Optimized Gated Deep Learning Architectures for Sensor Fusion
Sensor fusion is a key technology that integrates various sensory inputs to allow for robust decision making in many applications such as autonomous driving and robot control. Deep neural networks have been adopted for sensor fusion in a body of recent studies. Among these, the so-called netgated architecture was proposed, which has demonstrated improved performances over the conventional convolutional neural networks (CNN). In this paper, we address several limitations of the baseline negated architecture by proposing two further optimized architectures: a coarser-grained gated architecture employing (feature) group-level fusion weights and a two-stage gated architectures leveraging both the group-level and feature level fusion weights. Using driving mode prediction and human activity recognition datasets, we demonstrate the significant performance improvements brought by the proposed gated architectures and also their robustness in the presence of sensor noise and failures.
Investigating Enactive Learning for Autonomous Intelligent Agents
The enactive approach to cognition is typically proposed as a viable alternative to traditional cognitive science. Enactive cognition displaces the explanatory focus from the internal representations of the agent to the direct sensorimotor interaction with its environment. In this paper, we investigate enactive learning through means of artificial agent simulations. We compare the performances of the enactive agent to an agent operating on classical reinforcement learning in foraging tasks within maze environments. The characteristics of the agents are analysed in terms of the accessibility of the environmental states, goals, and exploration/exploitation tradeoffs. We confirm that the enactive agent can successfully interact with its environment and learn to avoid unfavourable interactions using intrinsically defined goals. The performance of the enactive agent is shown to be limited by the number of affordable actions.
Improvement of K Mean Clustering Algorithm Based on Density
The purpose of this paper is to improve the traditional K-means algorithm. In the traditional K mean clustering algorithm, the initial clustering centers are generated randomly in the data set. It is easy to fall into the local minimum solution when the initial cluster centers are randomly generated. The initial clustering center selected by K-means clustering algorithm which based on density is more representative. The experimental results show that the improved K clustering algorithm can eliminate the dependence on the initial cluster, and the accuracy of clustering is improved.
Building a Reproducible Machine Learning Pipeline
Reproducibility of modeling is a problem that exists for any machine learning practitioner, whether in industry or academia. The consequences of an irreproducible model can include significant financial costs, lost time, and even loss of personal reputation (if results prove unable to be replicated). This paper will first discuss the problems we have encountered while building a variety of machine learning models, and subsequently describe the framework we built to tackle the problem of model reproducibility. The framework is comprised of four main components (data, feature, scoring, and evaluation layers), which are themselves comprised of well defined transformations. This enables us to not only exactly replicate a model, but also to reuse the transformations across different models. As a result, the platform has dramatically increased the speed of both offline and online experimentation while also ensuring model reproducibility.
Sparsity-Based Kalman Filters for Data Assimilation
Several variations of the Kalman filter algorithm, such as the extended Kalman filter (EKF) and the unscented Kalman filter (UKF), are widely used in science and engineering applications. In this paper, we introduce two algorithms of sparsity-based Kalman filters, namely the sparse UKF and the progressive EKF. The filters are designed specifically for problems with very high dimensions. Different from various types of ensemble Kalman filters (EnKFs) in which the error covariance is approximated using a set of dense ensemble vectors, the algorithms developed in this paper are based on sparse matrix approximations of error covariance. The new algorithms enjoy several advantages. The error covariance has full rank without being limited by a set of ensembles. In addition to the estimated states, the algorithms provide updated error covariance for the next assimilation cycle. The sparsity of error covariance significantly reduces the required memory size for the numerical computation. In addition, the granularity of the sparse error covariance can be adjusted to optimize the parallelization of the algorithms.
