Introduction
I introduced MCHT two weeks ago and presented it as a package for Monte Carlo and boostrap hypothesis testing. Last week, I delved into important technical details and showed how to make self-contained MCHTest objects that don’t suffer side effects from changes in the global namespace. In this article I show how to perform maximized Monte Carlo hypothesis testing using MCHT, as described in [1].
Maximized Monte Carlo Hypothesis Testing
The usual procedure for Monte Carlo hypothesis testing is:
- Compute a test statistic for the data on which you wish to test a hypothesis
Generate 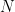
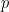
Monte Carlo tests often make strong distributional assumptions, such as what distribution generated the dataset being tested, but when those assumptions hold, they are exact tests (see [2]). They are not as powerful as if we had the exact distribution of the test statistic under those assumptions but the power increases with
However, the procedure outlined above does not allow for nuisance parameters (parameters that are not the subject of interest but whose values are needed in order to conduct inference). In the introductory blog post, while one may view the population standard deviation 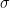
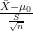
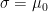
That said, nuisance parameters can still appear when we need to perform inference. Suppose, for example, that our data follows a Weibull distribution, denoted by 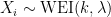
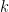
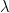


We can use the generalized likelihood ratio test to form a test statistic (which I won’t repeat hear but does appear in the code below). While Wilks’ theorem tells us about the asymptotic distribution of the test statistic, it says nothing about the exact distribution of the test statistic at a particular sample size, and it’s not given that the test statistic is pivotal and thus independent of the value of nuisance parameters under the null hypothesis (the nuisance parameter, in this case, being the shape parameter
What then can we do? A bootstrap test would estimate the value of the nuisance parameter under the null hypothesis and use that estimate as the actual value when generating new, simulated test statistics. Bootstrap tests, however, are not exact tests (see [2]) and we’ve decided that we want a test with stronger guarantees.
[1] introduced the maximized Monte Carlo (MMC) test, which proceeds as described below:
- Compute the test statistic from the data.
Generate
[1] showed that this procedure yields
MMC is intuitive and compelling, and the theoretical guarantee gives us confidence in our conclusions, but it’s not a panacea. First, the optimization procedure is costly in work and time. Second (and, in my opinion, the biggest problem), the procedure may be too conservative. There’s a strong chance that the procedure will find some values for nuisance parameters that yield a large
MMC in MCHT
Creating an implementation of MMC in R was my original goal in developing MCHT, and all that needs to be done to perform MMC is pass a value the nuisance_params parameter and an appropriate list to optim_control.
Let’s take the hypothesis test mentioned above and prepare to implement it using MCHT. I will be using fitdistrplus for maximum likelihood estimation, as required by the test statistic (see [4]).
The MCHTest() parameter nuisance_params accepts a character vector giving the names of nuisance parameters the distribution of the test statistic may depend upon, and those names must be among the arguments of the function passed to stat_gen; that function is expected to know how to handle those parameters. In this case, rand_gen will not be specified since by default it gives uniformly distributed random variables. It’s a well-known fact in probability that the inverse of the CDF of a random variable (which are the q functions in R) applied to a uniformly distributed random variable yields a random variable that follows the distribution prescribed by the CDF. Hence the use of qweibull() above, which is being applied to datasets of uniformly distributed random variables that are effectively fixed when stat_gen will be called. Then the test statistic computed will be computed from data that follows the scale parameter
The MCHTest object will then perform simulated annealing to choose the value of the nuisance parameter that maximizes the GenSA() function provided by the GenSA package (see [5]). GenSA() needs a description of what set of parameter values over which to optimize and there is no general method for choosing this, so MCHTest() will require that a list be passed to optim_control that effectively contains the parameters that will be passed to GenSA(). At minimum, this list must contain an upper and a lower element, each of which are numeric vectors with names exactly like the character vector passed to nuisance_params; these vectors specify the space GenSA() will search to find the optima. Other elements can be passed to control GenSA(), and I highly recommend reading the function’s documentation for more details.
There’s an additional parameter of MCHTest(), threshold_pval, that matters to the optimization. GenSA() will take many steps to make sure it reaches a good optimal value, perhaps taking too long. The authors of GenSA recommend specifying an additional terminating condition to speed up the process. threshold_pval will alter the threshold.stop parameter in the control list of optim_control so that the algorithm terminates when the estimated threshold_pval‘s value. Effectively, this means that we know that whatever the true
While giving threshold_pval a number less than 1 can help terminate the algorithm in the case of not rejecting the null hypothesis, the algorithm can still run for a long time if the test will eventually return a statistically significant result. For this reason, I recommend that optim_list contain a list called control and that the list should have a max.time element telling the algorithm the maximum running time (in seconds) it should have.
With all this in mind, we create the MCHTest object below:
Conclusion
The MMC procedure is intersting and I don’t think any package implements it to the level I have in MCHT. The power of the procedure itself concerns me, though. Fortunately, the package also supports bootstrap testing, which I will discuss next week.
References
-
J-M Dufour, Monte Carlo tests with nuisance parameters: A general approach to finite-sample inference and nonstandard asymptotics, Journal of Econometrics, vol. 133 no. 2 (2006) pp. 443-477
-
J. G. MacKinnon, Bootstrap hypothesis testing in Handbook of computational econometrics (2009) pp. 183-213
-
A. C. A. Hope, A simplified Monte Carlo test procedure, JRSSB, vol. 30 (1968) pp. 582-598
-
M. L. Delignette-Muller and C. Dulag, fitdistrplus: an R package for fitting distributions, J. Stat. Soft., vol. 64 no. 4 (2015)
-
Y. Xiang et. al., Generalized simulated annealing for global optimization: the GenSA package, R Journal, vol. 5 no. 1 (2013) pp. 13-28
Packt Publishing published a book for me entitled Hands-On Data Analysis with NumPy and Pandas, a book based on my video course Unpacking NumPy and Pandas. This book covers the basics of setting up a Python environment for data analysis with Anaconda, using Jupyter notebooks, and using NumPy and pandas. If you are starting out using Python for data analysis or know someone who is, please consider buying my book or at least spreading the word about it. You can buy the book directly or purchase a subscription to Mapt and read it there.
If you like my blog and would like to support it, spread the word (if not get a copy yourself)!
Related