DeFind: A Protege Plugin for Computing Concept Definitions in EL Ontologies
We introduce an extension to the Protege ontology editor, which allows for discovering concept definitions, which are not explicitly present in axioms, but are logically implied by an ontology. The plugin supports ontologies formulated in the Description Logic EL, which underpins the OWL 2 EL profile of the Web Ontology Language and despite its limited expressiveness captures most of the biomedical ontologies published on the Web. The developed tool allows to verify whether a concept can be defined using a vocabulary of interest specified by a user. In particular, it allows to decide whether some vocabulary items can be omitted in a formulation of a complex concept. The corresponding definitions are presented to the user and are provided with explanations generated by an ontology reasoner.
Parametrized Deep Q-Networks Learning: Reinforcement Learning with Discrete-Continuous Hybrid Action Space
Most existing deep reinforcement learning (DRL) frameworks consider either discrete action space or continuous action space solely. Motivated by applications in computer games, we consider the scenario with discrete-continuous hybrid action space. To handle hybrid action space, previous works either approximate the hybrid space by discretization, or relax it into a continuous set. In this paper, we propose a parametrized deep Q-network (P- DQN) framework for the hybrid action space without approximation or relaxation. Our algorithm combines the spirits of both DQN (dealing with discrete action space) and DDPG (dealing with continuous action space) by seamlessly integrating them. Empirical results on a simulation example, scoring a goal in simulated RoboCup soccer and the solo mode in game King of Glory (KOG) validate the efficiency and effectiveness of our method.
Temporal Convolutional Memory Networks for Remaining Useful Life Estimation of Industrial Machinery
Accurately estimating the remaining useful life (RUL) of industrial machinery is beneficial in many real-world applications. Estimation techniques have mainly utilized linear models or neural network based approaches with a focus on short term time dependencies. This paper introduces a system model that incorporates temporal convolutions with both long term and short term time dependencies. The proposed network learns salient features and complex temporal variations in sensor values, and predicts the RUL. A data augmentation method is used for increased accuracy. The proposed method is compared with several state-of-the-art algorithms on publicly available datasets. It demonstrates promising results, with superior results for datasets obtained from complex environments.
Building Dynamic Knowledge Graphs from Text using Machine Reading Comprehension
We propose a neural machine-reading model that constructs dynamic knowledge graphs from procedural text. It builds these graphs recurrently for each step of the described procedure, and uses them to track the evolving states of participant entities. We harness and extend a recently proposed machine reading comprehension (MRC) model to query for entity states, since these states are generally communicated in spans of text and MRC models perform well in extracting entity-centric spans. The explicit, structured, and evolving knowledge graph representations that our model constructs can be used in downstream question answering tasks to improve machine comprehension of text, as we demonstrate empirically. On two comprehension tasks from the recently proposed PROPARA dataset (Dalvi et al., 2018), our model achieves state-of-the-art results. We further show that our model is competitive on the RECIPES dataset (Kiddon et al., 2015), suggesting it may be generally applicable. We present some evidence that the model’s knowledge graphs help it to impose commonsense constraints on its predictions.
Faster k-Medoids Clustering: Improving the PAM, CLARA, and CLARANS Algorithms
Clustering non-Euclidean data is difficult, and one of the most used algorithms besides hierarchical clustering is the popular algorithm PAM, partitioning around medoids, also known as k-medoids. In Euclidean geometry the mean–as used in k-means–is a good estimator for the cluster center, but this does not hold for arbitrary dissimilarities. PAM uses the medoid instead, the object with the smallest dissimilarity to all others in the cluster. This notion of centrality can be used with any (dis-)similarity, and thus is of high relevance to many domains such as biology that require the use of Jaccard, Gower, or even more complex distances. A key issue with PAM is, however, its high run time cost. In this paper, we propose modifications to the PAM algorithm where at the cost of storing O(k) additional values, we can achieve an O(k)-fold speedup in the second (‘SWAP’) phase of the algorithm, but will still find the same results as the original PAM algorithm. If we slightly relax the choice of swaps performed (while retaining comparable quality), we can further accelerate the algorithm by performing up to k swaps in each iteration. We also show how the CLARA and CLARANS algorithms benefit from this modification. In experiments on real data with k=100, we observed a 200 fold speedup compared to the original PAM SWAP algorithm, making PAM applicable to larger data sets, and in particular to higher k.
