Contextual Multi-Armed Bandits for Causal Marketing
This work explores the idea of a causal contextual multi-armed bandit approach to automated marketing, where we estimate and optimize the causal (incremental) effects. Focusing on causal effect leads to better return on investment (ROI) by targeting only the persuadable customers who wouldn’t have taken the action organically. Our approach draws on strengths of causal inference, uplift modeling, and multi-armed bandits. It optimizes on causal treatment effects rather than pure outcome, and incorporates counterfactual generation within data collection. Following uplift modeling results, we optimize over the incremental business metric. Multi-armed bandit methods allow us to scale to multiple treatments and to perform off-policy policy evaluation on logged data. The Thompson sampling strategy in particular enables exploration of treatments on similar customer contexts and materialization of counterfactual outcomes. Preliminary offline experiments on a retail Fashion marketing dataset show merits of our proposal.
GINN: Geometric Illustration of Neural Networks
Inhibited Softmax for Uncertainty Estimation in Neural Networks
We present a new method for uncertainty estimation and out-of-distribution detection in neural networks with softmax output. We extend softmax layer with an additional constant input. The corresponding additional output is able to represent the uncertainty of the network. The proposed method requires neither additional parameters nor multiple forward passes nor input preprocessing nor out-of-distribution datasets. We show that our method performs comparably to more computationally expensive methods and outperforms baselines on our experiments from image recognition and sentiment analysis domains.
Deep processing of structured data
We construct a general unified framework for learning representation of structured data, i.e. data which cannot be represented as the fixed-length vectors (e.g. sets, graphs, texts or images of varying sizes). The key factor is played by an intermediate network called SAN (Set Aggregating Network), which maps a structured object to a fixed length vector in a high dimensional latent space. Our main theoretical result shows that for sufficiently large dimension of the latent space, SAN is capable of learning a unique representation for every input example. Experiments demonstrate that replacing pooling operation by SAN in convolutional networks leads to better results in classifying images with different sizes. Moreover, its direct application to text and graph data allows to obtain results close to SOTA, by simpler networks with smaller number of parameters than competitive models.
Machine Learning Suites for Online Toxicity Detection
To identify and classify toxic online commentary, the modern tools of data science transform raw text into key features from which either thresholding or learning algorithms can make predictions for monitoring offensive conversations. We systematically evaluate 62 classifiers representing 19 major algorithmic families against features extracted from the Jigsaw dataset of Wikipedia comments. We compare the classifiers based on statistically significant differences in accuracy and relative execution time. Among these classifiers for identifying toxic comments, tree-based algorithms provide the most transparently explainable rules and rank-order the predictive contribution of each feature. Among 28 features of syntax, sentiment, emotion and outlier word dictionaries, a simple bad word list proves most predictive of offensive commentary.
Combining Natural Gradient with Hessian Free Methods for Sequence Training
This paper presents a new optimisation approach to train Deep Neural Networks (DNNs) with discriminative sequence criteria. At each iteration, the method combines information from the Natural Gradient (NG) direction with local curvature information of the error surface that enables better paths on the parameter manifold to be traversed. The method is derived using an alternative derivation of Taylor’s theorem using the concepts of manifolds, tangent vectors and directional derivatives from the perspective of Information Geometry. The efficacy of the method is shown within a Hessian Free (HF) style optimisation framework to sequence train both standard fully-connected DNNs and Time Delay Neural Networks as speech recognition acoustic models. It is shown that for the same number of updates the proposed approach achieves larger reductions in the word error rate (WER) than both NG and HF, and also leads to a lower WER than standard stochastic gradient descent. The paper also addresses the issue of over-fitting due to mismatch between training criterion and Word Error Rate (WER) that primarily arises during sequence training of ReLU-DNN models.
Relaxed Quantization for Discretized Neural Networks
Neural network quantization has become an important research area due to its great impact on deployment of large models on resource constrained devices. In order to train networks that can be effectively discretized without loss of performance, we introduce a differentiable quantization procedure. Differentiability can be achieved by transforming continuous distributions over the weights and activations of the network to categorical distributions over the quantization grid. These are subsequently relaxed to continuous surrogates that can allow for efficient gradient-based optimization. We further show that stochastic rounding can be seen as a special case of the proposed approach and that under this formulation the quantization grid itself can also be optimized with gradient descent. We experimentally validate the performance of our method on MNIST, CIFAR 10 and Imagenet classification.
Spurious samples in deep generative models: bug or feature?
