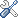
| Paris Machine Learning ( MLParis.org ) **@Meetup.com (6774 members) | @archives | @LinkedIn (1975) | @Google+(522) | @Facebook (388) | @Twitter (2312 followers) ** |
### A Neural Architecture for Bayesian CompressiveSensing over the Simplex via Laplace Techniques
Dear Igor,
I’m a long-time reader of your blog and wanted to share our recent paper on a relation between compressed sensing and neural network architectures. The paper introduces a new network construction based on the Laplace transform that results in activations such as ReLU and gating/threshold functions. It would be great if you could distribute the link on nuit-blanche.
The paper/preprint is here:https://ieeexplore.ieee.org/document/8478823https://www.netit.tu-berlin.de/fileadmin/fg314/limmer/LimSta18.pdf
Many thanks and best regards,Steffen
Dipl.-Ing. Univ. Steffen LimmerRaum HFT-TA 412Technische Universität BerlinInstitut für TelekommunikationssystemeFachgebiet Netzwerk-InformationstheorieEinsteinufer 25, 10587 Berlin
This paper presents a theoretical and conceptual framework to design neural architectures for Bayesian compressive sensing of simplex-constrained sparse stochastic vectors. First we recast the problem of MMSE estimation (w.r.t. a pre-defined uniform input distribution over the simplex) as the problem of computing the centroid of a polytope that is equal to the intersection of the simplex and an affine subspace determined by compressive measurements. Then we use multidimensional Laplace techniques to obtain a closed-form solution to this computation problem, and we show how to map this solution to a neural architecture comprising threshold functions, rectified linear (ReLU) and rectified polynomial (ReP) activation functions. In the proposed architecture, the number of layers is equal to the number of measurements which allows for faster solutions in the low-measurement regime when compared to the integration by domain decomposition or Monte-Carlo approximation. We also show by simulation that the proposed solution is robust to small model mismatches; furthermore, the proposed architecture yields superior approximations with less parameters when compared to a standard ReLU architecture in a supervised learning setting.

Printfriendly
Nuit Blanche community:@Google+ , @Facebook and @RedditCompressive Sensing community @LinkedInAdvanced Matrix Factorization community @Linkedin
Paris Machine Learning @Meetup.com, @archives, @LinkedIn , @Facebook,@Google+, @Twitter
Search Nuit Blanche
Subscribe by E-MAIL to Nuit Blanche
Contact me:
Popular Posts
Pages
Subscribe to the LinkedIn Matrix Factorization Group

Subscribe to the LinkedIn Compressive Sensing group
![]()
Nuit Blanche QR code
Readership Statistics



More than 838 readers receive every entries in their mailboxes while more than
There are more detailed information in the following blog entries.
So far, this site has seen more than 5,400,000 pageviews since a counter was installed in 2007.
Nuit Blanche Referenced in the Dead Tree World!
If You Like It, Link To It
Another Blog List
Search Pages I Link To
Previous Entries
Books Wish List

Books Wish List
Start-ups we like
Focused Interest
Categories/Subjects of Interest
Other sites of interest / Blogroll
