probability distributions built on top of PyTorch, a modern GPU-accelerated deep learning framework. To accommodate complex or model-specific algorithmic behavior, Pyro leverages Poutine, a library of composable building blocks for modifying the behavior of probabilistic programs.
A Bayesian Nonparametric Method for Estimating Causal Treatment Effects on Zero-Inflated Outcomes
We present a Bayesian nonparametric method for estimating causal effects on continuous, zero-inflated outcomes. This work is motivated by a need for estimates of causal treatment effects on medical costs; that is, estimates contrasting average total costs that would have accrued under one treatment versus another. Cost data tend to be zero-inflated, skewed, and multi-modal. This presents a significant statistical challenge, even if the usual causal identification assumptions hold. Our approach flexibly models expected cost conditional on treatment and covariates using an infinite mixture of zero-inflated regressions. This conditional mean model is incorporated into the Bayesian standardization formula to obtain nonparametric estimates of causal effects. Moreover, the estimation procedure predicts latent cluster membership for each patient – automatically identifying patients with different cost-covariate profiles. We present a generative model, an MCMC method for sampling from the posterior and posterior predictive, and a Monte Carlo standardization procedure for computing causal effects. Our simulation studies show the resulting causal effect estimates and credible interval estimates to have low bias and close to nominal coverage, respectively. These results hold even under highly irregular data distributions. Relative to a standard infinite mixture of regressions, our method yields interval estimates with better coverage probability. We apply the method to compare inpatient costs among endometrial cancer patients receiving either chemotherapy or radiation therapy in the SEER Medicare database.
Univariate Mean Change Point Detection: Penalization, CUSUM and Optimality
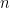
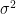
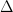


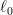
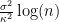
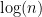
How to train your MAML
The field of few-shot learning has recently seen substantial advancements. Most of these advancements came from casting few-shot learning as a meta-learning problem. Model Agnostic Meta Learning or MAML is currently one of the best approaches for few-shot learning via meta-learning. MAML is simple, elegant and very powerful, however, it has a variety of issues, such as being very sensitive to neural network architectures, often leading to instability during training, requiring arduous hyperparameter searches to stabilize training and achieve high generalization and being very computationally expensive at both training and inference times. In this paper, we propose various modifications to MAML that not only stabilize the system, but also substantially improve the generalization performance, convergence speed and computational overhead of MAML, which we call MAML++.
Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks
Recurrent neural network (RNN) models are widely used for processing sequential data governed by a latent tree structure. Previous work shows that RNN models (especially Long Short-Term Memory (LSTM) based models) could learn to exploit the underlying tree structure. However, its performance consistently lags behind that of tree-based models. This work proposes a new inductive bias Ordered Neurons, which enforces an order of updating frequencies between hidden state neurons. We show that the ordered neurons could explicitly integrate the latent tree structure into recurrent models. To this end, we propose a new RNN unit: ON-LSTM, which achieve good performances on four different tasks: language modeling, unsupervised parsing, targeted syntactic evaluation, and logical inference.
An Efficient Bandit Algorithm for Realtime Multivariate Optimization
Optimization is commonly employed to determine the content of web pages, such as to maximize conversions on landing pages or click-through rates on search engine result pages. Often the layout of these pages can be decoupled into several separate decisions. For example, the composition of a landing page may involve deciding which image to show, which wording to use, what color background to display, etc. Such optimization is a combinatorial problem over an exponentially large decision space. Randomized experiments do not scale well to this setting, and therefore, in practice, one is typically limited to optimizing a single aspect of a web page at a time. This represents a missed opportunity in both the speed of experimentation and the exploitation of possible interactions between layout decisions. Here we focus on multivariate optimization of interactive web pages. We formulate an approach where the possible interactions between different components of the page are modeled explicitly. We apply bandit methodology to explore the layout space efficiently and use hill-climbing to select optimal content in realtime. Our algorithm also extends to contextualization and personalization of layout selection. Simulation results show the suitability of our approach to large decision spaces with strong interactions between content. We further apply our algorithm to optimize a message that promotes adoption of an Amazon service. After only a single week of online optimization, we saw a 21% conversion increase compared to the median layout. Our technique is currently being deployed to optimize content across several locations at Amazon.com.