Deep clustering: On the link between discriminative models and K-means
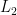
Deep supervised feature selection using Stochastic Gates
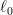
Extreme Classification in Log Memory
We present Merged-Averaged Classifiers via Hashing (MACH) for K-classification with ultra-large values of K. Compared to traditional one-vs-all classifiers that require O(Kd) memory and inference cost, MACH only need O(d log K) (d is dimensionality )memory while only requiring O(K log K + d log K) operation for inference. MACH is a generic K-classification algorithm, with provably theoretical guarantees, which requires O(log K) memory without any assumption on the relationship between classes. MACH uses universal hashing to reduce classification with a large number of classes to few independent classification tasks with small (constant) number of classes. We provide theoretical quantification of discriminability-memory tradeoff. With MACH we can train ODP dataset with 100,000 classes and 400,000 features on a single Titan X GPU, with the classification accuracy of 19.28%, which is the best-reported accuracy on this dataset. Before this work, the best performing baseline is a one-vs-all classifier that requires 40 billion parameters (160 GB model size) and achieves 9% accuracy. In contrast, MACH can achieve 9% accuracy with 480x reduction in the model size (of mere 0.3GB). With MACH, we also demonstrate complete training of fine-grained imagenet dataset (compressed size 104GB), with 21,000 classes, on a single GPU. To the best of our knowledge, this is the first work to demonstrate complete training of these extreme-class datasets on a single Titan X.
A Tale of Three Probabilistic Families: Discriminative, Descriptive and Generative Models
The pattern theory of Grenander is a mathematical framework where the patterns are represented by probability models on random variables of algebraic structures. In this paper, we review three families of probability models, namely, the discriminative models, the descriptive models, and the generative models. A discriminative model is in the form of a classifier. It specifies the conditional probability of the class label given the input signal. The descriptive model specifies the probability distribution of the signal, based on an energy function defined on the signal. A generative model assumes that the signal is generated by some latent variables via a transformation. We shall review these models within a common framework and explore their connections. We shall also review the recent developments that take advantage of the high approximation capacities of deep neural networks.
Multi-Institutional Deep Learning Modeling Without Sharing Patient Data: A Feasibility Study on Brain Tumor Segmentation
Deep learning models for semantic segmentation of images require large amounts of data. In the medical imaging domain, acquiring sufficient data is a significant challenge. Labeling medical image data requires expert knowledge. Collaboration between institutions could address this challenge, but sharing medical data to a centralized location faces various legal, privacy, technical, and data-ownership challenges, especially among international institutions. In this study, we introduce the first use of federated learning for multi-institutional collaboration, enabling deep learning modeling without sharing patient data. Our quantitative results demonstrate that the performance of federated semantic segmentation models (Dice=0.852) on multimodal brain scans is similar to that of models trained by sharing data (Dice=0.862). We compare federated learning with two alternative collaborative learning methods and find that they fail to match the performance of federated learning.
Complementary-Label Learning for Arbitrary Losses and Models
In contrast to the standard classification paradigm where the true (or possibly noisy) class is given to each training pattern, complementary-label learning only uses training patterns each equipped with a complementary label. This only specifies one of the classes that the pattern does not belong to. The seminal paper on complementary-label learning proposed an unbiased estimator of the classification risk that can be computed only from complementarily labeled data. However, it required a restrictive condition on the loss functions, making it impossible to use popular losses such as the softmax cross-entropy loss. Recently, another formulation with the softmax cross-entropy loss was proposed with consistency guarantee. However, this formulation does not explicitly involve a risk estimator. Thus model/hyper-parameter selection is not possible by cross-validation—we may need additional ordinarily labeled data for validation purposes, which is not available in the current setup. In this paper, we give a novel general framework of complementary-label learning, and derive an unbiased risk estimator for arbitrary losses and models. We further improve the risk estimator by non-negative correction and demonstrate its superiority through experiments.
Task Runtime Prediction in Scientific Workflows Using an Online Incremental Learning Approach
Many algorithms in workflow scheduling and resource provisioning rely on the performance estimation of tasks to produce a scheduling plan. A profiler that is capable of modeling the execution of tasks and predicting their runtime accurately, therefore, becomes an essential part of any Workflow Management System (WMS). With the emergence of multi-tenant Workflow as a Service (WaaS) platforms that use clouds for deploying scientific workflows, task runtime prediction becomes more challenging because it requires the processing of a significant amount of data in a near real-time scenario while dealing with the performance variability of cloud resources. Hence, relying on methods such as profiling tasks’ execution data using basic statistical description (e.g., mean, standard deviation) or batch offline regression techniques to estimate the runtime may not be suitable for such environments. In this paper, we propose an online incremental learning approach to predict the runtime of tasks in scientific workflows in clouds. To improve the performance of the predictions, we harness fine-grained resources monitoring data in the form of time-series records of CPU utilization, memory usage, and I/O activities that are reflecting the unique characteristics of a task’s execution. We compare our solution to a state-of-the-art approach that exploits the resources monitoring data based on regression machine learning technique. From our experiments, the proposed strategy improves the performance, in terms of the error, up to 29.89%, compared to the state-of-the-art solutions.
