Densely Supervised Grasp Detector (DSGD)
This paper presents Densely Supervised Grasp Detector (DSGD), a deep learning framework which combines CNN structures with layer-wise feature fusion and produces grasps and their confidence scores at different levels of the image hierarchy (i.e., global-, region-, and pixel-levels). Specifically, at the global-level, DSGD uses the entire image information to predict a grasp and its confidence score. At the region-level, DSGD uses a region proposal network to identify salient regions in the image and predicts a grasp for each salient region. At the pixel-level, DSGD uses a fully convolutional network and predicts a grasp and its confidence at every pixel. The grasp with the highest confidence score is selected as the output of DSGD. This selection from hierarchically generated grasp candidates overcomes limitations of the individual models. DSGD outperforms state-of-the-art methods on the Cornell grasp dataset in terms of grasp accuracy. Evaluation on a multi-object dataset and real-world robotic grasping experiments show that DSGD produces highly stable grasps on a set of unseen objects in new environments. It achieves 96% grasp detection accuracy and 90% robotic grasping success rate with real-time inference speed.
Deep Decoder: Concise Image Representations from Untrained Non-convolutional Networks
Deep neural networks, in particular convolutional neural networks, have become highly effective tools for compressing images and solving inverse problems including denoising, inpainting, and reconstruction from few and noisy measurements. This success can be attributed in part to their ability to represent and generate natural images well. Contrary to classical tools such as wavelets, image-generating deep neural networks have a large number of parameters—typically a multiple of their output dimension—and need to be trained on large datasets. In this paper, we propose an untrained simple image model, called the deep decoder, which is a deep neural network that can generate natural images from very few weight parameters. The deep decoder has a simple architecture with no convolutions and fewer weight parameters than the output dimensionality. This underparameterization enables the deep decoder to compress images into a concise set of network weights, which we show is on par with wavelet-based thresholding. Further, underparameterization provides a barrier to overfitting, allowing the deep decoder to have state-of-the-art performance for denoising. The deep decoder is simple in the sense that each layer has an identical structure that consists of only one upsampling unit, pixel-wise linear combination of channels, ReLU activation, and channelwise normalization. This simplicity makes the network amenable to theoretical analysis, and it sheds light on the aspects of neural networks that enable them to form effective signal representations.
DeepImageSpam: Deep Learning based Image Spam Detection
Hackers and spammers are employing innovative and novel techniques to deceive novice and even knowledgeable internet users. Image spam is one of such technique where the spammer varies and changes some portion of the image such that it is indistinguishable from the original image fooling the users. This paper proposes a deep learning based approach for image spam detection using the convolutional neural networks which uses a dataset with 810 natural images and 928 spam images for classification achieving an accuracy of 91.7% outperforming the existing image processing and machine learning techniques
Model Cards for Model Reporting
Trained machine learning models are increasingly used to perform high-impact tasks in areas such as law enforcement, medicine, education, and employment. In order to clarify the intended use cases of machine learning models and minimize their usage in contexts for which they are not well suited, we recommend that released models be accompanied by documentation detailing their performance characteristics. In this paper, we propose a framework that we call model cards, to encourage such transparent model reporting. Model cards are short documents accompanying trained machine learning models that provide benchmarked evaluation in a variety of conditions, such as across different cultural, demographic, or phenotypic groups (e.g., race, geographic location, sex, Fitzpatrick skin type) and intersectional groups (e.g., age and race, or sex and Fitzpatrick skin type) that are relevant to the intended application domains. Model cards also disclose the context in which models are intended to be used, details of the performance evaluation procedures, and other relevant information. While we focus primarily on human-centered machine learning models in the application fields of computer vision and natural language processing, this framework can be used to document any trained machine learning model. To solidify the concept, we provide cards for two supervised models: One trained to detect smiling faces in images, and one trained to detect toxic comments in text. We propose model cards as a step towards the responsible democratization of machine learning and related AI technology, increasing transparency into how well AI technology works. We hope this work encourages those releasing trained machine learning models to accompany model releases with similar detailed evaluation numbers and other relevant documentation.
