
In the last blog, we had a look over visualizing text data and understood some basic concepts of tokenization and lemmatization. We wrote python function to perform all the operations for us. If you are directly jumping to this blog, I will highly recommend you to go through the previous blog post in which we have discussed the problem statement and some founding concepts of NLP.
We will be covering the following topics
-
Understanding Tf-IDF
-
Finding Important words using Tf-IDF
-
Understanding Bag of Words
-
Understanding Word Embedding
-
Different Types of word embeddings
-
Difference between word embeddings and Bag of words model
-
Preparing a word embedding for SPAM classifier
Introduction
Previously, we found out the most occurring/common words, bigrams, and trigrams from the messages separately for spam and non-spam messages. Now we need to also find out some important words that can themselves define whether a message is a spam or not. Take a note here that most occurring/common word in a set of messages may not be a keyword that determines what the entire sentence is all about.
For example, in a business article words like business, investment, acquisition are important words that may relate a sentence to a business article. Other words like money, good, building etc may be the frequent words in the messages but they do not have much relevant information to provide.
To find the important words, we will be using the method known as Term Frequency-Inverse Document Frequency (TF-IDF)
What is TF-IDF?
Tf-idf stands for term frequency-inverse document frequency, and the tf-idf weight is a weight often used in information retrieval and text mining.
TF means Term Frequency. It measures how frequently a term occurs in a document. Since every document is different in length, it is possible that a term would appear much more times in long documents than shorter ones. Thus, the term frequency is often divided by the document length as a way of normalization.
TF = (Number of times term w appears in a document) / (Total number of terms in the document)
Second part idf stands for Inverse Document Frequency. It measures how important a term is. While computing TF, all terms are equally important. However, it is known that certain terms, such as “is”, “of”, and “that”, may appear a lot of times but have little importance. Thus we need to weigh down the frequent terms while scaling up the rare ones.
IDF = log_e(Total number of documents / Number of documents with termw init)
We calculate a final tf-idf score by multiplying TF score with IDF score for every word and then finally, we can filter out important words by selecting words with a higher Tf-Idf score.
Code Implementation
An example to calculate Tf-idf score for different words
| Sentences = [“Ironman movie is really good. Ironman is always my favourite”, “Titanic movie is very boring”,”Thor movie is really good”] from sklearn.feature_extraction.text import TfidfVectorizerimport pandas as pdtfidf = TfidfVectorizer()features = tfidf.fit_transform(Sentences)pd.DataFrame(features.todense(),columns=tfidf.get_feature_names()) |
import pandas as pd
features = tfidf.fit_transform(Sentences)
Finding Important words using Tf-IDF Now we will need to find out which are the most important words in both spam and non-spam messages and then we will have a look at those words in the form of the word cloud. We will analyse those words and that will help us to relate why a particular message has been marked as a spam and other as a non-spam message.
First, we import the necessary libraries. Then I have a written a function that returns a TF-IDF score for all words in the corpus
| from gensim.models import TfidfModel from gensim.corpora import Dictionaryfrom gensim import corporafrom gensim import models def get_tfidf_matrix(documents): documents=[my_tokeniser(document) for document in documents] dictionary = corpora.Dictionary(documents) n_items = len(dictionary) corpus = [dictionary.doc2bow(text) for text in documents] tfidf = models.TfidfModel(corpus) corpus_tfidf = tfidf[corpus] return corpus_tfidf |
from gensim.corpora import Dictionary
from gensim import models
def get_tfidf_matrix(documents):
dictionary = corpora.Dictionary(documents)
corpus = [dictionary.doc2bow(text) for text in documents]
corpus_tfidf = tfidf[corpus]
Then we need to map all the scores to the words in the corpus in order to find the most important words