Can evolution paths be explained by chance alone?
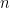

One-Shot PIR: Refinement and Lifting
We study a class of private information retrieval (PIR) methods that we call one-shot schemes. The intuition behind one-shot schemes is the following. The user’s query is regarded as a dot product of a query vector and the message vector (database) stored at multiple servers. Privacy, in an information theoretic sense, is then achieved by encrypting the query vector using a secure linear code, such as secret sharing. Several PIR schemes in the literature, in addition to novel ones constructed here, fall into this class. One-shot schemes provide an insightful link between PIR and data security against eavesdropping. However, their download rate is not optimal, i.e., they do not achieve the PIR capacity. Our main contribution is two transformations of one-shot schemes, which we call refining and lifting. We show that refining and lifting one-shot schemes gives capacity-achieving schemes for the cases when the PIR capacity is known. In the other cases, when the PIR capacity is still unknown, refining and lifting one-shot schemes gives the best download rate so far.
Estimating Information Flow in Neural Networks

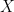

Unsupervised Neural Multi-document Abstractive Summarization
Abstractive summarization has been studied using neural sequence transduction methods with datasets of large, paired document-summary examples. However, such datasets are rare and the models trained from them do not generalize to other domains. Recently, some progress has been made in learning sequence-to-sequence mappings with only unpaired examples. In our work, we consider the setting where there are only documents and no summaries provided and propose an end-to-end, neural model architecture to perform unsupervised abstractive summarization. Our proposed model consists of an auto-encoder trained so that the mean of the representations of the input documents decodes to a reasonable summary. We consider variants of the proposed architecture and perform an ablation study to show the importance of specific components. We apply our model to the summarization of business and product reviews and show that the generated summaries are fluent, show relevancy in terms of word-overlap, representative of the average sentiment of the input documents, and are highly abstractive compared to baselines.
Explaining Black Boxes on Sequential Data using Weighted Automata
Understanding how a learned black box works is of crucial interest for the future of Machine Learning. In this paper, we pioneer the question of the global interpretability of learned black box models that assign numerical values to symbolic sequential data. To tackle that task, we propose a spectral algorithm for the extraction of weighted automata (WA) from such black boxes. This algorithm does not require the access to a dataset or to the inner representation of the black box: the inferred model can be obtained solely by querying the black box, feeding it with inputs and analyzing its outputs. Experiments using Recurrent Neural Networks (RNN) trained on a wide collection of 48 synthetic datasets and 2 real datasets show that the obtained approximation is of great quality.
Graph HyperNetworks for Neural Architecture Search
Neural architecture search (NAS) automatically finds the best task-specific neural network topology, outperforming many manual architecture designs. However, it can be prohibitively expensive as the search requires training thousands of different networks, while each can last for hours. In this work, we propose the Graph HyperNetwork (GHN) to amortize the search cost: given an architecture, it directly generates the weights by running inference on a graph neural network. GHNs model the topology of an architecture and therefore can predict network performance more accurately than regular hypernetworks and premature early stopping. To perform NAS, we randomly sample architectures and use the validation accuracy of networks with GHN generated weights as the surrogate search signal. GHNs are fast — they can search nearly 10 times faster than other random search methods on CIFAR-10 and ImageNet. GHNs can be further extended to the anytime prediction setting, where they have found networks with better speed-accuracy tradeoff than the state-of-the-art manual designs.
Measuring Swampiness: Quantifying Chaos in Large Heterogeneous Data Repositories
As scientific data repositories and filesystems grow in size and complexity, they become increasingly disorganized. The coupling of massive quantities of data with poor organization makes it challenging for scientists to locate and utilize relevant data, thus slowing the process of analyzing data of interest. To address these issues, we explore an automated clustering approach for quantifying the organization of data repositories. Our parallel pipeline processes heterogeneous filetypes (e.g., text and tabular data), automatically clusters files based on content and metadata similarities, and computes a novel ‘cleanliness’ score from the resulting clustering. We demonstrate the generation and accuracy of our cleanliness measure using both synthetic and real datasets, and conclude that it is more consistent than other potential cleanliness measures.