A Fully Attention-Based Information Retriever
Recurrent neural networks are now the state-of-the-art in natural language processing because they can build rich contextual representations and process texts of arbitrary length. However, recent developments on attention mechanisms have equipped feedforward networks with similar capabilities, hence enabling faster computations due to the increase in the number of operations that can be parallelized. We explore this new type of architecture in the domain of question-answering and propose a novel approach that we call Fully Attention Based Information Retriever (FABIR). We show that FABIR achieves competitive results in the Stanford Question Answering Dataset (SQuAD) while having fewer parameters and being faster at both learning and inference than rival methods.
Model Selection Techniques — An Overview
In the era of big data, analysts usually explore various statistical models or machine learning methods for observed data in order to facilitate scientific discoveries or gain predictive power. Whatever data and fitting procedures are employed, a crucial step is to select the most appropriate model or method from a set of candidates. Model selection is a key ingredient in data analysis for reliable and reproducible statistical inference or prediction, and thus central to scientific studies in fields such as ecology, economics, engineering, finance, political science, biology, and epidemiology. There has been a long history of model selection techniques that arise from researches in statistics, information theory, and signal processing. A considerable number of methods have been proposed, following different philosophies and exhibiting varying performances. The purpose of this article is to bring a comprehensive overview of them, in terms of their motivation, large sample performance, and applicability. We provide integrated and practically relevant discussions on theoretical properties of state-of- the-art model selection approaches. We also share our thoughts on some controversial views on the practice of model selection.
Towards Universal Dialogue State Tracking
Dialogue state tracking is the core part of a spoken dialogue system. It estimates the beliefs of possible user’s goals at every dialogue turn. However, for most current approaches, it’s difficult to scale to large dialogue domains. They have one or more of following limitations: (a) Some models don’t work in the situation where slot values in ontology changes dynamically; (b) The number of model parameters is proportional to the number of slots; (c) Some models extract features based on hand-crafted lexicons. To tackle these challenges, we propose StateNet, a universal dialogue state tracker. It is independent of the number of values, shares parameters across all slots, and uses pre-trained word vectors instead of explicit semantic dictionaries. Our experiments on two datasets show that our approach not only overcomes the limitations, but also significantly outperforms the performance of state-of-the-art approaches.
Applying Deep Learning To Airbnb Search
The application to search ranking is one of the biggest machine learning success stories at Airbnb. Much of the initial gains were driven by a gradient boosted decision tree model. The gains, however, plateaued over time. This paper discusses the work done in applying neural networks in an attempt to break out of that plateau. We present our perspective not with the intention of pushing the frontier of new modeling techniques. Instead, ours is a story of the elements we found useful in applying neural networks to a real life product. Deep learning was steep learning for us. To other teams embarking on similar journeys, we hope an account of our struggles and triumphs will provide some useful pointers. Bon voyage!
Calendar-based graphics for visualizing people’s daily schedules
Calendars are broadly used in society to display temporal information, and events. This paper describes a new R package with functionality to organize and display temporal data, collected on sub-daily resolution, into a calendar layout. The function frame_calendar uses linear algebra on the date variable to restructure data into a format lending itself to calendar layouts. The user can apply the grammar of graphics to create plots inside each calendar cell, and thus the displays synchronize neatly with ggplot2 graphics. The motivating application is studying pedestrian behavior in Melbourne, Australia, based on counts which are captured at hourly intervals by sensors scattered around the city. Faceting by the usual features such as day and month, was insufficient to examine the behavior. Making displays on a monthly calendar format helps to understand pedestrian patterns relative to events such as work days, weekends, holidays, and special events. The layout algorithm has several format options and variations. It is implemented in the R package sugrrants.
What can AI do for me: Evaluating Machine Learning Interpretations in Cooperative Play
Machine learning is an important tool for decision making, but its ethical and responsible application requires rigorous vetting of its interpretability and utility: an understudied problem, particularly for natural language processing models. We design a task-specific evaluation for a question answering task and evaluate how well a model interpretation improves human performance in a human-machine cooperative setting. We evaluate interpretation methods in a grounded, realistic setting: playing a trivia game as a team. We also provide design guidance for natural language processing human-in-the-loop settings.