| 1234567891011121314151617181920 | def get_tfidf_score_dataframe(sentiment_label): frames = get_tfidf_matrix(training_dataset[training_dataset[“Sentiment”]==sentiment_label][“Phrase”]) all_score=[] all_words=[] sentence_count=0 for frame in frames: words=my_tokeniser(training_dataset[training_dataset[“Sentiment”]==sentiment_label][“Phrase”].iloc[sentence_count]) sentence_count=sentence_count+1 for i in range(0,len(frame)): all_score.append(frame[i]) all_words.append(words[i]) tf_idf_frame=pd.DataFrame({ ’Words’: all_words, ’Score’: all_score }) count=0 for key, val in tf_idf_frame[“Score”]: tf_idf_frame[“Score”][count] = val count=count+1 return tf_idf_frame |
2
4
6
8
10
12
14
16
18
20
frames = get_tfidf_matrix(training_dataset[training_dataset[“Sentiment”]==sentiment_label][“Phrase”])
all_words=[]
for frame in frames:
sentence_count=sentence_count+1
all_score.append(frame[i])
tf_idf_frame=pd.DataFrame({
’Score’: all_score
count=0
tf_idf_frame[“Score”][count] = val
return tf_idf_frame
Finally, we plot all the important words in the form of a word cloud
| def plot_tf_idf_wordcloud(sentiment_label): tf_idf_frame = get_tfidf_score_dataframe(sentiment_label) sorted_tf_idf_frame=tf_idf_frame.sort_values(“Score”, ascending=False) important_negative_words=sorted_tf_idf_frame[sorted_tf_idf_frame[“Score”]==1][“Words”].unique() comment_words=’‘ for words in important_negative_words: comment_words = comment_words + words + ‘ ‘ wordcloud = WordCloud(width = 800, height = 800, background_color =’white’, stopwords = stopwords, min_font_size = 10).generate(comment_words) plt.figure(figsize = (8, 8), facecolor = None) plt.imshow(wordcloud) plt.axis(“off”) plt.tight_layout(pad = 0) plt.show() |
tf_idf_frame = get_tfidf_score_dataframe(sentiment_label)
important_negative_words=sorted_tf_idf_frame[sorted_tf_idf_frame[“Score”]==1][“Words”].unique()
for words in important_negative_words:
wordcloud = WordCloud(width = 800, height = 800,
stopwords = stopwords,
plt.figure(figsize = (8, 8), facecolor = None)
plt.axis(“off”)
plt.show()
Plotting Important words for non-spam messages
| plot_tf_idf_wordcloud(label=0) |
 Plotting Important words for non-spam messages
Plotting Important words for non-spam messages
| plot_tf_idf_wordcloud(label=1) |

Understanding Bag of Words We need a way to represent text data for the machine learning algorithm and the bag-of-words model helps us to achieve that task. The bag-of-words model is simple to understand and implement. It is a way of extracting features from the text for use in machine learning algorithms.
Understanding Bag of Words
A bag-of-words is a representation of text that describes the occurrence of words within a document. It involves two things:
-
A vocabulary of known words.
-
A measure of the presence of known words.
Vocabulary can be attained by tokenising the messages into different unique tokens. After getting each token, we need to score that token. This can be done in the following ways
-
Counts. Count the number of times each word appears in a document.
-
Frequencies. Calculate the frequency that each word appears in a document out of all the words in the document.
-
TF-IDF : TF score * IDF score
How BoW works
Forming the vector
Take for example 2 text samples: The quick brown fox jumps over the lazy dogand.Never jump over the lazy dog quickly
The corpus(text samples) then form a dictionary:
| { ’brown’: 0, ’dog’: 1, ’fox’: 2, ’jump’: 3, ’jumps’: 4, ’lazy’: 5, ’never’: 6, ’over’: 7, ’quick’: 8, ’quickly’: 9, ’the’: 10,} |
’brown’: 0,
’fox’: 2,
’jumps’: 4,
’never’: 6,
’quick’: 8,
’the’: 10,
Vectors are then formed to represent the count of each word. In this case, each text (i.e. the sentences) will generate a 10-element vector like so:
| [1,1,1,0,1,1,0,1,1,0,2][0,1,0,1,0,1,1,1,0,1,1] |
[0,1,0,1,0,1,1,1,0,1,1]
Each element represents the number of occurrence for each word in the corpus(text sample). So, in the first sentence, there is 1 count for “brown”, 1 count for “dog”, 1 count for “fox” and so on (represented by the first array). Whereas, the vector shows that there is 0 count of “brown”, 1 count for “dog” and 0 counts for “fox”, so on and so forth
Understanding Word Vectors
Word vectors are simply vectors of numbers that represent the meaning of a word.
Traditional approaches to NLP, such as one-hot encodings, do not capture syntactic (structure) and semantic (meaning) relationships across collections of words and, therefore, represent language in a very naive way.
Word vectors represent words as multidimensional continuous floating point numbers where semantically similar words are mapped to proximate points in geometric space. In simpler terms, a word vector is a row of real-valued numbers (as opposed to dummy numbers) where each point captures a dimension of the word’s meaning and where semantically similar words have similar vectors. This means that words such as wheel and engine should have similar word vectors to the word car (because of the similarity of their meanings), whereas the word banana should be quite distant.