ET-Lasso: Efficient Tuning of Lasso for High-Dimensional Data
The L1 regularization (Lasso) has proven to be a versatile tool to select relevant features and estimate the model coefficients simultaneously. Despite its popularity, it is very challenging to guarantee the feature selection consistency of Lasso. One way to improve the feature selection consistency is to select an ideal tuning parameter. Traditional tuning criteria mainly focus on minimizing the estimated prediction error or maximizing the posterior model probability, such as cross-validation and BIC, which may either be time-consuming or fail to control the false discovery rate (FDR) when the number of features is extremely large. The other way is to introduce pseudo-features to learn the importance of the original ones. Recently, the Knockoff filter is proposed to control the FDR when performing feature selection. However, its performance is sensitive to the choice of the expected FDR threshold. Motivated by these ideas, we propose a new method using pseudo-features to obtain an ideal tuning parameter. In particular, we present the Efficient Tuning of Lasso (ET-Lasso) to separate active and inactive features by adding permuted features as pseudo-features in linear models. The pseudo-features are constructed to be inactive by nature, which can be used to obtain a cutoff to select the tuning parameter that separates active and inactive features. Experimental studies on both simulations and real-world data applications are provided to show that ET-Lasso can effectively and efficiently select active features under a wide range of different scenarios.
Secure Deep Learning Engineering: A Software Quality Assurance Perspective
Over the past decades, deep learning (DL) systems have achieved tremendous success and gained great popularity in various applications, such as intelligent machines, image processing, speech processing, and medical diagnostics. Deep neural networks are the key driving force behind its recent success, but still seem to be a magic black box lacking interpretability and understanding. This brings up many open safety and security issues with enormous and urgent demands on rigorous methodologies and engineering practice for quality enhancement. A plethora of studies have shown that the state-of-the-art DL systems suffer from defects and vulnerabilities that can lead to severe loss and tragedies, especially when applied to real-world safety-critical applications. In this paper, we perform a large-scale study and construct a paper repository of 223 relevant works to the quality assurance, security, and interpretation of deep learning. We, from a software quality assurance perspective, pinpoint challenges and future opportunities towards universal secure deep learning engineering. We hope this work and the accompanied paper repository can pave the path for the software engineering community towards addressing the pressing industrial demand of secure intelligent applications.
The Laplacian in RL: Learning Representations with Efficient Approximations
The smallest eigenvectors of the graph Laplacian are well-known to provide a succinct representation of the geometry of a weighted graph. In reinforcement learning (RL), where the weighted graph may be interpreted as the state transition process induced by a behavior policy acting on the environment, approximating the eigenvectors of the Laplacian provides a promising approach to state representation learning. However, existing methods for performing this approximation are ill-suited in general RL settings for two main reasons: First, they are computationally expensive, often requiring operations on large matrices. Second, these methods lack adequate justification beyond simple, tabular, finite-state settings. In this paper, we present a fully general and scalable method for approximating the eigenvectors of the Laplacian in a model-free RL context. We systematically evaluate our approach and empirically show that it generalizes beyond the tabular, finite-state setting. Even in tabular, finite-state settings, its ability to approximate the eigenvectors outperforms previous proposals. Finally, we show the potential benefits of using a Laplacian representation learned using our method in goal-achieving RL tasks, providing evidence that our technique can be used to significantly improve the performance of an RL agent.