Online learning with feedback graphs and switching costs
We study online learning when partial feedback information is provided following every action of the learning process, and the learner incurs switching costs for changing his actions. In this setting, the feedback information system can be represented by a graph, and previous work provided the expected regret of the learner in the case of a clique (Expert setup), or disconnected single loops (Multi-Armed Bandits). We provide a lower bound on the expected regret in the partial information (PI) setting, namely for general feedback graphs —excluding the clique. We show that all algorithms that are optimal without switching costs are necessarily sub-optimal in the presence of switching costs, which motivates the need to design new algorithms in this setup. We propose two novel algorithms: Threshold Based EXP3 and EXP3.SC. For the two special cases of symmetric PI setting and Multi-Armed-Bandits, we show that the expected regret of both algorithms is order optimal in the duration of the learning process with a pre-constant dependent on the feedback system. Additionally, we show that Threshold Based EXP3 is order optimal in the switching cost, whereas EXP3.SC is not. Finally, empirical evaluations show that Threshold Based EXP3 outperforms previous algorithm EXP3 SET in the presence of switching costs, and Batch EXP3 in the special setting of Multi-Armed Bandits with switching costs, where both algorithms are order optimal.
numpywren: serverless linear algebra
Linear algebra operations are widely used in scientific computing and machine learning applications. However, it is challenging for scientists and data analysts to run linear algebra at scales beyond a single machine. Traditional approaches either require access to supercomputing clusters, or impose configuration and cluster management challenges. In this paper we show how the disaggregation of storage and compute resources in so-called ‘serverless’ environments, combined with compute-intensive workload characteristics, can be exploited to achieve elastic scalability and ease of management. We present numpywren, a system for linear algebra built on a serverless architecture. We also introduce LAmbdaPACK, a domain-specific language designed to implement highly parallel linear algebra algorithms in a serverless setting. We show that, for certain linear algebra algorithms such as matrix multiply, singular value decomposition, and Cholesky decomposition, numpywren’s performance (completion time) is within 33% of ScaLAPACK, and its compute efficiency (total CPU-hours) is up to 240% better due to elasticity, while providing an easier to use interface and better fault tolerance. At the same time, we show that the inability of serverless runtimes to exploit locality across the cores in a machine fundamentally limits their network efficiency, which limits performance on other algorithms such as QR factorization. This highlights how cloud providers could better support these types of computations through small changes in their infrastructure.
Bivariate modelling of precipitation and temperature: Bivariate modelling of precipitation and temperature using a non-homogeneous hidden Markov model
Aiming to generate realistic synthetic times series of the bivariate process of daily mean temperature and precipitations, we introduce a non-homogeneous hidden Markov model. The non-homogeneity lies in periodic transition probabilities between the hidden states, and time-dependent emission distributions. This enables the model to account for the non-stationary behaviour of weather variables. By carefully choosing the emission distributions, it is also possible to model the dependance structure between the two variables. The model is applied to several weather stations in Europe with various climates, and we show that it is able to simulate realistic bivariate time series.
Ain’t Nobody Got Time For Coding: Structure-Aware Program Synthesis From Natural Language
Program synthesis from natural language (NL) is practical for humans and, once technically feasible, would significantly facilitate software development and revolutionize end-user programming. We present SAPS, an end-to-end neural network capable of mapping relatively complex, multi-sentence NL specifications to snippets of executable code. The proposed architecture relies exclusively on neural components, and is built upon a tree2tree autoencoder trained on abstract syntax trees, combined with a pretrained word embedding and a bi-directional multi-layer LSTM for NL processing. The decoder features a doubly-recurrent LSTM with a novel signal propagation scheme and soft attention mechanism. When applied to a large dataset of problems proposed in a previous study, SAPS performs on par with or better than the method proposed there, producing correct programs in over 90% of cases. In contrast to other methods, it does not involve any non-neural components to post-process the resulting programs, and uses a fixed-dimensional latent representation as the only link between the NL analyzer and source code generator.
CEREALS – Cost-Effective REgion-based Active Learning for Semantic Segmentation
State of the art methods for semantic image segmentation are trained in a supervised fashion using a large corpus of fully labeled training images. However, gathering such a corpus is expensive, due to human annotation effort, in contrast to gathering unlabeled data. We propose an active learning-based strategy, called CEREALS, in which a human only has to hand-label a few, automatically selected, regions within an unlabeled image corpus. This minimizes human annotation effort while maximizing the performance of a semantic image segmentation method. The automatic selection procedure is achieved by: a) using a suitable information measure combined with an estimate about human annotation effort, which is inferred from a learned cost model, and b) exploiting the spatial coherency of an image. The performance of CEREALS is demonstrated on Cityscapes, where we are able to reduce the annotation effort to 17%, while keeping 95% of the mean Intersection over Union (mIoU) of a model that was trained with the fully annotated training set of Cityscapes.