Traditional wisdom in generative modeling literature is that spurious samples that a model can generate are errors and they should be avoided. Recent research, however, has shown interest in studying or even exploiting such samples instead of eliminating them. In this paper, we ask the question whether such samples can be eliminated all together without sacrificing coverage of the generating distribution. For the class of models we consider, we experimentally demonstrate that this is not possible without losing the ability to model some of the test samples. While our results need to be confirmed on a broader set of model families, these initial findings provide partial evidence that spurious samples share structural properties with the learned dataset, which, in turn, suggests they are not simply errors but a feature of deep generative nets.
Real-time Clustering Algorithm Based on Predefined Level-of-Similarity
This paper proposes a centroid-based clustering algorithm which is capable of clustering data-points with n-features in real-time, without having to specify the number of clusters to be formed. We present the core logic behind the algorithm, a similarity measure, which collectively decides whether to assign an incoming data-point to a pre-existing cluster, or create a new cluster & assign the data-point to it. The implementation of the proposed algorithm clearly demonstrates how efficiently a data-point with high dimensionality of features is assigned to an appropriate cluster with minimal operations. The proposed algorithm is very application specific and is applicable when the need is perform clustering analysis of real-time data-points, where the similarity measure between an incoming data-point and the cluster to which the data-point is to be associated with, is greater than predefined Level-of-Similarity.
Generalized Inverse Optimization through Online Learning
Automatic Generation of Adaptive Network Models based on Similarity to the Desired Complex Network
Complex networks have become powerful mechanisms for studying a variety of realworld systems. Consequently, many human-designed network models are proposed that reproduce nontrivial properties of complex networks, such as long-tail degree distribution or high clustering coefficient. Therefore, we may utilize network models in order to generate graphs similar to desired networks. However, a desired network structure may deviate from emerging structure of any generative model, because no selected single model may support all the needed properties of the target graph and instead, each network model reflects a subset of the required features. In contrast to the classical approach of network modeling, an appropriate modern network model should adapt the desired features of the target network. In this paper, we propose an automatic approach for constructing network models that are adapted to the desired network features. We employ Genetic Algorithms in order to evolve network models based on the characteristics of the target networks. The experimental evaluations show that our proposed framework, called NetMix, results network models that outperform baseline models according to the compliance with the desired features of the target networks.
PADDIT: Probabilistic Augmentation of Data using Diffeomorphic Image Transformation
For proper generalization performance of convolutional neural networks (CNNs) in medical image segmentation, the learnt features should be invariant under particular non-linear shape variations of the input. To induce invariance in CNNs to such transformations, we propose Probabilistic Augmentation of Data using Diffeomorphic Image Transformation (PADDIT) — a systematic framework for generating realistic transformations that can be used to augment data for training CNNs. We show that CNNs trained with PADDIT outperforms CNNs trained without augmentation and with generic augmentation in segmenting white matter hyperintensities from T1 and FLAIR brain MRI scans.
Comparison of Reinforcement Learning algorithms applied to the Cart Pole problem
Designing optimal controllers continues to be challenging as systems are becoming complex and are inherently nonlinear. The principal advantage of reinforcement learning (RL) is its ability to learn from the interaction with the environment and provide optimal control strategy. In this paper, RL is explored in the context of control of the benchmark cartpole dynamical system with no prior knowledge of the dynamics. RL algorithms such as temporal-difference, policy gradient actor-critic, and value function approximation are compared in this context with the standard LQR solution. Further, we propose a novel approach to integrate RL and swing-up controllers.
AI Fairness 360: An Extensible Toolkit for Detecting, Understanding, and Mitigating Unwanted Algorithmic Bias
Semiparametric Regression using Variational Approximations
Semiparametric regression offers a flexible framework for modeling non-linear relationships between a response and covariates. A prime example are generalized additive models where splines (say) are used to approximate non-linear functional components in conjunction with a quadratic penalty to control for overfitting. Estimation and inference are then generally performed based on the penalized likelihood, or under a mixed model framework. The penalized likelihood framework is fast but potentially unstable, and choosing the smoothing parameters needs to be done externally using cross-validation, for instance. The mixed model framework tends to be more stable and offers a natural way for choosing the smoothing parameters, but for non-normal responses involves an intractable integral. In this article, we introduce a new framework for semiparametric regression based on variational approximations. The approach possesses the stability and natural inference tools of the mixed model framework, while achieving computation times comparable to using penalized likelihood. Focusing on generalized additive models, we derive fully tractable variational likelihoods for some common response types. We present several features of the variational approximation framework for inference, including a variational information matrix for inference on parametric components, and a closed-form update for estimating the smoothing parameter. We demonstrate the consistency of the variational approximation estimates, and an asymptotic normality result for the parametric component of the model. Simulation studies show the variational approximation framework performs similarly to and sometimes better than currently available software for fitting generalized additive models.