A Comprehensive Study of Deep Learning for Image Captioning
Generating a description of an image is called image captioning. Image captioning requires to recognize the important objects, their attributes and their relationships in an image. It also needs to generate syntactically and semantically correct sentences. Deep learning-based techniques are capable of handling the complexities and challenges of image captioning. In this survey paper, we aim to present a comprehensive review of existing deep learning-based image captioning techniques. We discuss the foundation of the techniques to analyze their performances, strengths and limitations. We also discuss the datasets and the evaluation metrics popularly used in deep learning based automatic image captioning.
Testing exchangeability with martingale for change-point detection
This work studies the exchangeability test for a random sequence through a martingale based approach. Its main contributions include: 1) an additive martingale is introduced, which is more amenable for designing exchangeability tests by exploiting the Hoeffding-Azuma lemma; 2) different betting functions for constructing the additive martingale are studied. By choosing the underlying probability density function of p-values as betting function, it can be shown that, when change-point appears, a satisfying trade-off between the smoothness and expected one-step increment of the martingale sequence can be obtained. An online algorithm based on Beta distribution parametrization for constructing this betting function is discussed as well.
On Learning and Learned Representation with Dynamic Routing in Capsule Networks
Capsule Networks (CapsNet) are recently proposed multi-stage computational models specialized for entity representation and discovery in image data. CapsNet employs iterative routing that shapes how the information cascades through different levels of interpretations. In this work, we investigate i) how the routing affects the CapsNet model fitting, ii) how the representation by capsules helps discover global structures in data distribution and iii) how learned data representation adapts and generalizes to new tasks. Our investigation shows: i) routing operation determines the certainty with which one layer of capsules pass information to the layer above, and the appropriate level of certainty is related to the model fitness, ii) in a designed experiment using data with a known 2D structure, capsule representations allow more meaningful 2D manifold embedding than neurons in a standard CNN do and iii) compared to neurons of standard CNN, capsules of successive layers are less coupled and more adaptive to new data distribution.
Understanding the Origins of Bias in Word Embeddings
The power of machine learning systems not only promises great technical progress, but risks societal harm. As a recent example, researchers have shown that popular word embedding algorithms exhibit stereotypical biases, such as gender bias. The widespread use of these algorithms in machine learning systems, from automated translation services to curriculum vitae scanners, can amplify stereotypes in important contexts. Although methods have been developed to measure these biases and alter word embeddings to mitigate their biased representations, there is a lack of understanding in how word embedding bias depends on the training data. In this work, we develop a technique for understanding the origins of bias in word embeddings. Given a word embedding trained on a corpus, our method identifies how perturbing the corpus will affect the bias of the resulting embedding. This can be used to trace the origins of word embedding bias back to the original training documents. Using our method, one can investigate trends in the bias of the underlying corpus and identify subsets of documents whose removal would most reduce bias. We demonstrate our techniques on both a New York Times and Wikipedia corpus and find that our influence function-based approximations are extremely accurate.
CAML: Fast Context Adaptation via Meta-Learning
We propose CAML, a meta-learning method for fast adaptation that partitions the model parameters into two parts: context parameters that serve as additional input to the model and are adapted on individual tasks, and shared parameters that are meta-trained and shared across tasks. At test time, the context parameters are updated with one or several gradient steps on a task-specific loss that is backpropagated through the shared part of the network. Compared to approaches that adjust all parameters on a new task (e.g., MAML), our method can be scaled up to larger networks without overfitting on a single task, is easier to implement, and saves memory writes during training and network communication at test time for distributed machine learning systems. We show empirically that this approach outperforms MAML, is less sensitive to the task-specific learning rate, can capture meaningful task embeddings with the context parameters, and outperforms alternative partitionings of the parameter vectors.
Practical Bayesian Optimization for Transportation Simulators
Simulators play a major role in analyzing multi-modal transportation networks. As complexity of simulators increases, development of calibration procedures is becoming an increasingly challenging task. Current calibration procedures often rely on heuristics, rules of thumb and sometimes on brute-force search. In this paper we consider and automated framework for calibration that relies on Bayesian optimization. Bayesian optimization treats the simulator as a sample from a Gaussian process (GP). Tractability and sample efficiency of Gaussian processes enable computationally efficient algorithms for calibration problems. We show how the choice of prior and inference algorithm effect the outcome of our optimization procedure. We develop dimensionality reduction techniques that allow for our optimization techniques to be applicable for real-life problems. We develop a distributed, Gaussian Process Bayesian regression and active learning models. We demonstrate those to calibrate ground transportation simulation models. Finally, we discuss directions for further research.