Mixture of Expert/Imitator Networks: Scalable Semi-supervised Learning Framework
The current success of deep neural networks (DNNs) in an increasingly broad range of tasks for the artificial intelligence strongly depends on the quality and quantity of labeled training data. In general, the scarcity of labeled data, which is often observed in many natural language processing tasks, is one of the most important issues to be addressed. Semi-supervised learning (SSL) is a promising approach to overcome this issue by incorporating a large amount of unlabeled data. In this paper, we propose a novel scalable method of SSL for text classification tasks. The unique property of our method, Mixture of Expert/Imitator Networks, is that imitator networks learn to ‘imitate’ the estimated label distribution of the expert network over the unlabeled data, which potentially contributes as a set of features for the classification. Our experiments demonstrate that the proposed method consistently improves the performance of several types of baseline DNNs. We also demonstrate that our method has the more data, better performance property with promising scalability to the unlabeled data.
Categorical Aspects of Parameter Learning
Parameter learning is the technique for obtaining the probabilistic parameters in conditional probability tables in Bayesian networks from tables with (observed) data — where it is assumed that the underlying graphical structure is known. There are basically two ways of doing so, referred to as maximal likelihood estimation (MLE) and as Bayesian learning. This paper provides a categorical analysis of these two techniques and describes them in terms of basic properties of the multiset monad M, the distribution monad D and the Giry monad G. In essence, learning is about the reltionships between multisets (used for counting) on the one hand and probability distributions on the other. These relationsips will be described as suitable natural transformations.
A Geometric Analysis of Time Series Leading to Information Encoding and a New Entropy Measure
A time series is uniquely represented by its geometric shape, which also carries information. A time series can be modelled as the trajectory of a particle moving in a force field with one degree of freedom. The force acting on the particle shapes the trajectory of its motion, which is made up of elementary shapes of infinitesimal neighborhoods of points in the trajectory. It has been proved that an infinitesimal neighborhood of a point in a continuous time series can have at least 29 different shapes or configurations. So information can be encoded in it in at least 29 different ways. A 3-point neighborhood (the smallest) in a discrete time series can have precisely 13 different shapes or configurations. In other words, a discrete time series can be expressed as a string of 13 symbols. Across diverse real as well as simulated data sets it has been observed that 6 of them occur more frequently and the remaining 7 occur less frequently. Based on frequency distribution of 13 configurations or 13 different ways of information encoding a novel entropy measure, called semantic entropy (E), has been defined. Following notion of power in Newtonian mechanics of the moving particle whose trajectory is the time series, a notion of information power (P) has been introduced for time series. E/P turned out to be an important indicator of synchronous behaviour of time series as observed in epileptic EEG signals.
| • Ineffectiveness of Dictionary Coding to Infer Predictability Limits of Human Mobility• Neural Network based classification of bone metastasis by primary cacinoma• DeepWeeds: A Multiclass Weed Species Image Dataset for Deep Learning• Automatic Segmentation of Thoracic Aorta Segments in Low-Dose Chest CT• UOLO – automatic object detection and segmentation in biomedical images• Rate Distortion For Model Compression: From Theory To Practice• Is PGD-Adversarial Training Necessary? Alternative Training via a Soft-Quantization Network with Noisy-Natural Samples Only• Unpaired High-Resolution and Scalable Style Transfer Using Generative Adversarial Networks• CRH: A Simple Benchmark Approach to Continuous Hashing• Image Super-Resolution Using VDSR-ResNeXt and SRCGAN• Computational ghost imaging using a field-programmable gate array• A Novel Domain Adaptation Framework for Medical Image Segmentation• A Resource Allocation based Approach for Corporate Mobility as a Service• A Data-Driven Framework for Assessing Cold Load Pick-up Demand in Service Restoration• Learning