Understanding Data Science Lifecycle Provenance via Graph Segmentation and Summarization
Increasingly modern data science platforms today have non-intrusive and extensible provenance ingestion mechanisms to collect rich provenance and context information, handle modifications to the same file using distinguishable versions, and use graph data models (e.g., property graphs) and query languages (e.g., Cypher) to represent and manipulate the stored provenance/context information. Due to the schema-later nature of the metadata, multiple versions of the same files, and unfamiliar artifacts introduced by team members, the ‘provenance graph’ is verbose and evolving, and hard to understand; using standard graph query model, it is difficult to compose queries and utilize this valuable information. In this paper, we propose two high-level graph query operators to address the verboseness and evolving nature of such provenance graphs. First, we introduce a graph segmentation operator, which queries the retrospective provenance between a set of source vertices and a set of destination vertices via flexible boundary criteria to help users get insight about the derivation relationships among those vertices. We show the semantics of such a query in terms of a context-free grammar, and develop efficient algorithms that run orders of magnitude faster than state-of-the-art. Second, we propose a graph summarization operator that combines similar segments together to query prospective provenance of the underlying project. The operator allows tuning the summary by ignoring vertex details and characterizing local structures, and ensures the provenance meaning using path constraints. We show the optimal summary problem is PSPACE-complete and develop effective approximation algorithms. The operators are implemented on top of a property graph backend. We evaluate our query methods extensively and show the effectiveness and efficiency of the proposed methods.
Principal component-guided sparse regression

• Quantification of Trabeculae Inside the Heart from MRI Using Fractal Analysis• Where and When to Look? Spatio-temporal Attention for Action Recognition in Videos• Deep Reinforcement Learning for Time Scheduling in RF-Powered Backscatter Cognitive Radio Networks• Survival prediction using ensemble tumor segmentation and transfer learning• Current Trends and Future Research Directions for Interactive Music• A Deep Learning Approach to the Inversion of Borehole Resistivity Measurements• Big Bang Bifurcations in the Tantalus Oscillator under Biphasics Perturbations• Structured decomposition for reversible Boolean functions• Towards Lattice Quantum Chromodynamics on FPGA devices• Fully integrative data analysis of NMR metabolic fingerprints with comprehensive patient data: a case report based on the German Chronic Kidney Disease (GCKD) study• Convergence analysis of fixed stress split iterative scheme for small strain anisotropic poroelastoplasticity: a primer• Is your Statement Purposeless? Predicting Computer Science Graduation Admission Acceptance based on Statement Of Purpose• Optimal Regulation of Blood Glucose Level in Type I Diabetes using Insulin and Glucagon• GraphMP: I/O-Efficient Big Graph Analytics on a Single Commodity Machine• A decoding algorithm for binary linear codes using Groebner bases• Interpreting Winograd Schemas Via the SP Theory of Intelligence and Its Realisation in the SP Computer Model• Caracterización Formal y Análisis Empírico de Mecanismos Incrementales de Búsqueda basados en Contexto• The algebraic area of closed lattice random walks• Fire seasonality identification with multimodality tests• Solving efficiently the dynamics of many-body localized systems at strong disorder• Uniform CSP Parameterized by Solution Size is in W[1]• Using learning to control artificial avatars in human motor coordination tasks• Multi-resolution filters for massive spatio-temporal data• Approximation of Lipschitz functions preserving boundary values• The Computational Complexity of Training ReLU(s)• Quenched asymptotics for a 1-d stochastic heat equation driven by a rough spatial noise• Facial reduction for exact polynomial sum of squares decompositions• Event Coreference Resolution Using Neural Network Classifiers• On the distribution of the hitting time for the N-urn Ehrenfest model• Rethinking multiscale cardiac electrophysiology with machine learning