Python continues to lead the way when it comes to Machine Learning, AI, Deep Learning and Data Science tasks. According to builtwith.com, 45% of technology companies prefer to use Python for implementing AI and Machine Learning.
Because of this, we’ve decided to start a series investigating the top Python libraries across several categories:
Top 8 Python Machine Learning Libraries ✅
Top X Python AI Libraries – COMING SOON!
Top X Python Deep Learning Libraries - COMING SOON!
Top X Python Data Science Libraries – COMING SOON!
Of course, these lists are entirely subjective as many libraries could easily place in multiple categories. For example, Keras is included in this list but TensorFlow has been omitted and features in the Deep Learning library collection instead. This is because Keras is more of an ‘end-user’ library like SKLearn, as opposed to TensorFlow which appeals more to researchers and Machine Learning engineer types.
As always, please feel free to vent your frustrations/disagreements/annoyance in the comments section below!
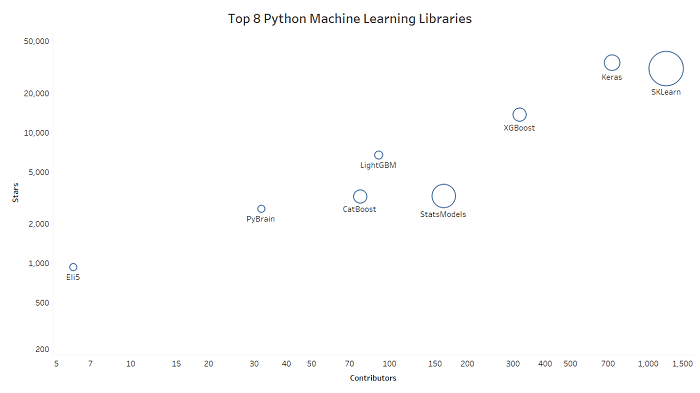
Top 8 Python Machine Learning Libraries by GitHub Contributors, Stars and Commits (size of the circle)
Now, let’s get onto the list (GitHub figures correct as of October 3rd, 2018):
1. scikit-learn (Contributors – 1175, Commits – 23301, Stars – 30867)
“scikit-learn is a Python module for machine learning built on NumPy, SciPy and matplotlib. It provides simple and efficient tools for data mining and data analysis. SKLearn is accessible to everybody and reusable in various contexts.
2. Keras (Contributors – 726, Commits – 4818, Stars – 34066)
“Keras is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano. It was developed with a focus on enabling fast experimentation. Being able to go from idea to result with the least possible delay is key to doing good research.”
3. XGBoost (Contributors – 319, Commits – 3454, Stars – 13630)
“XGBoost is an optimized distributed gradient boosting library designed to be highly efficient, flexible and portable. It implements machine learning algorithms under the Gradient Boosting framework. XGBoost provides a parallel tree boosting (also known as GBDT, GBM) that solve many data science problems in a fast and accurate way. The same code runs on major distributed environment (Hadoop, SGE, MPI) and can solve problems beyond billions of examples.”
4. StatsModels (Contributors – 162, Commits – 10837, Stars – 3275)
“Statsmodels is a Python package that provides a complement to scipy for statistical computations including descriptive statistics and estimation and inference for statistical models.”
5. LightGBM (Contributors – 91, Commits – 1272, Stars – 6736)
“A fast, distributed, high performance gradient boosting (GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning tasks. It is under the umbrella of the DMTK(http://github.com/microsoft/dmtk) project of Microsoft.”
6. CatBoost (Contributors – 77, Commits – 3304, Stars – 3241)
“CatBoost is a machine learning method based on gradient boosting over decision trees. Some of the main advantages of CatBoost are: superior quality when compared with other GBDT libraries, best in class inference speed, support for both numerical and categorical features and data visualization tools included.”
7. PyBrain (Contributors – 32, Commits – 992, Stars – 2598)
“PyBrain is a modular Machine Learning Library for Python. Its goal is to offer flexible, easy-to-use yet still powerful algorithms for Machine Learning Tasks and a variety of predefined environments to test and compare your algorithms.”
8. Eli5 (Contibutors – 6, Commits – 929, Stars – 932)
“ELI5 is a Python package which helps to debug machine learning classifiers and explain their predictions. It provides support for the following frameworks and packages: scikit-learn, XGBoost, LightGBM, lightning and sklearn-crfsuite.”
Keep an eye out for the rest of this series which will be published over the next few weeks!
Related: