Analyzing and Interpreting Convolutional Neural Networks in NLP
Convolutional neural networks have been successfully applied to various NLP tasks. However, it is not obvious whether they model different linguistic patterns such as negation, intensification, and clause compositionality to help the decision-making process. In this paper, we apply visualization techniques to observe how the model can capture different linguistic features and how these features can affect the performance of the model. Later on, we try to identify the model errors and their sources. We believe that interpreting CNNs is the first step to understand the underlying semantic features which can raise awareness to further improve the performance and explainability of CNN models.
WikiHow: A Large Scale Text Summarization Dataset
Sequence-to-sequence models have recently gained the state of the art performance in summarization. However, not too many large-scale high-quality datasets are available and almost all the available ones are mainly news articles with specific writing style. Moreover, abstractive human-style systems involving description of the content at a deeper level require data with higher levels of abstraction. In this paper, we present WikiHow, a dataset of more than 230,000 article and summary pairs extracted and constructed from an online knowledge base written by different human authors. The articles span a wide range of topics and therefore represent high diversity styles. We evaluate the performance of the existing methods on WikiHow to present its challenges and set some baselines to further improve it.
Data Motif-based Proxy Benchmarks for Big Data and AI Workloads
A Stacked Autoencoder Neural Network based Automated Feature Extraction Method for Anomaly detection in On-line Condition Monitoring
Condition monitoring is one of the routine tasks in all major process industries. The mechanical parts such as a motor, gear, bearings are the major components of a process industry and any fault in them may cause a total shutdown of the whole process, which may result in serious losses. Therefore, it is very crucial to predict any approaching defects before its occurrence. Several methods exist for this purpose and many research are being carried out for better and efficient models. However, most of them are based on the processing of raw sensor signals, which is tedious and expensive. Recently, there has been an increase in the feature based condition monitoring, where only the useful features are extracted from the raw signals and interpreted for the prediction of the fault. Most of these are handcrafted features, where these are manually obtained based on the nature of the raw data. This of course requires the prior knowledge of the nature of data and related processes. This limits the feature extraction process. However, recent development in the autoencoder based feature extraction method provides an alternative to the traditional handcrafted approaches; however, they have mostly been confined in the area of image and audio processing. In this work, we have developed an automated feature extraction method for on-line condition monitoring based on the stack of the traditional autoencoder and an on-line sequential extreme learning machine(OSELM) network. The performance of this method is comparable to that of the traditional feature extraction approaches. The method can achieve 100% detection accuracy for determining the bearing health states of NASA bearing dataset. The simple design of this method is promising for the easy hardware implementation of Internet of Things(IoT) based prognostics solutions.
Revisiting Distributional Correspondence Indexing: A Python Reimplementation and New Experiments
A Model Parallel Proximal Stochastic Gradient Algorithm for Partially Asynchronous Systems
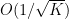


On Extensions of CLEVER: A Neural Network Robustness Evaluation Algorithm
CLEVER (Cross-Lipschitz Extreme Value for nEtwork Robustness) is an Extreme Value Theory (EVT) based robustness score for large-scale deep neural networks (DNNs). In this paper, we propose two extensions on this robustness score. First, we provide a new formal robustness guarantee for classifier functions that are twice differentiable. We apply extreme value theory on the new formal robustness guarantee and the estimated robustness is called second-order CLEVER score. Second, we discuss how to handle gradient masking, a common defensive technique, using CLEVER with Backward Pass Differentiable Approximation (BPDA). With BPDA applied, CLEVER can evaluate the intrinsic robustness of neural networks of a broader class — networks with non-differentiable input transformations. We demonstrate the effectiveness of CLEVER with BPDA in experiments on a 121-layer Densenet model trained on the ImageNet dataset.
Taking Advantage of Multitask Learning for Fair Classification
A central goal of algorithmic fairness is to reduce bias in automated decision making. An unavoidable tension exists between accuracy gains obtained by using sensitive information (e.g., gender or ethnic group) as part of a statistical model, and any commitment to protect these characteristics. Often, due to biases present in the data, using the sensitive information in the functional form of a classifier improves classification accuracy. In this paper we show how it is possible to get the best of both worlds: optimize model accuracy and fairness without explicitly using the sensitive feature in the functional form of the model, thereby treating different individuals equally. Our method is based on two key ideas. On the one hand, we propose to use Multitask Learning (MTL), enhanced with fairness constraints, to jointly learn group specific classifiers that leverage information between sensitive groups. On the other hand, since learning group specific models might not be permitted, we propose to first predict the sensitive features by any learning method and then to use the predicted sensitive feature to train MTL with fairness constraints. This enables us to tackle fairness with a three-pronged approach, that is, by increasing accuracy on each group, enforcing measures of fairness during training, and protecting sensitive information during testing. Experimental results on two real datasets support our proposal, showing substantial improvements in both accuracy and fairness.
Understanding Deep Convolutional Networks through Gestalt Theory
The superior performance of deep convolutional networks over high-dimensional problems have made them very popular for several applications. Despite their wide adoption, their underlying mechanisms still remain unclear with their improvement procedures still relying mainly on a trial and error process. We introduce a novel sensitivity analysis based on the Gestalt theory for giving insights into the classifier function and intermediate layers. Since Gestalt psychology stipulates that perception can be a product of complex interactions among several elements, we perform an ablation study based on this concept to discover which principles and image context significantly contribute in the network classification. Our results reveal that ConvNets follow most of the visual cortical perceptual mechanisms defined by the Gestalt principles at several levels. The proposed framework stimulates specific feature maps in classification problems and reveal important network attributes that can produce more explainable network models.
Safe Reinforcement Learning with Model Uncertainty Estimates
Many current autonomous systems are being designed with a strong reliance on black box predictions from deep neural networks (DNNs). However, DNNs tend to be overconfident in predictions on unseen data and can give unpredictable results for far-from-distribution test data. The importance of predictions that are robust to this distributional shift is evident for safety-critical applications, such as collision avoidance around pedestrians. Measures of model uncertainty can be used to identify unseen data, but the state-of-the-art extraction methods such as Bayesian neural networks are mostly intractable to compute. This paper uses MC-Dropout and Bootstrapping to give computationally tractable and parallelizable uncertainty estimates. The methods are embedded in a Safe Reinforcement Learning framework to form uncertainty-aware navigation around pedestrians. The result is a collision avoidance policy that \textit{knows what it does not know} and cautiously avoids pedestrians that exhibit unseen behavior. The policy is demonstrated in simulation to be more robust to novel observations and take safer actions than an uncertainty-unaware baseline.
The Ocean Tensor Package
Matrix and tensor operations form the basis of a wide range of fields and applications, and in many cases constitute a substantial part of the overall computational complexity. The ability of general-purpose GPUs to speed up many of these operations and enable others has resulted in a widespread adaptation of these devices. In order for tensor operations to take full advantage of the computational power, specialized software is required, and currently there exist several packages (predominantly in the area of deep learning) that incorporate tensor operations on both CPU and GPU. Nevertheless, a stand-alone framework that supports general tensor operations is still missing. In this paper we fill this gap and propose the Ocean Tensor Library: a modular tensor-support package that is designed to serve as a foundational layer for applications that require dense tensor operations on a variety of device types. The API is carefully designed to be powerful, extensible, and at the same time easy to use. The package is available as open source.
MMLSpark: Unifying Machine Learning Ecosystems at Massive Scales
We introduce Microsoft Machine Learning for Apache Spark (MMLSpark), an ecosystem of enhancements that expand the Apache Spark distributed computing library to tackle problems in Deep Learning, Micro-Service Orchestration, Gradient Boosting, Model Interpretability, and other areas of modern computation. Furthermore, we present a novel system called Spark Serving that allows users to run any Apache Spark program as a distributed, sub-millisecond latency web service backed by their existing Spark Cluster. All MMLSpark contributions have the same API to enable simple composition across frameworks and usage across batch, streaming, and RESTful web serving scenarios on static, elastic, or serverless clusters. We showcase MMLSpark by creating a method for deep object detection capable of learning without human labeled data and demonstrate its effectiveness for Snow Leopard conservation.
BCR-Net: a neural network based on the nonstandard wavelet form
This paper proposes a novel neural network architecture inspired by the nonstandard form proposed by Beylkin, Coifman, and Rokhlin in [Communications on Pure and Applied Mathematics, 44(2), 141-183]. The nonstandard form is a highly effective wavelet-based compression scheme for linear integral operators. In this work, we first represent the matrix-vector product algorithm of the nonstandard form as a linear neural network where every scale of the multiresolution computation is carried out by a locally connected linear sub-network. In order to address nonlinear problems, we propose an extension, called BCR-Net, by replacing each linear sub-network with a deeper and more powerful nonlinear one. Numerical results demonstrate the efficiency of the new architecture by approximating nonlinear maps that arise in homogenization theory and stochastic computation.
Property Graph Type System and Data Definition Language
Property graph manages data by vertices and edges. Each vertex and edge can have a property map, storing ad hoc attribute and its value. Label can be attached to vertices and edges to group them. While this schema-less methodology is very flexible for data evolvement and for managing explosive graph element, it has two shortcomings– 1) data dependency 2) less compression. Both problems can be solved by a schema based approach. In this paper, a type system used to model property graph is defined. Based on the type system, the associated data definition language (DDL) is proposed.
Attribute-aware Collaborative Filtering: Survey and Classification
Attribute-aware CF models aims at rating prediction given not only the historical rating from users to items, but also the information associated with users (e.g. age), items (e.g. price), or even ratings (e.g. rating time). This paper surveys works in the past decade developing attribute-aware CF systems, and discovered that mathematically they can be classified into four different categories. We provide the readers not only the high level mathematical interpretation of the existing works in this area but also the mathematical insight for each category of models. Finally we provide in-depth experiment results comparing the effectiveness of the major works in each category.
The Frontiers of Fairness in Machine Learning
The last few years have seen an explosion of academic and popular interest in algorithmic fairness. Despite this interest and the volume and velocity of work that has been produced recently, the fundamental science of fairness in machine learning is still in a nascent state. In March 2018, we convened a group of experts as part of a CCC visioning workshop to assess the state of the field, and distill the most promising research directions going forward. This report summarizes the findings of that workshop. Along the way, it surveys recent theoretical work in the field and points towards promising directions for research.
Autonomous Self-Explanation of Behavior for Interactive Reinforcement Learning Agents
In cooperation, the workers must know how co-workers behave. However, an agent’s policy, which is embedded in a statistical machine learning model, is hard to understand, and requires much time and knowledge to comprehend. Therefore, it is difficult for people to predict the behavior of machine learning robots, which makes Human Robot Cooperation challenging. In this paper, we propose Instruction-based Behavior Explanation (IBE), a method to explain an autonomous agent’s future behavior. In IBE, an agent can autonomously acquire the expressions to explain its own behavior by reusing the instructions given by a human expert to accelerate the learning of the agent’s policy. IBE also enables a developmental agent, whose policy may change during the cooperation, to explain its own behavior with sufficient time granularity.
Enriched Interpretation
The theory introduced, presented and developed in this paper, is concerned with an enriched extension of the theory of Rough Sets pioneered by Zdzislaw Pawlak. The enrichment discussed here is in the sense of valuated categories as developed by F.W. Lawvere. This paper relates Rough Sets to an abstraction of the theory of Fuzzy Sets pioneered by Lotfi Zadeh, and provides a natural foundation for ‘soft computation’. To paraphrase Lotfi Zadeh, the impetus for the transition from a hard theory to a soft theory derives from the fact that both the generality of a theory and its applicability to real-world problems are substantially enhanced by replacing various hard concepts with their soft counterparts. Here we discuss the corresponding enriched notions for indiscernibility, subsets, upper/lower approximations, and rough sets. Throughout, we indicate linkages with the theory of Formal Concept Analysis pioneered by Rudolf Wille. We pay particular attention to the all-important notion of a ‘linguistic variable’ – developing its enriched extension, comparing it with the notion of conceptual scale from Formal Concept Analysis, and discussing the pragmatic issues of its creation and use in the interpretation of data. These pragmatic issues are exemplified by the discovery, conceptual analysis, interpretation, and categorization of networked information resources in WAVE, the Web Analysis and Visualization Environment currently being developed for the management and interpretation of the universe of resource information distributed over the World-Wide Web.
pair2vec: Compositional Word-Pair Embeddings for Cross-Sentence Inference
Reasoning about implied relationships (e.g. paraphrastic, common sense, encyclopedic) between pairs of words is crucial for many cross-sentence inference problems. This paper proposes new methods for learning and using embeddings of word pairs that implicitly represent background knowledge about such relationships. Our pairwise embeddings are computed as a compositional function of each word’s representation, which is learned by maximizing the pointwise mutual information (PMI) with the contexts in which the the two words co-occur. We add these representations to the cross-sentence attention layer of existing inference models (e.g. BiDAF for QA, ESIM for NLI), instead of extending or replacing existing word embeddings. Experiments show a gain of 2.72% on the recently released SQuAD 2.0 and 1.3% on MultiNLI. Our representations also aid in better generalization with gains of around 6-7% on adversarial SQuAD datasets, and 8.8% on the adversarial entailment test set by Glockner et al.
High-dimensional Two-sample Precision Matrices Test: An Adaptive Approach through Multiplier Bootstrap
Precision matrix, which is the inverse of covariance matrix, plays an important role in statistics, as it captures the partial correlation between variables. Testing the equality of two precision matrices in high dimensional setting is a very challenging but meaningful problem, especially in the differential network modelling. To our best knowledge, existing test is only powerful for sparse alternative patterns where two precision matrices differ in a small number of elements. In this paper we propose a data-adaptive test which is powerful against either dense or sparse alternatives. Multiplier bootstrap approach is utilized to approximate the limiting distribution of the test statistic. Theoretical properties including asymptotic size and power of the test are investigated. Simulation study verifies that the data-adaptive test performs well under various alternative scenarios. The practical usefulness of the test is illustrated by applying it to a gene expression data set associated with lung cancer.
CNNPred: CNN-based stock market prediction using several data sources
Feature extraction from financial data is one of the most important problems in market prediction domain for which many approaches have been suggested. Among other modern tools, convolutional neural networks (CNN) have recently been applied for automatic feature selection and market prediction. However, in experiments reported so far, less attention has been paid to the correlation among different markets as a possible source of information for extracting features. In this paper, we suggest a CNN-based framework with specially designed CNNs, that can be applied on a collection of data from a variety of sources, including different markets, in order to extract features for predicting the future of those markets. The suggested framework has been applied for predicting the next day’s direction of movement for the indices of S&P 500, NASDAQ, DJI, NYSE, and RUSSELL markets based on various sets of initial features. The evaluations show a significant improvement in prediction’s performance compared to the state of the art baseline algorithms.
Teaching Inverse Reinforcement Learners via Features and Demonstrations
Learning near-optimal behaviour from an expert’s demonstrations typically relies on the assumption that the learner knows the features that the true reward function depends on. In this paper, we study the problem of learning from demonstrations in the setting where this is not the case, i.e., where there is a mismatch between the worldviews of the learner and the expert. We introduce a natural quantity, the teaching risk, which measures the potential suboptimality of policies that look optimal to the learner in this setting. We show that bounds on the teaching risk guarantee that the learner is able to find a near-optimal policy using standard algorithms based on inverse reinforcement learning. Based on these findings, we suggest a teaching scheme in which the expert can decrease the teaching risk by updating the learner’s worldview, and thus ultimately enable her to find a near-optimal policy.
Training Dynamic Exponential Family Models with Causal and Lateral Dependencies for Generalized Neuromorphic Computing
Neuromorphic hardware platforms, such as Intel’s Loihi chip, support the implementation of Spiking Neural Networks (SNNs) as an energy-efficient alternative to Artificial Neural Networks (ANNs). SNNs are networks of neurons with internal analogue dynamics that communicate by means of binary time series. In this work, a probabilistic model is introduced for a generalized set-up in which the synaptic time series can take values in an arbitrary alphabet and are characterized by both causal and instantaneous statistical dependencies. The model, which can be considered as an extension of exponential family harmoniums to time series, is introduced by means of a hybrid directed-undirected graphical representation. Furthermore, distributed learning rules are derived for maximum likelihood and Bayesian criteria under the assumption of fully observed time series in the training set.
Private Information Retrieval over Networks
In this paper, the problem of providing privacy to users requesting data over a network from a distributed storage system (DSS) is considered. The DSS, which is considered as the multi-terminal destination of the network from the user’s perspective, is encoded by a maximum rank distance (MRD) code to store the data on these multiple servers. A private information retrieval (PIR) scheme ensures that a user can request a file without revealing any information on which file is being requested to any of the servers. In this paper, a novel PIR scheme is proposed, allowing the user to recover a file from a storage system with low communication cost, while allowing some servers in the system to collude in the quest of revealing the identity of the requested file. The network is modeled as in random linear network coding (RLNC), i.e., all nodes of the network forward random (unknown) linear combinations of incoming packets. Both error-free and erroneous RLNC networks are considered.
MS-BACO: A new Model Selection algorithm using Binary Ant Colony Optimization for neural complexity and error reduction
Stabilizing the complexity of Feedforward Neural Networks (FNNs) for the given approximation task can be managed by defining an appropriate model magnitude which is also greatly correlated with the generalization quality and computational efficiency. However, deciding on the right level of model complexity can be highly challenging in FNN applications. In this paper, a new Model Selection algorithm using Binary Ant Colony Optimization (MS-BACO) is proposed in order to achieve the optimal FNN model in terms of neural complexity and cross-entropy error. MS-BACO is a meta-heuristic algorithm that treats the problem as a combinatorial optimization problem. By quantifying both the amount of correlation exists among hidden neurons and the sensitivity of the FNN output to the hidden neurons using a sample-based sensitivity analysis method called, extended Fourier amplitude sensitivity test, the algorithm mostly tends to select the FNN model containing hidden neurons with most distinct hyperplanes and high contribution percentage. Performance of the proposed algorithm with three different designs of heuristic information is investigated. Comparison of the findings verifies that the newly introduced algorithm is able to provide more compact and accurate FNN model.
Spatio-Temporal Correlation Analysis of Online Monitoring Data for Anomaly Detection in Distribution Networks
The online monitoring data in distribution networks contain rich information on the running states of the system. By leveraging the data, this paper proposes a spatio-temporal correlation analysis approach for anomaly detection in distribution networks. First, spatio-temporal matrix for each feeder in the distribution network is formulated and the spectrum of its covariance matrix is analyzed. The spectrum is complex and exhibits two aspects: 1) bulk, which arises from random noise or fluctuations and 2) spikes, which represents factors caused by anomaly signals or fault disturbances. Then by connecting the estimation of the number of factors to the limiting empirical spectral density of the covariance matrix of the modeled residual, the anomaly detection problem in distribution networks is formulated as the estimation of spatio-temporal parameters, during which free random variable techniques are used. Furthermore, as for the estimated factors, we define and calculate a statistical magnitude for them as the spatial indicator to indicate the system state. Simultaneously, we use the autoregressive rate to measure the varieties of the temporal correlations of the data for tracking the system movement. Our approach is purely data driven and it is capable of discovering the anomalies in an early phase by exploring the variations of the spatio-temporal correlations of the data, which makes it practical for real applications. Case studies on the synthetic data verify the effectiveness of our approach and analyze the implications of the spatio-temporal parameters. Through the real-world online monitoring data, we further validate our approach and compare it with another spectrum analysis approach using the Marchenko-Pastur law. The results show that our approach is more accurate and it can serve as a primitive for analyzing the spatio-temporal data in a distribution network.
A Data-driven Prognostic Architecture for Online Monitoring of Hard Disks Using Deep LSTM Networks
With the advent of pervasive cloud computing technologies, service reliability and availability are becoming major concerns,especially as we start to integrate cyber-physical systems with the cloud networks. A number of smart and connected community systems such as emergency response systems utilize cloud networks to analyze real-time data streams and provide context-sensitive decision support.Improving overall system reliability requires us to study all the aspects of the end-to-end of this distributed system,including the backend data servers. In this paper, we describe a bi-layered prognostic architecture for predicting the Remaining Useful Life (RUL) of components of backend servers,especially those that are subjected to degradation. We show that our architecture is especially good at predicting the remaining useful life of hard disks. A Deep LSTM Network is used as the backbone of this fast, data-driven decision framework and dynamically captures the pattern of the incoming data. In the article, we discuss the architecture of the neural network and describe the mechanisms to choose the various hyper-parameters. We describe the challenges faced in extracting effective training sets from highly unorganized and class-imbalanced big data and establish methods for online predictions with extensive data pre-processing, feature extraction and validation through test sets with unknown remaining useful lives of the hard disks. Our algorithm performs especially well in predicting RUL near the critical zone of a device approaching failure.The proposed architecture is able to predict whether a disk is going to fail in next ten days with an average precision of 0.8435.In future, we will extend this architecture to learn and predict the RUL of the edge devices in the end-to-end distributed systems of smart communities, taking into consideration context-sensitive external features such as weather.
RLgraph: Flexible Computation Graphs for Deep Reinforcement Learning
Reinforcement learning (RL) tasks are challenging to implement, execute and test due to algorithmic instability, hyper-parameter sensitivity, and heterogeneous distributed communication patterns. We argue for the separation of logical component composition, backend graph definition, and distributed execution. To this end, we introduce RLgraph, a library for designing and executing high performance RL computation graphs in both static graph and define-by-run paradigms. The resulting implementations yield high performance across different deep learning frameworks and distributed backends.
Challenge AI Mind: A Crowd System for Proactive AI Testing
Artificial Intelligence (AI) has burrowed into our lives in various aspects; however, without appropriate testing, deployed AI systems are often being criticized to fail in critical and embarrassing cases. Existing testing approaches mainly depend on fixed and pre-defined datasets, providing a limited testing coverage. In this paper, we propose the concept of proactive testing to dynamically generate testing data and evaluate the performance of AI systems. We further introduce Challenge.AI, a new crowd system that features the integration of crowdsourcing and machine learning techniques in the process of error generation, error validation, error categorization, and error analysis. We present experiences and insights into a participatory design with AI developers. The evaluation shows that the crowd workflow is more effective with the help of machine learning techniques. AI developers found that our system can help them discover unknown errors made by the AI models, and engage in the process of proactive testing.
Stochastic Gradient MCMC for State Space Models
State space models (SSMs) are a flexible approach to modeling complex time series. However, inference in SSMs is often computationally prohibitive for long time series. Stochastic gradient MCMC (SGMCMC) is a popular method for scalable Bayesian inference for large independent data. Unfortunately when applied to dependent data, such as in SSMs, SGMCMC’s stochastic gradient estimates are biased as they break crucial temporal dependencies. To alleviate this, we propose stochastic gradient estimators that control this bias by performing additional computation in a `buffer’ to reduce breaking dependencies. Furthermore, we derive error bounds for this bias and show a geometric decay under mild conditions. Using these estimators, we develop novel SGMCMC samplers for discrete, continuous and mixed-type SSMs. Our experiments on real and synthetic data demonstrate the effectiveness of our SGMCMC algorithms compared to batch MCMC, allowing us to scale inference to long time series with millions of time points.
A Parametric Time Frequency-Conditional Granger Causality Method Using Ultra-regularized Orthogonal Least Squares and Multiwavelets for Dynamic Connectivity Analysis in EEGs
Objective: This study proposes a new parametric TF (time frequency) CGC (conditional Granger causality) method for high precision connectivity analysis over time and frequency in multivariate coupling nonstationary systems, and applies it to scalp and source EEG signals to reveal dynamic interaction patterns in oscillatory neocortical sensorimotor networks. Methods: The Geweke spectral measure is combined with the TVARX (time varying autoregressive with exogenous input) modelling approach, which uses multiwavelets and ultra regularized orthogonal least squares (UROLS) algorithm aided by APRESS (adjustable prediction error sum of squares), to obtain high resolution time varying CGC representations. The UROLS APRESS algorithm, which adopts both the regularization technique and the ultra least squares criterion to measure not only the signal data themselves but also the weak derivatives of them, is a novel powerful method in constructing time varying models with good generalization performance, and can accurately track smooth and fast changing causalities. The generalized measurement based on CGC decomposition is able to eliminate indirect influences in multivariate systems. Results: The proposed method is validated on two simulations and then applied to multichannel motor imagery (MI) EEG signals at scalp and source level, where the predicted distributions are well recovered with high TF precision, and the detected connectivity patterns of MI EEG data are physiologically and anatomically interpretable and yield new insights into the dynamical organization of oscillatory cortical networks. Conclusion: Experimental results confirm the effectiveness of the proposed TF CGC method in tracking rapidly varying causalities of EEG based oscillatory networks. Significance: The novel TF CGC method is expected to provide important information of neural mechanisms of perception and cognition.
Assessing the Stability of Interpretable Models
Interpretable classification models are built with the purpose of providing a comprehensible description of the decision logic to an external oversight agent. When considered in isolation, a decision tree, a set of classification rules, or a linear model, are widely recognized as human-interpretable. However, such models are generated as part of a larger analytical process, which, in particular, comprises data collection and filtering. Selection bias in data collection or in data pre-processing may affect the model learned. Although model induction algorithms are designed to learn to generalize, they pursue optimization of predictive accuracy. It remains unclear how interpretability is instead impacted. We conduct an experimental analysis to investigate whether interpretable models are able to cope with data selection bias as far as interpretability is concerned.
biggy: An Implementation of Unified Framework for Big Data Management System
Various tools, softwares and systems are proposed and implemented to tackle the challenges in big data on different emphases, e.g., data analysis, data transaction, data query, data storage, data visualization, data privacy. In this paper, we propose datar, a new prospective and unified framework for Big Data Management System (BDMS) from the point of system architecture by leveraging ideas from mainstream computer structure. We introduce five key components of datar by reviewing the current status of BDMS. Datar features with configuration chain of pluggable engines, automatic dataflow on job pipelines, intelligent self-driving system management and interactive user interfaces. Moreover, we present biggy as an implementation of datar with manipulation details demonstrated by four running examples. Evaluations on efficiency and scalability are carried out to show the performance. Our work argues that the envisioned datar is a feasible solution to the unified framework of BDMS, which can manage big data pluggablly, automatically and intelligently with specific functionalities, where specific functionalities refer to input, storage, computation, control and output of big data.