Goodness-of-Fit Tests for Large Datasets
Nowadays, data analysis in the world of Big Data is connected typically to data mining, descriptive or exploratory statistics, e.~g.\ cluster analysis, classification or regression analysis. Aside these techniques there is a huge area of methods from inferential statistics that are rarely considered in connection with Big Data. Nevertheless, inferential methods are also of use for Big Data analysis, especially for quantifying uncertainty. The article at hand will provide some insights to methodological and technical issues referring inferential methods in the Big Data area in order to bring together Big Data and inferential statistics, as it comes along with its difficulties. We present an approach that allows testing goodness-of-fit without model assumptions and relying on the empirical distribution. Especially, the method is able to utilize information from large datasets. Thereby, the approach is based on a clear theoretical background. We concentrate on the widely-used Kolmogorov-Smirnov test that is applied for testing goodness-of-fit in statistics. Our approach can be parallelized easily, which makes it applicable to distributed datasets particularly on a compute cluster. By this contribution, we turn to an audience that is interested in the technical and methodological backgrounds while implementing especially inferential statistical methods with Big Data tools as e. g. Spark.
DCSVM: Fast Multi-class Classification using Support Vector Machines
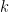


DropFilter: Dropout for Convolutions
Using a large number of parameters , deep neural networks have achieved remarkable performance on computer vison and natural language processing tasks. However the networks usually suffer from overfitting by using too much parameters. Dropout is a widely use method to deal with overfitting. Although dropout can significantly regularize densely connected layers in neural networks, it leads to suboptimal results when using for convolutional layers. To track this problem, we propose DropFilter, a new dropout method for convolutional layers. DropFilter randomly suppresses the outputs of some filters. Because it is observed that co-adaptions are more likely to occurs inter filters rather than intra filters in convolutional layers. Using DropFilter, we remarkably improve the performance of convolutional networks on CIFAR and ImageNet.
Deep Neural Network inference with reduced word length
Deep neural networks (DNN) are powerful models for many pattern recognition tasks, yet their high computational complexity and memory requirement limit them to applications on high-performance computing platforms. In this paper, we propose a new method to evaluate DNNs trained with 32bit floating point (float32) accuracy using only low precision integer arithmetics in combination with binary shift and clipping operations. Because hardware implementation of these operations is much simpler than high precision floating point calculation, our method can be used for an efficient DNN inference on dedicated hardware. In experiments on MNIST, we demonstrate that DNNs trained with float32 can be evaluated using a combination of 2bit integer arithmetics and a few float32 calculations in each layer or only 3bit integer arithmetics in combination with binary shift and clipping without significant performance degradation.
Automatic Full Compilation of Julia Programs and ML Models to Cloud TPUs
Google’s Cloud TPUs are a promising new hardware architecture for machine learning workloads. They have powered many of Google’s milestone machine learning achievements in recent years. Google has now made TPUs available for general use on their cloud platform and as of very recently has opened them up further to allow use by non-TensorFlow frontends. We describe a method and implementation for offloading suitable sections of Julia programs to TPUs via this new API and the Google XLA compiler. Our method is able to completely fuse the forward pass of a VGG19 model expressed as a Julia program into a single TPU executable to be offloaded to the device. Our method composes well with existing compiler-based automatic differentiation techniques on Julia code, and we are thus able to also automatically obtain the VGG19 backwards pass and similarly offload it to the TPU. Targeting TPUs using our compiler, we are able to evaluate the VGG19 forward pass on a batch of 100 images in 0.23s which compares favorably to the 52.4s required for the original model on the CPU. Our implementation is less than 1000 lines of Julia, with no TPU specific changes made to the core Julia compiler or any other Julia packages.
Feasibility of Supervised Machine Learning for Cloud Security
Cloud computing is gaining significant attention, however, security is the biggest hurdle in its wide acceptance. Users of cloud services are under constant fear of data loss, security threats and availability issues. Recently, learning-based methods for security applications are gaining popularity in the literature with the advents in machine learning techniques. However, the major challenge in these methods is obtaining real-time and unbiased datasets. Many datasets are internal and cannot be shared due to privacy issues or may lack certain statistical characteristics. As a result of this, researchers prefer to generate datasets for training and testing purpose in the simulated or closed experimental environments which may lack comprehensiveness. Machine learning models trained with such a single dataset generally result in a semantic gap between results and their application. There is a dearth of research work which demonstrates the effectiveness of these models across multiple datasets obtained in different environments. We argue that it is necessary to test the robustness of the machine learning models, especially in diversified operating conditions, which are prevalent in cloud scenarios. In this work, we use the UNSW dataset to train the supervised machine learning models. We then test these models with ISOT dataset. We present our results and argue that more research in the field of machine learning is still required for its applicability to the cloud security.