and predictive modelling• Capacity of Private Linear Computation for Coded Databases• Penetrating the Fog: the Path to Efficient CNN Models• Deep Neural Network Compression for Aircraft Collision Avoidance Systems• Distributed Wildfire Surveillance with Autonomous Aircraft using Deep Reinforcement Learning• Data-dependent compression of random features for large-scale kernel approximation• Bird Species Classification using Transfer Learning with Multistage Training• Cycle Intersection Graphs and Minimum Decycling Sets of Even Graphs• Geometric constructions over $\mathbb{C}$ and $\mathbb{F}2$ for Quantum Information• Fair Division Minimizing Inequality• Inter-Scanner Harmonization of High Angular Resolution DW-MRI using Null Space Deep Learning• A priori error estimates for the optimal control of the integral fractional Laplacian• Optimal Control under Controlled-Loss Constraints via Reachability Approach and Compactification• A maximum-mean-discrepancy goodness-of-fit test for censored data• Simulation of unsteady blood flows in a patient-specific compliant pulmonary artery with a highly parallel monolithically coupled fluid-structure interaction algorithm• Decipherment of Historical Manuscript Images• Polar Codes with exponentially small error at finite block length• Stochasticization of Solutions to the Yang-Baxter Equation• Relative Error of Scaled Poisson Approximation via Stein’s Method• Detection and Mitigation of Biasing Attacks on Distributed Estimation Networks• On Tracking the Physicality of Wi-Fi: A Subspace Approach• Batch Active Preference-Based Learning of Reward Functions• Using ACL2 in the Design of Efficient, Verifiable Data Structures for High-Assurance Systems• Real Vector Spaces and the Cauchy-Schwarz Inequality in ACL2(r)• Convex Functions in ACL2(r)• Using Normalized Cross Correlation in Least Squares Optimizations• The Andoni–Krauthgamer–Razenshteyn characterization of sketchable norms fails for sketchable metrics• Analysis of Maximal Topologies Achieving Optimal DoF and DoF $\frac{1}{n}$ in Topological Interference Management• Assignment Mechanisms under Distributional Constraints• Combining Bayesian Optimization and Lipschitz Optimization• Bayesian Nonparametric Policy Search with Application to Periodontal Recall Intervals• Maximizing Cliques in Shellable Clique Complexes• Robust optimization of a broad class of heterogeneous vehicle routing problems under demand uncertainty• Left-Right Pairs and Complex Forests of Infinite Rooted Binary Trees• Incorporating Posterior Model Discrepancy into a Hierarchical Framework to Facilitate Out-of-the-Box MCMC Sampling for Geothermal Inverse Problems and Uncertainty Quantification• Properly-weighted graph Laplacian for semi-supervised learning• Stability-constrained Optimization for Nonlinear Systems based on Convex Lyapunov Functions• Positivity for quantum cluster algebras from unpunctured orbifolds• Semi-supervised clustering for de-duplication• Quantum Control Landscape of Bipartite Systems• On components of a Kerdock code and the dual of the BCH code $C{1,3}$• $ε$-Nash Equilibria for Major Minor LQG Mean Field Games with Partial Observations of All Agents• Alternating Hamiltonian cycles in $2$-edge-colored multigraphs• Random ReLU Features: Universality, Approximation, and Composition• Measuring Hardware Impairments with Software-Defined Radios• Learning Deep Representations for Semantic Image Parsing: a Comprehensive Overview• Classifying k-Edge Colouring for H-free Graphs• A probabilistic model for interfaces in a martensitic phase transition• Response to Comment on ‘All-optical machine learning using diffractive deep neural networks’• Energy Efficiency of Distributed Antenna Systems with Wireless Power Transfer• Mixed-Integer Programming Formulation of a Data-Driven Solver in Computational Elasticity• Maker-Breaker domination number• V3C – a Research Video Collection• An application of Brascamp-Lieb’s inequality• Tunable high index photonic glasses• State Estimation and Tracking Control for Hybrid Systems by Gluing the Domains• Spectrum Sharing for Internet of Things: A Survey• Prediction of the Influence of Navigation Scan-path on Perceived Quality of Free-Viewpoint Videos• Fast Approximation of EEG Forward Problem and Application to Tissue Conductivity Estimation• Harmonizable mixture kernels with variational Fourier features• Comparison of 3-D contouring methodologies