• Strengths and Weaknesses of Recurrent Quantification Analysis in the context of Human-Humanoid Interaction• Classification of normal/abnormal heart sound recordings based on multi-domain features and back propagation neural network• Nonlinear Mapping and Distance Geometry• Infinite Factorial Finite State Machine for Blind Multiuser Channel Estimation• Improving Annotation for 3D Pose Dataset of Fine-Grained Object Categories• On tradeoffs between treatment time and plan quality of volumetric-modulated arc therapy with sliding-window delivery• Non-central limit theorems for functionals of random fields on hypersurfaces• A database linking piano and orchestral MIDI scores with application to automatic projective orchestration• Real-time Neural-based Input Method• CNN inference acceleration using dictionary of centroids• Gradient target propagation• Autonomous Functional Locomotion in a Tendon-Driven Limb via Limited Experience• Duality of Graph Invariants• Population and Empirical PR Curves for Assessment of Ranking Algorithms• Fast and Robust Multiple ColorChecker Detection using Deep Convolutional Neural Networks• Optimizing Segmentation Granularity for Neural Machine Translation• Intrinsic Social Motivation via Causal Influence in Multi-Agent RL• On the roots of the subtree polynomial• Extremal Problems Related to the Cardinality Redundance of Graphs• Using tropical optimization techniques in bi-criteria decision problems• Graphs of gonality 3• A generalization of Strassen’s Positivstellensatz and its application to large deviation theory• Parity Decision Tree Complexity is Greater Than Granularity• Limits on All Known (and Some Unknown) Approaches to Matrix Multiplication• Matroidal representations of groups• Using Machine Learning to reduce the energy wasted in Volunteer Computing Environments• Subset Scanning Over Neural Network Activations• A neural network to classify metaphorical violence on cable news• Optimization of Molecules via Deep Reinforcement Learning• Lightweight Convolutional Approaches to Reading Comprehension on SQuAD• Direct and Binary Direct Bases for One-set Updates of a Closure System• Corrective dispatch of uncertain energy resources using chance-constrained receding horizon control• AudioAR: Audio-Based Activity Recognition with Large-Scale Acoustic Embeddings from YouTube Videos• The total variation distance between high-dimensional Gaussians• pioNER: Datasets and Baselines for Armenian Named Entity Recognition• An Approach to Energy Efficiency in a Multi-Hop Network Control System through a Trade-Off between H-inf Norm and Global Number of Transmissions• Synscapes: A Photorealistic Synthetic Dataset for Street Scene Parsing• Mobile Sound Recognition for the Deaf and Hard of Hearing• Stability conditions for a decentralised medium access algorithm: single- and multi-hop networks• Estimation of a functional single index model with dependent errors and unknown error density• Learning Personas from Dialogue with Attentive Memory Networks• Testing Randomness in Quantum Mechanics• Deep Reinforcement Learning for Six Degree-of-Freedom Planetary Powered Descent and Landing• SL$^2$MF: Predicting Synthetic Lethality in Human Cancers via Logistic Matrix Factorization• Condition Number Analysis of Logistic Regression, and its Implications for Standard First-Order Solution Methods• Learning Material-Aware Local Descriptors for 3D Shapes• Named Entity Recognition on Twitter for Turkish using Semi-supervised Learning with Word Embeddings• Learning Koopman eigenfunctions for prediction and control: the transient case• A Perfect One-Factorisation of $K_{56}$• Improving Multilingual Semantic Textual Similarity with Shared Sentence Encoder for Low-resource Languages• Quantifying the Burden of Exploration and the Unfairness of Free Riding• Temporal Proximity induces Attributes Similarity• Renormalized Normalized Maximum Likelihood and Three-Part Code Criteria For Learning Gaussian Networks• Learning Models with Uniform Performance via Distributionally Robust Optimization• Left Ventricle Segmentation via Optical-Flow-Net from Short-axis Cine MRI: Preserving the Temporal Coherence of Cardiac Motion• Distributed L1-state-and-fault estimation for Multi-agent systems• Design of robust H_inf fuzzy output feedback controller for affine nonlinear systems: Fuzzy Lyapunov function approach• Transitions