Learning Scheduling Algorithms for Data Processing Clusters
Efficiently scheduling data processing jobs on distributed compute clusters requires complex algorithms. Current systems, however, use simple generalized heuristics and ignore workload structure, since developing and tuning a bespoke heuristic for each workload is infeasible. In this paper, we show that modern machine learning techniques can generate highly-efficient policies automatically. Decima uses reinforcement learning (RL) and neural networks to learn workload-specific scheduling algorithms without any human instruction beyond specifying a high-level objective such as minimizing average job completion time. Off-the-shelf RL techniques, however, cannot handle the complexity and scale of the scheduling problem. To build Decima, we had to develop new representations for jobs’ dependency graphs, design scalable RL models, and invent new RL training methods for continuous job arrivals. Our prototype integration with Spark on a 25-node cluster shows that Decima outperforms several heuristics, including hand-tuned ones, by at least 21%. Further experiments with an industrial production workload trace demonstrate that Decima delivers up to a 17% reduction in average job completion time and scales to large clusters.
Verification for Machine Learning, Autonomy, and Neural Networks Survey
This survey presents an overview of verification techniques for autonomous systems, with a focus on safety-critical autonomous cyber-physical systems (CPS) and subcomponents thereof. Autonomy in CPS is enabling by recent advances in artificial intelligence (AI) and machine learning (ML) through approaches such as deep neural networks (DNNs), embedded in so-called learning enabled components (LECs) that accomplish tasks from classification to control. Recently, the formal methods and formal verification community has developed methods to characterize behaviors in these LECs with eventual goals of formally verifying specifications for LECs, and this article presents a survey of many of these recent approaches.
Action Model Acquisition using LSTM
In the field of Automated Planning and Scheduling (APS), intelligent agents by virtue require an action model (blueprints of actions whose interleaved executions effectuates transitions of the system state) in order to plan and solve real world problems. It is, however, becoming increasingly cumbersome to codify this model, and is more efficient to learn it from observed plan execution sequences (training data). While the underlying objective is to subsequently plan from this learnt model, most approaches fall short as anything less than a flawless reconstruction of the underlying model renders it unusable in certain domains. This work presents a novel approach using long short-term memory (LSTM) techniques for the acquisition of the underlying action model. We use the sequence labelling capabilities of LSTMs to isolate from an exhaustive model set a model identical to the one responsible for producing the training data. This isolation capability renders our approach as an effective one.
Improving High Contention OLTP Performance via Transaction Scheduling
Research in transaction processing has made significant progress in improving the performance of multi-core in-memory transactional systems. However, the focus has mainly been on low-contention workloads. Modern transactional systems perform poorly on workloads with transactions accessing a few highly contended data items. We observe that most transactional workloads, including those with high contention, can be divided into clusters of data conflict-free transactions and a small set of residuals. In this paper, we introduce a new concurrency control protocol called Strife that leverages the above observation. Strife executes transactions in batches, where each batch is partitioned into clusters of conflict-free transactions and a small set of residual transactions. The conflict-free clusters are executed in parallel without any concurrency control, followed by executing the residual cluster either serially or with concurrency control. We present a low-overhead algorithm that partitions a batch of transactions into clusters that do not have cross-cluster conflicts and a small residual cluster. We evaluate Strife against the optimistic concurrency control protocol and several variants of two-phase locking, where the latter is known to perform better than other concurrency protocols under high contention, and show that Strife can improve transactional throughput by up to 2x. We also perform an in-depth micro-benchmark analysis to empirically characterize the performance and quality of our clustering algorithm
From Soft Classifiers to Hard Decisions: How fair can we be?
A popular methodology for building binary decision-making classifiers in the presence of imperfect information is to first construct a non-binary ‘scoring’ classifier that is calibrated over all protected groups, and then to post-process this score to obtain a binary decision. We study the feasibility of achieving various fairness properties by post-processing calibrated scores, and then show that deferring post-processors allow for more fairness conditions to hold on the final decision. Specifically, we show: 1. There does not exist a general way to post-process a calibrated classifier to equalize protected groups’ positive or negative predictive value (PPV or NPV). For certain ‘nice’ calibrated classifiers, either PPV or NPV can be equalized when the post-processor uses different thresholds across protected groups, though there exist distributions of calibrated scores for which the two measures cannot be both equalized. When the post-processing consists of a single global threshold across all groups, natural fairness properties, such as equalizing PPV in a nontrivial way, do not hold even for ‘nice’ classifiers. 2. When the post-processing is allowed to `defer’ on some decisions (that is, to avoid making a decision by handing off some examples to a separate process), then for the non-deferred decisions, the resulting classifier can be made to equalize PPV, NPV, false positive rate (FPR) and false negative rate (FNR) across the protected groups. This suggests a way to partially evade the impossibility results of Chouldechova and Kleinberg et al., which preclude equalizing all of these measures simultaneously. We also present different deferring strategies and show how they affect the fairness properties of the overall system. We evaluate our post-processing techniques using the COMPAS data set from 2016.