A simple representation of word vectors
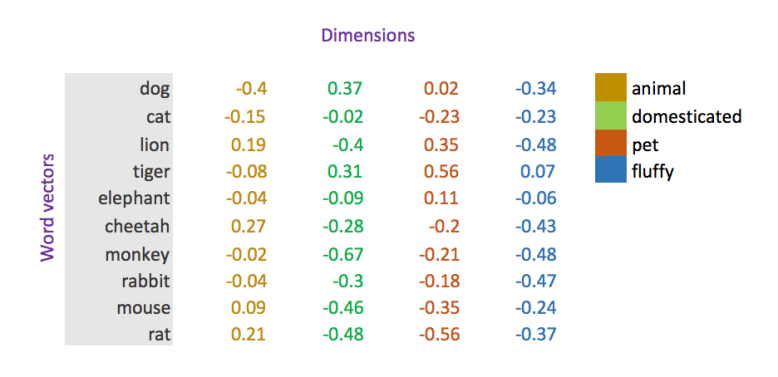
Now we will look at an example of using word vectors where we will group words of similar semantics together
| 12345678910111213141516171819202122232425 | import numpy as npimport spacyfrom sklearn.decomposition import PCAimport matplotlib.pyplot as pltnlp = spacy.load(“en”)sentence = “Tiger was driving a car when he saw a fox taking the charge on a bike but in the end giraffe won the race using his aircraft”tokens = nlp(sentence)vectors = np.vstack([word.vector for word in tokens if word.has_vector])pca = PCA(n_components=2)vecs_transformed = pca.fit_transform(vectors)vecs_transformed = np.c_[sentence.split(), vecs_transformed]plt.figure(figsize = (16, 10), facecolor = None) import pandas as pdfrom sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizervectoriser = TfidfVectorizer(decode_error=”ignore”)X = vectoriser.fit_transform(list(training_dataset[“comment”]))y = training_dataset[“b_labels”]d = pd.DataFrame(vecs_transformed)d.columns=[“Name”,”V1”, “V2”]v1 = [float(x) for x in d[‘V1’]]v2 = [float(x) for x in d[‘V2’]]plt.scatter(v1, v2)for i, txt in enumerate(d[‘Name’]):plt.annotate(txt, (v1[i], v2[i]))plt.show() |
2
4
6
8
10
12
14
16
18
20
22
24
import spacy
import matplotlib.pyplot as plt
sentence = “Tiger was driving a car when he saw a fox taking the charge on a bike but in the end giraffe won the race using his aircraft”
vectors = np.vstack([word.vector for word in tokens if word.has_vector])
vecs_transformed = pca.fit_transform(vectors)
plt.figure(figsize = (16, 10), facecolor = None)
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
X = vectoriser.fit_transform(list(training_dataset[“comment”]))
d = pd.DataFrame(vecs_transformed)
v1 = [float(x) for x in d[‘V1’]]
plt.scatter(v1, v2)
plt.annotate(txt, (v1[i], v2[i]))

Preparing a bag of words model for Analysis
Below is the code snippet for converting our messages into a table which has numerical word vectors. After achieving this only, we can build our classifier using machine learning since machine learning always needs numerical inputs!
| from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizervectoriser = TfidfVectorizer(decode_error=”ignore”)X = vectoriser.fit_transform(list(training_dataset[“comment”]))y = training_dataset[“b_labels”] |
vectoriser = TfidfVectorizer(decode_error=”ignore”)
y = training_dataset[“b_labels”]
| ## Ouput print(X)## <5572x8672 sparse matrix of type ‘<class ‘numpy.float64’>’##with 73916 stored elements in Compressed Sparse Row format> |
print(X)
##with 73916 stored elements in Compressed Sparse Row format>
Conclusion and Further steps
Till now we have learnt to perform EDA over text data. We have also learnt about important terms in NLP like tokenization, lemmatization, stop-words, tf-idf, the bag of words, and word-vectors. These terms are essential to master NLP. After having out word embedding ready, we will proceed to actually build machine learning models. They will help us to predict whether a message is a spam or not. In the next blog, we will build machine learning and neural network models and compare their performance. We will understand shortcomings of the neural net in the case of text mining. Finally, we will move to recurrent neural networks and LSTM to wrap up the series!
Click Here for Part 1 of the article.
Stay tuned!
Please follow and like us:
![]()