Find the dimension that counts: Fast dimension estimation and Krylov PCA

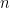
Deep Tractable Probabilistic Models for Moral Responsibility
Moral responsibility is a major concern in automated decision-making, with applications ranging from self-driving cars to kidney exchanges. From the viewpoint of automated systems, the urgent questions are: (a) How can models of moral scenarios and blameworthiness be extracted and learnt automatically from data? (b) How can judgements be computed tractably, given the split-second decision points faced by the system? By building on deep tractable probabilistic learning, we propose a learning regime for inducing models of such scenarios automatically from data and reasoning tractably from them. We report on experiments that compare our system with human judgement in three illustrative domains: lung cancer staging, teamwork management, and trolley problems.
JOBS: Joint-Sparse Optimization from Bootstrap Samples


Unsupervised Object Matching for Relational Data
We propose an unsupervised object matching method for relational data, which finds matchings between objects in different relational datasets without correspondence information. For example, the proposed method matches documents in different languages in multi-lingual document-word networks without dictionaries nor alignment information. The proposed method assumes that each object has latent vectors, and the probability of neighbor objects is modeled by the inner-product of the latent vectors, where the neighbors are generated by short random walks over the relations. The latent vectors are estimated by maximizing the likelihood of the neighbors for each dataset. The estimated latent vectors contain hidden structural information of each object in the given relational dataset. Then, the proposed method linearly projects the latent vectors for all the datasets onto a common latent space shared across all datasets by matching the distributions while preserving the structural information. The projection matrix is estimated by minimizing the distance between the latent vector distributions with an orthogonality regularizer. To represent the distributions effectively, we use the kernel embedding of distributions that hold high-order moment information about a distribution as an element in a reproducing kernel Hilbert space, which enables us to calculate the distance between the distributions without density estimation. The structural information encoded in the latent vectors are preserved by using the orthogonality regularizer. We demonstrate the effectiveness of the proposed method with experiments using real-world multi-lingual document-word relational datasets and multiple user-item relational datasets.
Reinforcement Learning for Improving Agent Design
What made you do this? Understanding black-box decisions with sufficient input subsets
Local explanation frameworks aim to rationalize particular decisions made by a black-box prediction model. Existing techniques are often restricted to a specific type of predictor or based on input saliency, which may be undesirably sensitive to factors unrelated to the model’s decision making process. We instead propose sufficient input subsets that identify minimal subsets of features whose observed values alone suffice for the same decision to be reached, even if all other input feature values are missing. General principles that globally govern a model’s decision-making can also be revealed by searching for clusters of such input patterns across many data points. Our approach is conceptually straightforward, entirely model-agnostic, simply implemented using instance-wise backward selection, and able to produce more concise rationales than existing techniques. We demonstrate the utility of our interpretation method on various neural network models trained on text, image, and genomic data.
Analyzing the Noise Robustness of Deep Neural Networks
Deep neural networks (DNNs) are vulnerable to maliciously generated adversarial examples. These examples are intentionally designed by making imperceptible perturbations and often mislead a DNN into making an incorrect prediction. This phenomenon means that there is significant risk in applying DNNs to safety-critical applications, such as driverless cars. To address this issue, we present a visual analytics approach to explain the primary cause of the wrong predictions introduced by adversarial examples. The key is to analyze the datapaths of the adversarial examples and compare them with those of the normal examples. A datapath is a group of critical neurons and their connections. To this end, we formulate the datapath extraction as a subset selection problem and approximately solve it based on back-propagation. A multi-level visualization consisting of a segmented DAG (layer level), an Euler diagram (feature map level), and a heat map (neuron level), has been designed to help experts investigate datapaths from the high-level layers to the detailed neuron activations. Two case studies are conducted that demonstrate the promise of our approach in support of explaining the working mechanism of adversarial examples.
Answer Extraction in Question Answering using Structure Features and Dependency Principles
Question Answering (QA) research is a significant and challenging task in Natural Language Processing. QA aims to extract an exact answer from a relevant text snippet or a document. The motivation behind QA research is the need of user who is using state-of-the-art search engines. The user expects an exact answer rather than a list of documents that probably contain the answer. In this paper, for a successful answer extraction from relevant documents several efficient features and relations are required to extract. The features include various lexical, syntactic, semantic and structural features. The proposed structural features are extracted from the dependency features of the question and supported document. Experimental results show that structural features improve the accuracy of answer extraction when combined with the basic features and designed using dependency principles. Proposed structural features use new design principles which extract the long-distance relations. This addition is a possible reason behind the improvement in overall answer extraction accuracy.
