I’ve written a bit about automated machine learning in the past. I won’t recap any of the introductory material what I have already covered, but if interested in running down the main points, as well as a foray into the practical, feel free to peruse these articles before moving on.
In my view, the practice of machine learning comes down to 2 main overarching tasks, and as such in a restrained practical definition we can consider the core of automated machine learning to be:
automated feature engineering and/or selection automated hyperparameter tuning and architecture search
Semantically, the training of a machine learning model, while the result of these automated steps, is incidental to the automated machine learning process, while automated steps such as model evaluation and model selection are ancillary to the core. See Figure 1.
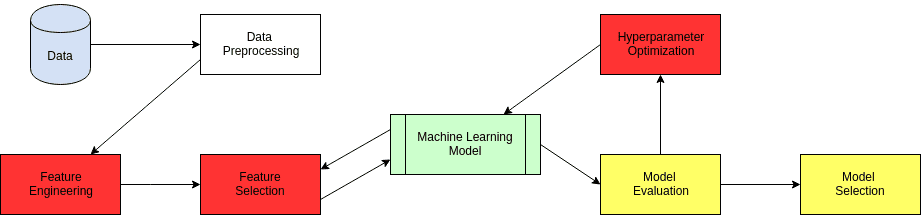
This is all well and good, theoretically speaking. But what if you want to implement an automated machine learning pipeline of your very own, or automate particular aspects of a machine learning pipeline with respect to the 2 overarching tasks outlined above?
Rest assured that there is no need to reinvent any wheels; automated machine learning as a discipline, may not yet be fully formed, but neither is it totally undeveloped at this point. See below for a sampling of open source tools which can help with fleshing out an automated machine learning pipeline of your very own.
Keep in mind that it is the first set below (hyperparameter tuning & architecture search) which are generally considered to be “automated machine learning tools” in a broad sense. However, note that the hyperparameter tuning & architecture search tools can and often do also perform some type of feature selection. There is a strong set of tools which provide only automated feature engineering and/or selection (caution that your definition of automated may not jive in one of those particular cases), and so a sampling of those tools are also presented.
Automated Hyperparameter Tuning & Architecture Search
Auto-Keras
Auto-Keras is an open source software library for automated machine learning (AutoML). It is developed by DATA Lab at Texas A&M University and community contributors. The ultimate goal of AutoML is to provide easily accessible deep learning tools to domain experts with limited data science or machine learning background. Auto-Keras provides functions to automatically search for architecture and hyperparameters of deep learning models.
auto-sklearn
auto-sklearn is an automated machine learning toolkit and a drop-in replacement for a scikit-learn estimator. auto-sklearn frees a machine learning user from algorithm selection and hyperparameter tuning. It leverages recent advantages in Bayesian optimization, meta-learning and ensemble construction. Learn more about the technology behind auto-sklearn by reading our paper published at NIPS 2015.
MLBox
MLBox is a powerful Automated Machine Learning python library. It provides the following features:
Fast reading and distributed data preprocessing/cleaning/formatting Highly robust feature selection and leak detection Accurate hyper-parameter optimization in high-dimensional space State-of-the art predictive models for classification and regression (Deep Learning, Stacking, LightGBM,…) Prediction with models interpretation