Optimal Deep Projection of $^{18}$F-FDG PET Imaging for Early Differential Diagnosis of Parkinsonian Syndromes• InfiNet: Fully Convolutional Networks for Infant Brain MRI Segmentation• Bottom-up Attention, Models of• Inventory Balancing with Online Learning• Dirichlet conditions in Poincaré-Sobolev inequalities: the sub-homogeneous case• The highD Dataset: A Drone Dataset of Naturalistic Vehicle Trajectories on German Highways for Validation of Highly Automated Driving Systems• Mean field voter model on networks and multi-variate beta distribution• On the sensitivity analysis of energy quanto options• Subordinators which are infinitely divisible w.r.t. time: Construction, properties, and simulation of max-stable sequences and infinitely divisible laws• Wind Power Persistence is Governed by Superstatistic• Finite sample performance of linear least squares estimation• Thresholds quantifying proportionality criteria for election methods• Smart Load Node for Non-Smart Load under Smart Grid Paradigm• Regression Based Approach for Measurement of Current in Single-Phase Smart Energy Meter• SmartPM: Automatic Adaptation of Dynamic Processes at Run-Time• On mixture representations for the generalized Linnik distribution and their applications in limit theorems• BSDEs driven by $ | z | ^2/y$ and applications• Performance Analysis of Large Intelligence Surfaces (LISs): Asymptotic Data Rate and Channel Hardening Effects• Linear response and moderate deviations: hierarchical approach. IV• Spherical Regression under Mismatch Corruption with Application to Automated Knowledge Translation• Long-Duration Autonomy for Small Rotorcraft UAS including Recharging• Non vanishing of theta functions and sets of small multiplicative energy• Closing the Sim-to-Real Loop: Adapting Simulation Randomization with Real World Experience• Linear Program Reconstruction in Practice• Almost Complete Graphs and the Kruskal Katona Theorem• Improving Generalization of Sequence Encoder-Decoder Networks for Inverse Imaging of Cardiac Transmembrane Potential• Does Haze Removal Help CNN-based Image Classification?• Topology of Z_3 equivariant Hilbert schemes• Policy Transfer with Strategy Optimization• Global Convergence of EM Algorithm for Mixtures of Two Component Linear Regression• Relative compression of trajectories• A Word-Complexity Lexicon and A Neural Readability Ranking Model for Lexical Simplification• Shell Tableaux: A set partition analogue of vacillating tableaux• Topological Inference of Manifolds with Boundary• A geometrically converging dual method for distributed optimization over time-varying graphs• Estimating Robot Strengths with Application to Selection of Alliance Members in FIRST Robotics Competitions• A Model for Auto-Programming for General Purposes• Hierarchical Game-Theoretic Planning for Autonomous Vehicles• $C_{2k}$-saturated graphs with no short odd cycles• CPNet: A Context Preserver Convolutional Neural Network for Detecting Shadows in Single RGB Images• Pose Estimation for Objects with Rotational Symmetry• Stabilization and manipulation of multi-spin states in quantum dot time crystals with Heisenberg interactions• Cloud Detection Algorithm for Remote Sensing Images Using Fully Convolutional Neural Networks• Learning to Globally Edit Images with Textual Description• Point Cloud GAN• Core Influence Mechanism on Vertex-Cover Problem through Leaf-Removal-Core Breaking• Deep learning based cloud detection for remote sensing images by the fusion of multi-scale convolutional features• On the null structure of bipartite graphs without cycles of length a multiple of 4• Towards Provably Safe Mixed Transportation Systems with Human-driven and Automated Vehicles• Extremes of branching Ornstein-Uhlenbeck processes• Efficient Multi-level Correlating for Visual Tracking• On the Rate of Convergence for a Characteristic of Multidimensional Birth-Death Process• Ultrafast cryptography with indefinitely switchable optical nanoantennas• Contagions in Social Networks: Effects of Monophilic Contagion, Friendship Paradox and Reactive Networks• Quantum simulation of clustered photosynthetic light harvesting in a superconducting quantum circuit• Diffusive spin-orbit torque at a surface of topological insulator• Approximating Pairwise Correlations in the Ising Model• Characterising epithelial tissues using persistent entropy• Time Synchronization in Wireless Sensor Networks based on Newtons Adaptive Algorithm• Delay Regulated Explosive Synchronization in Multiplex Networks• Error estimation at the information reconciliation