Transfer Metric Learning: Algorithms, Applications and Outlooks
Distance metric learning (DML) aims to find an appropriate way to reveal the underlying data relationship. It is critical in many machine learning, pattern recognition and data mining algorithms, and usually require large amount of label information (class labels or pair/triplet constraints) to achieve satisfactory performance. However, the label information may be insufficient in real-world applications due to the high-labeling cost, and DML may fail in this case. Transfer metric learning (TML) is able to mitigate this issue for DML in the domain of interest (target domain) by leveraging knowledge/information from other related domains (source domains). Although achieved a certain level of development, TML has limited success in various aspects such as selective transfer, theoretical understanding, handling complex data, big data and extreme cases. In this survey, we present a systematic review of the TML literature. In particular, we group TML into different categories according to different settings and metric transfer strategies, such as direct metric approximation, subspace approximation, distance approximation, and distribution approximation. A summarization and insightful discussion of the various TML approaches and their applications will be presented. Finally, we provide some challenges and possible future directions.
Convolutional Neural Networks In Convolution
Currently, increasingly deeper neural networks have been applied to improve their accuracy. In contrast, We propose a novel wider Convolutional Neural Networks (CNN) architecture, motivated by the Multi-column Deep Neural Networks and the Network In Network(NIN), aiming for higher accuracy without input data transmutation. In our architecture, namely ‘CNN In Convolution’(CNNIC), a small CNN, instead of the original generalized liner model(GLM) based filters, is convoluted as kernel on the original image, serving as feature extracting layer of this networks. And further classifications are then carried out by a global average pooling layer and a softmax layer. Dropout and orthonormal initialization are applied to overcome training difficulties including slow convergence and over-fitting. Persuasive classification performance is demonstrated on MNIST.
textTOvec: Deep Contextualized Neural Autoregressive Models of Language with Distributed Compositional Prior
| We address two challenges of probabilistic topic modelling in order to better estimate the probability of a word in a given context, i.e., P(word | context): (1) No Language Structure in Context: Probabilistic topic models ignore word order by summarizing a given context as a ‘bag-of-word’ and consequently the semantics of words in the context is lost. The LSTM-LM learns a vector-space representation of each word by accounting for word order in local collocation patterns and models complex characteristics of language (e.g., syntax and semantics), while the TM simultaneously learns a latent representation from the entire document and discovers the underlying thematic structure. We unite two complementary paradigms of learning the meaning of word occurrences by combining a TM and a LM in a unified probabilistic framework, named as ctx-DocNADE. (2) Limited Context and/or Smaller training corpus of documents: In settings with a small number of word occurrences (i.e., lack of context) in short text or data sparsity in a corpus of few documents, the application of TMs is challenging. We address this challenge by incorporating external knowledge into neural autoregressive topic models via a language modelling approach: we use word embeddings as input of a LSTM-LM with the aim to improve the word-topic mapping on a smaller and/or short-text corpus. The proposed DocNADE extension is named as ctx-DocNADEe. We present novel neural autoregressive topic model variants coupled with neural LMs and embeddings priors that consistently outperform state-of-the-art generative TMs in terms of generalization (perplexity), interpretability (topic coherence) and applicability (retrieval and classification) over 6 long-text and 8 short-text datasets from diverse domains. |
Fixing Variational Bayes: Deterministic Variational Inference for Bayesian Neural Networks
Bayesian neural networks (BNNs) hold great promise as a flexible and principled solution to deal with uncertainty when learning from finite data. Among approaches to realize probabilistic inference in deep neural networks, variational Bayes (VB) is theoretically grounded, generally applicable, and computationally efficient. With wide recognition of potential advantages, why is it that variational Bayes has seen very limited practical use for BNNs in real applications? We argue that variational inference in neural networks is fragile: successful implementations require careful initialization and tuning of prior variances, as well as controlling the variance of Monte Carlo gradient estimates. We fix VB and turn it into a robust inference tool for Bayesian neural networks. We achieve this with two innovations: first, we introduce a novel deterministic method to approximate moments in neural networks, eliminating gradient variance; second, we introduce a hierarchical prior for parameters and a novel empirical Bayes procedure for automatically selecting prior variances. Combining these two innovations, the resulting method is highly efficient and robust. On the application of heteroscedastic regression we demonstrate strong predictive performance over alternative approaches.