Heterogeneous large datasets integration using Bayesian factor regression
Two key challenges in modern statistical applications are the large amount of information recorded per individual, and that such data are often not collected all at once but in batches. These batch effects can be complex, causing distortions in both mean and variance. We propose a novel sparse latent factor regression model to integrate such heterogeneous data. The model provides a tool for data exploration via dimensionality reduction while correcting for a range of batch effects. We study the use of several sparse priors (local and non-local) to learn the dimension of the latent factors. Our model is fitted in a deterministic fashion by means of an EM algorithm for which we derive closed-form updates, contributing a novel scalable algorithm for non-local priors of interest beyond the immediate scope of this paper. We present several examples, with a focus on bioinformatics applications. Our results show an increase in the accuracy of the dimensionality reduction, with non-local priors substantially improving the reconstruction of factor cardinality, as well as the need to account for batch effects to obtain reliable results. Our model provides a novel approach to latent factor regression that balances sparsity with sensitivity and is highly computationally efficient.
Dynamic Likelihood-free Inference via Ratio Estimation (DIRE)
Parametric statistical models that are implicitly defined in terms of a stochastic data generating process are used in a wide range of scientific disciplines because they enable accurate modeling. However, learning the parameters from observed data is generally very difficult because their likelihood function is typically intractable. Likelihood-free Bayesian inference methods have been proposed which include the frameworks of approximate Bayesian computation (ABC), synthetic likelihood, and its recent generalization that performs likelihood-free inference by ratio estimation (LFIRE). A major difficulty in all these methods is choosing summary statistics that reduce the dimensionality of the data to facilitate inference. While several methods for choosing summary statistics have been proposed for ABC, the literature for synthetic likelihood and LFIRE is very thin to date. We here address this gap in the literature, focusing on the important special case of time-series models. We show that convolutional neural networks trained to predict the input parameters from the data provide suitable summary statistics for LFIRE. On a wide range of time-series models, a single neural network architecture produced equally or more accurate posteriors than alternative methods.
Clustering Time Series with Nonlinear Dynamics: A Bayesian Non-Parametric and Particle-Based Approach
We propose a statistical framework for clustering multiple time series that exhibit nonlinear dynamics into an a-priori-unknown number of sub-groups that each comprise time series with similar dynamics. Our motivation comes from neuroscience where an important problem is to identify, within a large assembly of neurons, sub-groups that respond similarly to a stimulus or contingency. In the neural setting, conditioned on cluster membership and the parameters governing the dynamics, time series within a cluster are assumed independent and generated according to a nonlinear binomial state-space model. We derive a Metropolis-within-Gibbs algorithm for full Bayesian inference that alternates between sampling of cluster membership and sampling of parameters of interest. The Metropolis step is a PMMH iteration that requires an unbiased, low variance estimate of the likelihood function of a nonlinear state-space model. We leverage recent results on controlled sequential Monte Carlo to estimate likelihood functions more efficiently compared to the bootstrap particle filter. We apply the framework to time series acquired from the prefrontal cortex of mice in an experiment designed to characterize the neural underpinnings of fear.
Brand > Logo: Visual Analysis of Fashion Brands
While lots of people may think branding begins and ends with a logo, fashion brands communicate their uniqueness through a wide range of visual cues such as color, patterns and shapes. In this work, we analyze learned visual representations by deep networks that are trained to recognize fashion brands. In particular, the activation strength and extent of neurons are studied to provide interesting insights about visual brand expressions. The proposed method identifies where a brand stands in the spectrum of branding strategy, i.e., from trademark-emblazoned goods with bold logos to implicit no logo marketing. By quantifying attention maps, we are able to interpret the visual characteristics of a brand present in a single image and model the general design direction of a brand as a whole. We further investigate versatility of neurons and discover ‘specialists’ that are highly brand-specific and ‘generalists’ that detect diverse visual features. A human experiment based on three main visual scenarios of fashion brands is conducted to verify the alignment of our quantitative measures with the human perception of brands. This paper demonstrate how deep networks go beyond logos in order to recognize clothing brands in an image.
Preprocessor Selection for Machine Learning Pipelines
Much of the work in metalearning has focused on classifier selection, combined more recently with hyperparameter optimization, with little concern for data preprocessing. Yet, it is generally well accepted that machine learning applications require not only model building, but also data preprocessing. In other words, practical solutions consist of pipelines of machine learning operators rather than single algorithms. Interestingly, our experiments suggest that, on average, data preprocessing hinders accuracy, while the best performing pipelines do actually make use of preprocessors. Here, we conduct an extensive empirical study over a wide range of learning algorithms and preprocessors, and use metalearning to determine when one should make use of preprocessors in ML pipeline design.