in spatial networks• MEMC-Net: Motion Estimation and Motion Compensation Driven Neural Network for Video Interpolation and Enhancement• Sequential Context Encoding for Duplicate Removal• Image Inpainting via Generative Multi-column Convolutional Neural Networks• Total mixed domination in graphs• Improved Techniques for GAN based Facial Inpainting• Marginal models with individual-specific effects for the analysis of longitudinal bipartite networks• A Unified Labeling Approach by Pooling Diverse Datasets for Entity Typing• A defensive marginal particle filtering method for data assimilation• Separation profiles of graphs of fractals• Shapley-Snow kernels in zero-sum stochastic games• Proportionality Degree of Multiwinner Rules• Hierarchical Text Generation using an Outline• Asymptotic efficiency in the Autoregressive process driven by a stationary Gaussian noise• Investigating Voice as a Biomarker for leucine-rich repeat kinase 2-Associated Parkinson’s Disease• Modeling Composite Labels for Neural Morphological Tagging• Wasserstein-based methods for convergence complexity analysis of MCMC with application to Albert and Chib’s algorithm• Data-Driven Tight Frame for Cryo-EM Image Denoising and Conformational Classification• MinJoin: Efficient Edit Similarity Joins via Local Hash Minimums• Abstractive Summarization Using Attentive Neural Techniques• Simple Games versus Weighted Voting Games: Bounding the Critical Threshold Value• An approximation scheme for variational inequalities with convex and coercive Hamiltonians• Corresponding Supine and Prone Colon Visualization Using Eigenfunction Analysis and Fold Modeling• Hybrid-MST: A Hybrid Active Sampling Strategy for Pairwise Preference Aggregation• The Gelin-Cesàro identity in some third-order Jacobsthal sequences• Some Coxeter Groups in Reversible and Quantum Compuation• A Polynomial Time MCMC Method for Sampling from Continuous DPPs• 3D tamed Navier-Stokes equations driven by multiplicative Lévy noise: Existence, uniqueness and large deviations• Learning-based Application-Agnostic 3D NoC Design for Heterogeneous Manycore Systems• Joint Receiver Design for Internet of Things• Pose consensus based on dual quaternion algebra with application to decentralized formation control of mobile manipulators• Conflict complexity is lower bounded by block sensitivity• Sleep Arousal Detection from Polysomnography using the Scattering Transform and Recurrent Neural Networks• A Regressive Convolution Neural network and Support Vector Regression Model for Electricity Consumption Forecasting• Optimal Transmit Antenna Selection Algorithm in Massive MIMOME Channels• Automated identification of hookahs (waterpipes) on Instagram: an application in feature extraction using Convolutional Neural Network and Support Vector Machine classification• Diagrammatics for Kazhdan-Lusztig R-polynomials• Catching Loosely Synchronized Behavior in Face of Camouflage• Electricity consumption forecasting method based on MPSO-BP neural network model• Optimal Rotational Load Shedding via Bilinear Integer Programming• To Compress, or Not to Compress: Characterizing Deep Learning Model Compression for Embedded Inference• Dynamic Average Diffusion with randomized Coordinate Updates• On the dimension of Bernoulli convolutions for all transcendental parameters• Analog-to-digital conversion revolutionized by deep learning• Understanding the Acceleration Phenomenon via High-Resolution Differential Equations• Vertex-primitive s-arc-transitive digraphs of alternating and symmetric groups• Label Noise Filtering Techniques to Improve Monotonic Classification• Multiple Scaled Contaminated Normal Distribution and Its Application in Clustering• On 2-colored graphs and partitions of boxes• Decoding of Non-Binary LDPC Codes Using the Information Bottleneck Method• On-line parameter and state estimation of an air handling unit model: experimental results using the modulating function method• Learning Spectral Transform Network on 3D Surface for Non-rigid Shape Analysis• BCWS: Bilingual Contextual Word Similarity• Runtime Concurrency Control and Operation Scheduling for High Performance Neural Network Training• Miscellaneous applications of certain minimax theorems II• On orthogonal matrices with zero diagonal• Semigroup-valued metric spaces• Extremal Betti numbers of edge ideals
Like this:
Like Loading…
Related