through the study of extreme tension in a mooring line of a semi-submersible• Improving Neural Text Simplification Model with Simplified Corpora• The Zonotopal Algebra of the Broken Wheel Graphy and its Generalization• Lazy-CFR: a fast regret minimization algorithm for extensive games with imperfect information• Persistence pays off: Paying Attention to What the LSTM Gating Mechanism Persists• Global Search with Bernoulli Alternation Kernel for Task-oriented Grasping Informed by Simulation• Kräuter conjecture on permanents is true• New Vistas to study Bhartrhari: Cognitive NLP• On the Properties of Simulation-based Estimators in High Dimensions• Learning Multi-agent Implicit Communication Through Actions: A Case Study in Contract Bridge, a Collaborative Imperfect-Information Game• Local Average Estimation and Inferences for Varying Coefficient Models• Faster Hamiltonian Monte Carlo by Learning Leapfrog Scale• AI Learns to Recognize Bengali Handwritten Digits: Bengali.AI Computer Vision Challenge 2018• Invariance Analysis of Saliency Models versus Human Gaze During Scene Free Viewing• Cluster Pairwise Error Probability and Construction of Parity-Check-Concatenated Polar Codes• Let’s take a Walk on Superpixels Graphs: Deformable Linear Objects Segmentation and Model Estimation• SECaps: A Sequence Enhanced Capsule Model for Charge Prediction• On some Limit Theorem for Markov Chain• Decentralized Cooperative Stochastic Multi-armed Bandits• Analysis Of Congestion Control In Data Channels With Frequent Frame Loss• Detecting Directed Interactions of Networks by Random Variable Resetting• Domain Confusion with Self Ensembling for Unsupervised Adaptation• Uniquely restricted matchings in subcubic graphs without short cycles• Diffusion with nonlocal Dirichlet boundary conditions on unbounded domains• The stepping-stone sampling algorithm for calculating the evidence of gravitational wave models• Interference Exploitation-based Hybrid Precoding with Robustness Against Phase Errors• Multi-class Classification Model Inspired by Quantum Detection Theory• Dynamic attitude planning for trajectory tracking in underactuated VTOL UAVs• On maxima of stationary fields• LIRS: Enabling efficient machine learning on NVM-based storage via a lightweight implementation of random shuffling• Bayesian selection for coarse-grained models of liquid water• A Fast Polynomial-time Primal-Dual Projection Algorithm for Linear Programming• Is there Gender bias and stereotype in Portuguese Word Embeddings?• Power Allocation for Massive MIMO-based, Fronthaul-constrained Cloud RAN Systems• Random matrix-improved estimation of covariance matrix distances• Nonlinear Acceleration of Momentum and Primal-Dual Algorithms• On the Evolution of Spreading Processes in Complex Networks• On the Complexity of Solution Extension of Optimization Problems• Strategic Contention Resolution in Multiple Channels• Joint Models of Insurance Lapsation and Claims• Functional limit theorem for occupation time processes of infinite ergodic transformations• EDOSE: Emotion Datasets from Open Source EEG with a Real-Time Bracelet Sensor• The Mondrian Puzzle: A Connection to Number Theory• Coexistence of competing first passage percolation on hyperbolic graphs• ECHO-3DHPC: Advance the performance of astrophysics simulations with code modernization• Non universality of fluctuations of outliers for Hermitian polynomials in a Wigner matrix and a spiked diagonal matrix• A Similarity Measure for Weaving Patterns in Textiles• Building an Ontology for the Domain of Plant Science using Protégé• Scalar MSCR Codes via the Product Matrix Construction• Testing Community Structures for Hypergraphs• Parameterized Complexity of Independent Set in H-Free Graphs• Pruning neural networks: is it time to nip it in the bud?• Extension of vertex cover and independent set in some classes of graphs and generalizations• Structured Argument Extraction of Korean Question and Command• Non-linear process convolutions for multi-output Gaussian processes• Multimodal Speech Emotion Recognition Using Audio and Text• Virtual Battery Parameter Identification using Transfer Learning based Stacked Autoencoder• Multi-Task Learning as Multi-Objective Optimization• Learning Embeddings for Product Visual Search with Triplet Loss and Online Sampling• Adaptive Fraud Detection System Using Dynamic Risk Features
Like this:
Like Loading…
Related