Meta-Learning Multi-task Communication
In this paper, we describe a general framework: Parameters Read-Write Networks (PRaWNs) to systematically analyze current neural models for multi-task learning, in which we find that existing models expect to disentangle features into different spaces while features learned in practice are still entangled in shared space, leaving potential hazards for other training or unseen tasks. We propose to alleviate this problem by incorporating an inductive bias into the process of multi-task learning, that each task can keep informed of not only the knowledge stored in other tasks but the way how other tasks maintain their knowledge. In practice, we achieve above inductive bias by allowing different tasks to communicate by passing both hidden variables and gradients explicitly. Experimentally, we evaluate proposed methods on three groups of tasks and two types of settings (\textsc{in-task} and \textsc{out-of-task}). Quantitative and qualitative results show their effectiveness.
Computation Scheduling for Distributed Machine Learning with Straggling Workers
Bayesian Model Search for Nonstationary Periodic Time Series
We propose a novel Bayesian methodology for analyzing nonstationary time series that exhibit oscillatory behaviour. We approximate the time series using a piecewise oscillatory model with unknown periodicities, where our goal is to estimate the change-points while simultaneously identifying the potentially changing periodicities in the data. Our proposed methodology is based on a trans-dimensional Markov chain Monte Carlo (MCMC) algorithm that simultaneously updates the change-points and the periodicities relevant to any segment between them. We show that the proposed methodology successfully identifies time changing oscillatory behaviour in two applications which are relevant to e-Health and sleep research, namely the occurrence of ultradian oscillations in human skin temperature during the time of night rest, and the detection of instances of sleep apnea in plethysmographic respiratory traces.
• Improving Stock Movement Prediction with Adversarial Training• A Scalable, Flexible Augmentation of the Student Education Process• On the ability of discontinuous Galerkin methods to simulate under-resolved turbulent flows• Resonant Inductive Coupling as a Potential Means for Wireless Power Transfer to Printed Spiral Coil• On Fractional Annealing Process• Non-data-aided SNR Estimation for QPSK Modulation in AWGN Channel• Estimating the Number of Sources: An Efficient Maximization Approach• Triad-NVM: Persistent-Security for Integrity-Protected and Encrypted Non-Volatile Memories (NVMs)• Data models for service failure prediction in supply-chain networks• Deep multi-survey classification of variable stars• On simultaneous conjugation of permutations• OS Scheduling Algorithms for Improving the Performance of Multithreaded Workloads• Mechanism Design for Social Good• Digital holographic particle volume reconstruction using a deep neural network• Controllability and maximum matchings of complex networks• Atomic Characterizations of Weak Martingale Musielak–Orlicz Hardy Spaces and Their Applications• A Method for Robust Online Classification using Dictionary Learning: Development and Assessment for Monitoring Manual Material Handling Activities Using Wearable Sensors• Health Monitoring of Critical Power System Equipments using Identifying Codes• Highly accurate acoustic scattering: Isogeometric Analysis coupled with local high order Farfield Expansion ABC• A jamming transition from under- to over-parametrization affects loss landscape and generalization• Spectral operators of matrices: semismoothness and characterizations of the generalized Jacobian• Single Image Haze Removal using a Generative Adversarial Network• Scaling Up Cartesian Genetic Programming through Preferential Selection of Larger Solutions• Diagnostic Accuracy of Content Based Dermatoscopic Image Retrieval with Deep Classification Features• Hierarchical multi-class segmentation of glioma images using networks with multi-level activation function• A Central Limit Theorem for the stochastic heat equation• Two view constraints on the epipoles from few correspondences• Comparing Two Approaches in Heteroscedastic Regression Models• A Comparative Study of Fruit Detection and Counting Methods for Yield Mapping in Apple Orchards• A Family of Statistical Divergences Based on Quasiarithmetic Means• Automatically Detecting Self-Reported Birth Defect Outcomes on Twitter for Large-scale Epidemiological Research• Monitoring & Mitigation of Delayed Voltage Recovery using μPMU Measurements with Reduced Distribution System Model• Monitoring Long Term Voltage Instability due to Distribution & Transmission Interaction