Bridging the gap between regret minimization and best arm identification, with application to A/B tests
State of the art online learning procedures focus either on selecting the best alternative (‘best arm identification’) or on minimizing the cost (the ‘regret’). We merge these two objectives by providing the theoretical analysis of cost minimizing algorithms that are also delta-PAC (with a proven guaranteed bound on the decision time), hence fulfilling at the same time regret minimization and best arm identification. This analysis sheds light on the common observation that ill-callibrated UCB-algorithms minimize regret while still identifying quickly the best arm. We also extend these results to the non-iid case faced by many practitioners. This provides a technique to make cost versus decision time compromise when doing adaptive tests with applications ranging from website A/B testing to clinical trials.
Enabling Cognitive Smart Cities Using Big Data and Machine Learning: Approaches and Challenges
The development of smart cities and their fast-paced deployment is resulting in the generation of large quantities of data at unprecedented rates. Unfortunately, most of the generated data is wasted without extracting potentially useful information and knowledge because of the lack of established mechanisms and standards that benefit from the availability of such data. Moreover, the high dynamical nature of smart cities calls for new generation of machine learning approaches that are flexible and adaptable to cope with the dynamicity of data to perform analytics and learn from real-time data. In this article, we shed the light on the challenge of under utilizing the big data generated by smart cities from a machine learning perspective. Especially, we present the phenomenon of wasting unlabeled data. We argue that semi-supervision is a must for smart city to address this challenge. We also propose a three-level learning framework for smart cities that matches the hierarchical nature of big data generated by smart cities with a goal of providing different levels of knowledge abstractions. The proposed framework is scalable to meet the needs of smart city services. Fundamentally, the framework benefits from semi-supervised deep reinforcement learning where a small amount of data that has users’ feedback serves as labeled data while a larger amount is without such users’ feedback serves as unlabeled data. This paper also explores how deep reinforcement learning and its shift toward semi-supervision can handle the cognitive side of smart city services and improve their performance by providing several use cases spanning the different domains of smart cities. We also highlight several challenges as well as promising future research directions for incorporating machine learning and high-level intelligence into smart city services.
Discovering General-Purpose Active Learning Strategies
We propose a general-purpose approach to discovering active learning (AL) strategies from data. These strategies are transferable from one domain to another and can be used in conjunction with many machine learning models. To this end, we formalize the annotation process as a Markov decision process, design universal state and action spaces and introduce a new reward function that precisely model the AL objective of minimizing the annotation cost We seek to find an optimal (non-myopic) AL strategy using reinforcement learning. We evaluate the learned strategies on multiple unrelated domains and show that they consistently outperform state-of-the-art baselines.
A Family of Maximum Margin Criterion for Adaptive Learning
In recent years, pattern analysis plays an important role in data mining and recognition, and many variants have been proposed to handle complicated scenarios. In the literature, it has been quite familiar with high dimensionality of data samples, but either such characteristics or large data have become usual sense in real-world applications. In this work, an improved maximum margin criterion (MMC) method is introduced firstly. With the new definition of MMC, several variants of MMC, including random MMC, layered MMC, 2D^2 MMC, are designed to make adaptive learning applicable. Particularly, the MMC network is developed to learn deep features of images in light of simple deep networks. Experimental results on a diversity of data sets demonstrate the discriminant ability of proposed MMC methods are compenent to be adopted in complicated application scenarios.
Positional Cartesian Genetic Programming
Cartesian Genetic Programming (CGP) has many modifications across a variety of implementations, such as recursive connections and node weights. Alternative genetic operators have also been proposed for CGP, but have not been fully studied. In this work, we present a new form of genetic programming based on a floating point representation. In this new form of CGP, called Positional CGP, node positions are evolved. This allows for the evaluation of many different genetic operators while allowing for previous CGP improvements like recurrency. Using nine benchmark problems from three different classes, we evaluate the optimal parameters for CGP and PCGP, including novel genetic operators.