stage of quantum key distribution• Optimal Temperature Spacing for Regionally Weight-preserving Tempering• Nesterov Acceleration of Alternating Least Squares for Canonical Tensor Decomposition• Overview of CAIL2018: Legal Judgment Prediction Competition• Exploiting Semantics in Adversarial Training for Image-Level Domain Adaptation• Using generalized estimating equations to estimate nonlinear models with spatial data• On Greedy and Strategic Evaders in Sequential Interdiction Settings with Incomplete Information• Equivalent Constraints for Two-View Geometry: Pose Solution/Pure Rotation Identification and 3D Reconstruction• Attention Driven Person Re-identification• Understanding Crosslingual Transfer Mechanisms in Probabilistic Topic Modeling• Hybrid Building/Floor Classification and Location Coordinates Regression Using A Single-Input and Multi-Output Deep Neural Network for Large-Scale Indoor Localization Based on Wi-Fi Fingerprinting• Generalized tensor equations with leading structured tensors• Linearizable Replicated State Machines with Lattice Agreement• Further study on tensor absolute value equations• Optimal Control of DERs in ADN under Spatial and Temporal Correlated Uncertainties• Embedded deep learning in ophthalmology: Making ophthalmic imaging smarter• A space-time pseudospectral discretization method for solving diffusion optimal control problems with two-sided fractional derivatives• Optimal Time Scheduling Scheme for Wireless Powered Ambient Backscatter Communication in IoT Network• A New [Combinatorial] Proof of the Commutativity of Matching Polynomials for Cycles• Resource Allocation in IoT networks using Wireless Power Transfer• Deep Learning-Based Channel Estimation• Power Flow as Intersection of Circles: A new Fixed Point Method• Towards Formal Definitions of Blameworthiness, Intention, and Moral Responsibility• Computing the partition function of the Sherrington-Kirkpatrick model is hard on average• Optimal Evidence Accumulation on Social Networks• Group Inverse of the Laplacian of Connections of Networks• Evacuation simulation considering action of the guard in an artificial attack• No-reference Image Denoising Quality Assessment• Two Can Play That Game: An Adversarial Evaluation of a Cyber-alert Inspection System• Porosity Amount Estimation in Stones Based on Combination of One Dimensional Local Binary Patterns and Image Normalization Technique• A Transformation-Proximal Bundle Algorithm for Solving Large-Scale Multistage Adaptive Robust Optimization Problems• Massively Parallel Hyperparameter Tuning• Uniform Convergence Rate of the Kernel Density Estimator Adaptive to Intrinsic Dimension• End-to-End Service Level Agreement Specification for IoT Applications• False Data Injection Cyber-Attack Detection• Enhanced Energy Management System with Corrective Transmission Switching Strategy – Part I: Methodology• Enhanced Energy Management System with Corrective Transmission Switching Strategy – Part II: Results and Discussion• Varifocal-Net: A Chromosome Classification Approach using Deep Convolutional Networks• Social Media Brand Engagement as a Proxy for E-commerce Activities: A Case Study of Sina Weibo and JD• Robust Model Predictive Control of Irrigation Systems with Active Uncertainty Learning and Data Analytics• Delay-Constrained Covert Communications with A Full-Duplex Receiver• The relationship between graphs and Nichols braided Lie algebras• Comparison Detector: A novel object detection method for small dataset• Approximating optimal transport with linear programs• Incorporating Diversity into Influential Node Mining• Rainbow triangles in arc-colored digraphs• Empirical determination of the optimum attack for fragmentation of modular networks• Perceptual Image Quality Assessment through Spectral Analysis of Error Representations• Efficient Reconstructions of Common Era Climate via Integrated Nested Laplace Approximations• DDSL: Efficient Subgraph Listing on Distributed and Dynamic Graphs• Sequential Change-point Detection for High-dimensional and non-Euclidean Data• Learning to Sketch with Deep Q Networks and Demonstrated Strokes• Finding Similar Medical Questions from Question Answering Websites• Kasteleyn operators from mirror symmetry• Theoretical Guarantees of Transfer Learning• Lung Structures Enhancement in Chest Radiographs via CT based FCNN Training• Convex Hull Approximation of Nearly Optimal Lasso Solutions• Modeling Multimodal Dynamic Spatiotemporal Graphs• BLEU is Not Suitable for the Evaluation of Text Simplification |
Like this:
Like Loading…
Related