using Unbalanced μPMU & PMU Measurements• Universal origin of boson peak vibrational anomalies in ordered crystals and in amorphous materials• Adversarial Risk Bounds for Binary Classification via Function Transformation• Multivariate stable distributions and their applications for modelling cryptocurrency-returns• Selection of BJI configuration: Approach based on minimal transversals• Non-equilibrium Fluctuations of Interacting Particle Systems• A Weakly Supervised Approach for Estimating Spatial Density Functions from High-Resolution Satellite Imagery• Recovery, detection and confidence sets of communities in a sparse stochastic block model• Enhanced Representative Days and System States Modeling for Energy Storage Investment Analysis• On local time at time varying curve• Introducing Curvature to the Label Space• A switch convergence for a small perturbation of a linear recurrence equation• Average group effect of strongly correlated predictor variables is estimable• Learning Probabilistic Trajectory Models of Aircraft in Terminal Airspace from Position Data• Perturbation Bounds for Procrustes, Classical Scaling, and Trilateration, with Applications to Manifold Learning• Secondary voltage control for microgrids using nonlinear multiple models adaptive control with unmodeled dynamics• Bioresorbable Scaffold Visualization in IVOCT Images Using CNNs and Weakly Supervised Localization• Two-path 3D CNNs for calibration of system parameters for OCT-based motion compensation• Martingale theory for housekeeping heat• The Lives of Bots• MiME: Multilevel Medical Embedding of Electronic Health Records for Predictive Healthcare• Biomedical Document Clustering and Visualization based on the Concepts of Diseases• Explainable artificial intelligence (XAI), the goodness criteria and the grasp-ability test• Zero temperature limit for the Brownian directed polymer among Poissonian disasters• Malleability of complex networks• Neural Transition-based Syntactic Linearization• How to Read Paintings: Semantic Art Understanding with Multi-Modal Retrieval• Sparse DNNs with Improved Adversarial Robustness• Deep Neural Ranking for Crowdsourced Geopolitical Event Forecasting• A Neural Compositional Paradigm for Image Captioning• Point-cloud-based place recognition using CNN feature extraction• One Bit Matters: Understanding Adversarial Examples as the Abuse of Redundancy• Hierarchical Approaches for Reinforcement Learning in Parameterized Action Space• Face Recognition from Sequential Sparse 3D data via Deep Registration• Large scale visual place recognition with sub-linear storage growth• Two-way Function Computation• Consistency of the total least squares estimator in the linear errors-in-variables regression• Cliquet option pricing in a jump-diffusion Lévy model• Capacity Degradation with Modeling Hardware Impairment in Large Intelligent Surface• Action-Agnostic Human Pose Forecasting• A Local Limit Theorem for Robbins-Monro Procedure• On a bound of the absolute constant in the Berry–Esseen inequality for i.i.d. Bernoulli random variables• Unsupervised Features Extraction for Binary Similarity Using Graph Embedding Neural Networks• Direct experimental determination of critical disorder in one-dimensional weakly disordered photonic crystals• Challenges of Convex Quadratic Bi-objective Benchmark Problems• The Key Player Problem in Complex Oscillator Networks and Electric Power Grids: Resistance Centralities Identify Local Vulnerabilities• The Interpretation of Linear Prediction by Interpolation Framework and Two General Constructive Methods• Semi-supervised acoustic model training for speech with code-switching• Consistency-aware Shading Orders Selective Fusion for Intrinsic Image Decomposition• On the difference-to-sum power ratio of speech and wind noise based on the Corcos model• Finding Appropriate Traffic Regulations via Graph Convolutional Networks• Color naming guided intrinsic image decomposition• On the tree cover number and the positive semidefinite maximum nullity of a graph• Design Challenges of Multi-UAV Systems in Cyber-Physical Applications: A Comprehensive Survey, and Future Directions• A Generalization of Smillie’s Theorem on Strongly Cooperative Tridiagonal Systems• OCAPIS: R package for Ordinal Classification And Preprocessing In Scala• Domain Adaptive Segmentation in Volume Electron Microscopy Imaging• Convolutional Neural Network Pruning to Accelerate Membrane Segmentation in Electron Microscopy• More on rainbow disconnection in graphs• Bayesian Deconvolution of Scanning Electron Microscopy Images Using Point-spread Function Estimation and Non-local Regularization• A generalization of Noel-Reed-Wu Theorem to signed graphs• On the Secrecy Unicast Throughput Performance of NOMA Assisted Multicast-Unicast