• A categorisation and implementation of digital pen features for behaviour characterisation• Extended Bit-Plane Compression for Convolutional Neural Network Accelerators• Machine learning clustering technique applied to powder X-ray diffraction patterns to distinguish alloy substitutions• A Brief Survey on Autonomous Vehicle Possible Attacks, Exploits and Vulnerabilities• SAM-GCNN: A Gated Convolutional Neural Network with Segment-Level Attention Mechanism for Home Activity Monitoring• On the Evaluation and Validation of Off-the-shelf Statistical Shape Modeling Tools: A Clinical Application• GPU based Parallel Optimization for Real Time Panoramic Video Stitching• Image-to-Video Person Re-Identification by Reusing Cross-modal Embeddings• DeepNIS: Deep Neural Network for Nonlinear Electromagnetic Inverse Scattering• On conjectures regarding the Nekrasov–Okounkov hook length formula• Deep Convolutional Neural Networks for Noise Detection in ECGs• A Novel Indoor Mobile Localization System Based on Optical Camera Communication• Computationally Efficient Cascaded Training for Deep Unrolled Network in CT Imaging• Decoupled Classification Refinement: Hard False Positive Suppression for Object Detection• Quasi-universality in single-cell sequencing data• Deep Learning: Extrapolation Tool for Ab Initio Nuclear Theory• Intelligent Reflecting Surface Enhanced Wireless Network via Joint Active and Passive Beamforming• WiPIN: Operation-free Person Identification using WiFi Signals• Performance of distributed algorithms for QoS in wireless ad hoc networks: arbitrary networks under the primary interference model, and line networks under the protocol interference model• Multibeam for Joint Communication and Sensing Using Steerable Analog Antenna Arrays• Redundant Robot Assignment on Graphs with Uncertain Edge Costs• Solving the clustered traveling salesman problem with d-relaxed priority rule• Deep Geodesic Learning for Segmentation and Anatomical Landmarking• Spectral Resolution Clustering for Brain Parcellation• Hartley Spectral Pooling for Deep Learning• A computational study explaining processes underlying phase transition• Conversational Group Detection With Deep Convolutional Networks• Understanding and Improving Recurrent Networks for Human Activity Recognition by Continuous Attention• Gröbner bases and dimension formulas for ternary partially associative operads• Person-Job Fit: Adapting the Right Talent for the Right Job with Joint Representation Learning• Novel Massive MIMO Channel Sounding Data Applied to Deep Learning-based Indoor Positioning• Inter-BMV: Interpolation with Block Motion Vectors for Fast Semantic Segmentation on Video• (Di)graph decompositions and magic type labelings: a dual relation• Limitations of adversarial robustness: strong No Free Lunch Theorem• A linear algorithm for computing Polynomial Dynamical System• A Unified Dynamic Approach to Sparse Model Selection• Optimal Post-Detection Integration Technique for the Reacquisition of Weak GNSS Signals• The Viterbi process, decay-convexity and parallelized maximum a-posteriori estimation• Testing hyperbolicity of real polynomials• The 30-Year Cycle In The AI Debate• Convexity and Operational Interpretation of the Quantum Information Bottleneck Function• Overcoming Language Priors in Visual Question Answering with Adversarial Regularization• An ensemble based on a bi-objective evolutionary spectral algorithm for graph clustering• Joint Unsupervised Learning of Optical Flow and Depth by Watching Stereo Videos• Recognizing Overlapped Speech in Meetings: A Multichannel Separation Approach Using Neural Networks• Fluctuation lower bounds in planar random growth models• Approximation schemes for countably-infinite linear programs with moment bounds• DepecheMood++: a Bilingual Emotion Lexicon Built Through Simple Yet Powerful Techniques• Approximating Edit Distance Within Constant Factor in Truly Sub-Quadratic Time• Geometric Sensitivity Measures for Bayesian Nonparametric Density Estimation Models• Multi-agent Deep Reinforcement Learning for Zero Energy Communities• Binary Quadratic Forms in Difference Sets• SPDEs with fractional noise in space: continuity in law with respect to the Hurst index• Actor-Critic Deep Reinforcement Learning for Dynamic Multichannel Access• Stable Cluster Variables• Improving resource elasticity in cloud computing thanks to model-free control• Domain Transfer for 3D Pose Estimation from Color Images without Manual Annotations• Global Existence of Geometric Rough Flows• A Hybrid Approach for Trajectory Control Design• Taming a non-convex landscape with dynamical long-range order: memcomputing the Ising spin-glass• Design by adaptive sampling• The Incidental Parameters Problem in Testing for Remaining Cross-section Correlation• Saliency Prediction in the Deep Learning Era: An Empirical Investigation• Comparing Models of Associative Meaning: An Empirical Investigation of Reference in Simple Language Games• Optimal Memory-Anonymous Symmetric Deadlock-Free Mutual Exclusion• Optimal Steady-State Control for Linear Time-Invariant Systems• Data-Driven Load Modeling and Forecasting of Residential Appliances• Probabilistic Semantic Inpainting with Pixel Constrained CNNs• Efficient Non-parametric Bayesian Hawkes Processes• Exotic Springer fibers for orbits corresponding to one-row bipartitions• Random polymers via orthogonal Whittaker and symplectic Schur functions• Novel Single View Constraints for Manhattan 3D Line Reconstruction• Efficient Two-Step Adversarial Defense for Deep Neural Networks• Sunflowers of Convex Open Sets• Problem Solving at the Edge of Chaos: Entropy, Puzzles and the Sudoku Freezing Transition• Neural Networks Models for Analyzing Magic: the Gathering Cards• Deep residual networks for automatic sleep stage classification of raw polysomnographic waveforms• Balancing Global Exploration and Local-connectivity Exploitation with Rapidly-exploring Random disjointed-Trees• Restricted percolation critical exponents in high dimensions• Social Network Mediation Analysis: a Latent Space Approach• Coded Energy-Efficient Beam-Alignment for Millimeter-Wave Networks• SPIGAN: Privileged Adversarial Learning from Simulation• Thermodynamic Formalism for Topological Markov Chains on Borel Standard Spaces• A Summary of the 4th International Workshop on Recovering 6D Object Pose• Cubic Regularization with Momentum for Nonconvex Optimization• Generalized Latent Variable Recovery for Generative Adversarial Networks• Context-Aware Text-Based Binary Image Stylization and Synthesis• The existence of perfect codes in Doob graphs• Average Margin Regularization for Classifiers• Skeleton Driven Non-rigid Motion Tracking and 3D Reconstruction• Evaluating the Effectiveness of Health Awareness Events by Google Search Frequency• Unsupervised Online Video Object Segmentation with Motion Property Understanding• Information Geometry of Orthogonal Initializations and Training• Visual Localization of Key Positions for Visually Impaired People• A Note on Max $k$-Vertex Cover: Faster FPT-AS, Smaller Approximate Kernel and Improved Approximation• Collective Strategies with a Master-slave Mechanism Dominate in Spatial Iterated Prisoner’s Dilemma• The Outer Product Structure of Neural Network Derivatives• Geometry of the minimal spanning tree of a random $3$-regular graph• The Adversarial Attack and Detection under the Fisher Information Metric• A Dichotomy Theorem for First-Fit Chain Partitions• Synthesizing Stealthy Reprogramming Attacks on Cardiac Devices• Numerical study of ergodicity for the overdamped Generalized Langevin Equation with fractional noise• On the Relationship between Energy Complexity and Other Boolean Function Measures• Guess Free Maximization of Submodular and Linear Sums• SNAP: A semismooth Newton algorithm for pathwise optimization with optimal local convergence rate and oracle properties• Learning Bounds for Greedy Approximation with Explicit Feature Maps from Multiple Kernels• Sufficient and Necessary Conditions for the Identifiability of the $Q$-matrix• Knowing Where to Look? Analysis on Attention of Visual Question Answering System• Adaptive Minimax Regret against Smooth Logarithmic Losses over High-Dimensional $\ell_1$-Balls via Envelope Complexity• Lipschitz regularity for orthotropic functionals with nonstandard growth conditions• Realizing Learned Quadruped Locomotion Behaviors through Kinematic Motion Primitives• A Convex Optimization Approach to Dynamic Programming in Continuous State and Action Spaces• Sharp convergence of nonlinear functionals of a class of Gaussian random fields• Deep Attentive Tracking via Reciprocative Learning• Neural activity classification with machine learning models trained on interspike interval series data• Contraction-Based Sparsification in Near-Linear Time• A regularization method for the parameter estimation problem in ordinary differential equations via discrete optimal control theory• Functionally Modular and Interpretable Temporal Filtering for Robust Segmentation• On