Streaming With Partial Channel Information• On PAC-Bayesian Bounds for Random Forests• Objective Bayesian Comparison of Order-Constrained Models in Contingency Tables• Analysis of Atomistic Representations Using Weighted Skip-Connections• Estimation of Spatial-Temporal Gait Parameters based on the Fusion of Inertial and Film-Pressure Signals• Adaptation Bounds for Confidence Bands under Self-Similarity• Monochromatic combinatorial lines of length three• High Performance Computing with FPGAs and OpenCL• Neural Network Models for Natural Language Inference Fail to Capture the Semantics of Inference• Visual Semantic Re-ranker for Text Spotting• Optimal Analysis of Discrete-time Affine Systems• Algebraic Localization from Power-Law Interactions in Disordered Quantum Wires• Heuristics-based Query Reordering for Federated Queries in SPARQL 1.1 and SPARQL-LD• A Social Network Analysis of Articles on Social Network Analysis• Fixing Match-Fixing• A method to search for long duration gravitational wave transients from isolated neutron stars using the generalized FrequencyHough• SING: Symbol-to-Instrument Neural Generator• Characteristic Functionals of Dirichlet Measures• A proof of the Shepp-Olkin entropy monotonicity conjecture• On the bilinear control of the Gross-Pitaevskii equation• Operational Methods in the Study of Sobolev-Jacobi Polynomials• Heading in the right direction? Using head moves to traverse phylogenetic network space• Expression Recognition Using the Periocular Region: A Feasibility Study• Improving Automated Latent Fingerprint Identification using Extended Minutia Types• A Community Microgrid Architecture with an Internal Local Market• Action and intention recognition of pedestrians in urban traffic• PreCo: A Large-scale Dataset in Preschool Vocabulary for Coreference Resolution• Multivariate Locally Stationary Wavelet Process Analysis with the mvLSW R Package• Fruit and Vegetable Identification Using Machine Learning for Retail Applications• Hybrid Beamforming With Sub-arrayed MIMO Radar: Enabling Joint Sensing and Communication at mmWave Band• Learning Optimal Scheduling Policy for Remote State Estimation under Uncertain Channel Condition• Self-Erasing Network for Integral Object Attention• Capacitated Assortment Optimization with Pricing under the Paired Combinatorial Logit Model• LincoSim: a web based HPC-cloud platform for automatic virtual towing tank analysis• On orthogonal symmetric chain decompositions• Persistence exponents via perturbation theory: AR(1)-processes• Non-convex approach to binary compressed sensing• Scaling of the Sasamoto-Spohn model in equilibrium• Perfect Codes for Generalized Deletions from Minuscule Elements of Weyl Groups• A predictive processing model of perception and action for self-other distinction• Empirical Regularized Optimal Transport: Statistical Theory and Applications• Term structure modeling for multiple curves with stochastic discontinuities• Positional strategies in games of best choice• Linear Receivers in Non-stationary Massive MIMO Channels with Visibility Regions• Asymptotic Theory of Bayes Factor for Nonparametric Model and Variable Selection in the Gaussian Process Framework• Impedance/Admittance Modeling of Three-Phase AC Systems: A General Framework• Efficient Bayesian Experimental Design for Implicit Models• Connectivity of inhomogeneous random K-out graphs• Learning Classical Planning Strategies with Policy Gradient• Expansion of coset graphs of PSL_2(F_p)• Machine Learning Accelerated Likelihood-Free Event Reconstruction in Dark Matter Direct Detection• Random Bernstein-Markov factors• Dynamics of Order Parameters of Non-stoquastic Hamiltonians in the Adaptive Quantum Monte Carlo Method• Interpretable LSTMs For Whole-Brain Neuroimaging Analyses• Object-oriented lexical encoding of multiword expressions: Short and sweet• Stepwise Acquisition of Dialogue Act Through Human-Robot Interaction• GhostVLAD for set-based face recognition• Agent-Based Modeling and Simulation of Connected and Automated Vehicles Using Game Engine: A Cooperative On-Ramp Merging Study• Sharply $k$-arc-transitive-digraphs: finite and infinite examples• Social Status and Communication Behavior in an Evolving Social Network• Using Deep Learning for price prediction by exploiting stationary limit order book features• Efficient Eligibility Traces for Deep Reinforcement Learning• Algorithmic Traversals of Infinite Graphs• Learning First-to-Spike Policies for Neuromorphic Control Using Policy Gradients• A Systematic Framework and Characterization of Influence-Based Network Centrality• Automated Reasoning in Normative Detachment Structures with Ideal Conditions• Deep Graph Convolutional Encoders for Structured Data to Text Generation
Like this:
Like Loading…
Related