the Distance Identifying Set meta-problem and applications to the complexity of identifying problems on graphs• A sub-Finsler problem on the Cartan group• Conditional Generative Refinement Adversarial Networks for Unbalanced Medical Image Semantic Segmentation• Towards Verifying Semantic Roles Co-occurrence• Linear Codes Associated to Skew-symmetric Determinantal Varieties• Event Representation through Semantic Roles: Evaluation of Coverage• Continual State Representation Learning for Reinforcement Learning using Generative Replay• D-Optimal Design for the Rasch Counts Model with Multiple Binary Predictors• The H-force sets of the graphs satisfying the condition of Ore’s theorem• Iterative Decision Feedback Equalization Using Online Prediction• Packing chromatic vertex-critical graphs• Image Segmentation using Unsupervised Watershed Algorithm with an Over-segmentation Reduction Technique• Multi-scale uncertainty quantification in geostatistical seismic inversion• Projections of SDEs onto Submanifolds• Parallelizable Algorithms for Optimization Problems with Orthogonality Constraints• Modular, general purpose ODE integration package to solve large number of independent ODE systems on GPUs• Distinguishing infinite graphs with bounded degrees• Chimeras in digital phase-locked loops• 3D model silhouette-based tracking in depth images for puppet suit dynamic video-mapping• Collective evolution of weights in wide neural networks• Towards Two-Dimensional Sequence to Sequence Model in Neural Machine Translation• Explicit optimal-length locally repairable codes of distance 5• High-performance Power Allocation Strategies for Secure Spatial Modulation• Brezis pseudomonotonicity is strictly weaker than Ky-Fan hemicontinuity• Learning Noun Cases Using Sequential Neural Networks• The combination of context information to enhance simple question answering• Strong geodetic number of complete bipartite graphs, crown graphs and hypercubes• Enumerating models of DNF faster: breaking the dependency on the formula size• Glioma Segmentation with Cascaded Unet• Spatial moments for high-dimensional critical contact process, oriented percolation and lattice trees• Learning Converged Propagations with Deep Prior Ensemble for Image Enhancement• Comparison of U-net-based Convolutional Neural Networks for Liver Segmentation in CT• Selective Distillation of Weakly Annotated GTD for Vision-based Slab Identification System• Unifying the Dropout Family Through Structured Shrinkage Priors• Data-driven competitive facilitative tree interactions and their implications on nature-based solutions• A Distributed Reinforcement Learning Solution With Knowledge Transfer Capability for A Bike Rebalancing Problem• Dynamic Optimization with Convergence Guarantees• To Use or Not to Use: CPUs’ Cache Optimization Techniques on GPGPUs• Deep learning with differential Gaussian process flows• Limitations of the asymptotic approach to dynamics• MMS-type problems for Johnson scheme• A universal university ranking from the preferences of the applicants• Statistical Convergence of the EM Algorithm on Gaussian Mixture Models• Geometry meets semantics for semi-supervised monocular depth estimation• A three-stage model for short-term extreme wind speed probabilistic forecasting• Characterization of Convex Objective Functions and Optimal Expected Convergence Rates for SGD• Image Captioning as Neural Machine Translation Task in SOCKEYE• Detecting object region and working state of aerator based on computer vision and machine learning• MPI Windows on Storage for HPC Applications• Ranking News-Quality Multimedia• Bijections Between Łukasiewicz Walks and Generalized Tandem Walks• Semi-supervised Deep Reinforcement Learning in Support of IoT and Smart City Services• Matrix-free construction of HSS representation using adaptive randomized sampling• Learning One-hidden-layer Neural Networks under General Input Distributions• Child Mortality Estimation Incorporating Summary Birth History Data• A Fast, Compact, Accurate Model for Language Identification of Codemixed Text• Decoupled Strategy for Imbalanced Workloads in MapReduce Frameworks• Entropic GANs meet VAEs: A Statistical Approach to Compute Sample Likelihoods in GANs• Exploring the Vision Processing Unit as Co-processor for Inference• Doubly Reparameterized Gradient Estimators for Monte Carlo Objectives• Seeing Beyond Appearance – Mapping Real Images into Geometrical Domains for Unsupervised CAD-based Recognition
Like this:
Like Loading…
Related