Seq2Slate: Re-ranking and Slate Optimization with RNNs
Ranking is a central task in machine learning and information retrieval. In this task, it is especially important to present the user with a slate of items that is appealing as a whole. This in turn requires taking into account interactions between items, since intuitively, placing an item on the slate affects the decision of which other items should be placed alongside it. In this work, we propose a sequence-to-sequence model for ranking called seq2slate. At each step, the model predicts the next item to place on the slate given the items already selected. The recurrent nature of the model allows complex dependencies between items to be captured directly in a flexible and scalable way. We show how to learn the model end-to-end from weak supervision in the form of easily obtained click-through data. We further demonstrate the usefulness of our approach in experiments on standard ranking benchmarks as well as in a real-world recommendation system.
Transfer Incremental Learning using Data Augmentation
Deep learning-based methods have reached state of the art performances, relying on large quantity of available data and computational power. Such methods still remain highly inappropriate when facing a major open machine learning problem, which consists of learning incrementally new classes and examples over time. Combining the outstanding performances of Deep Neural Networks (DNNs) with the flexibility of incremental learning techniques is a promising venue of research. In this contribution, we introduce Transfer Incremental Learning using Data Augmentation (TILDA). TILDA is based on pre-trained DNNs as feature extractor, robust selection of feature vectors in subspaces using a nearest-class-mean based technique, majority votes and data augmentation at both the training and the prediction stages. Experiments on challenging vision datasets demonstrate the ability of the proposed method for low complexity incremental learning, while achieving significantly better accuracy than existing incremental counterparts.
Gradient Descent Provably Optimizes Over-parameterized Neural Networks

Non-Convex Min-Max Optimization: Provable Algorithms and Applications in Machine Learning
Min-max saddle-point problems have broad applications in many tasks in machine learning, e.g., distributionally robust learning, learning with non-decomposable loss, or learning with uncertain data. Although convex-concave saddle-point problems have been broadly studied with efficient algorithms and solid theories available, it remains a challenge to design provably efficient algorithms for non-convex saddle-point problems, especially when the objective function involves an expectation or a large-scale finite sum. Motivated by recent literature on non-convex non-smooth minimization, this paper studies a family of non-convex min-max problems where the minimization component is non-convex (weakly convex) and the maximization component is concave. We propose a proximally guided stochastic subgradient method and a proximally guided stochastic variance-reduced method for expected and finite-sum saddle-point problems, respectively. We establish the computation complexities of both methods for finding a nearly stationary point of the corresponding minimization problem.
Towards Fast and Energy-Efficient Binarized Neural Network Inference on FPGA


Finding Solutions to Generative Adversarial Privacy
We present heuristics for solving the maximin problem induced by the generative adversarial privacy setting for linear and convolutional neural network (CNN) adversaries. In the linear adversary setting, we present a greedy algorithm for approximating the optimal solution for the privatizer, which performs better as the number of instances increases. We also provide an analysis of the algorithm to show that it not only removes the features most correlated with the private label first, but also preserves the prediction accuracy of public labels that are sufficiently independent of the features that are relevant to the private label. In the CNN adversary setting, we present a method of hiding selected information from the adversary while preserving the others through alternately optimizing the goals of the privatizer and the adversary using neural network backpropagation. We experimentally show that our method succeeds on a fixed adversary.
Dual Convolutional Neural Network for Graph of Graphs Link Prediction
Graphs are general and powerful data representations which can model complex real-world phenomena, ranging from chemical compounds to social networks; however, effective feature extraction from graphs is not a trivial task, and much work has been done in the field of machine learning and data mining. The recent advances in graph neural networks have made automatic and flexible feature extraction from graphs possible and have improved the predictive performance significantly. In this paper, we go further with this line of research and address a more general problem of learning with a graph of graphs (GoG) consisting of an external graph and internal graphs, where each node in the external graph has an internal graph structure. We propose a dual convolutional neural network that extracts node representations by combining the external and internal graph structures in an end-to-end manner. Experiments on link prediction tasks using several chemical network datasets demonstrate the effectiveness of the proposed method.
A Gaussian sequence approach for proving minimaxity: A Review
This paper reviews minimax best equivariant estimation in these invariant estimation problems: a location parameter, a scale parameter and a (Wishart) covariance matrix. We briefly review development of the best equivariant estimator as a generalized Bayes estimator relative to right invariant Haar measure in each case. Then we prove minimaxity of the best equivariant procedure by giving a least favorable prior sequence based on non-truncated Gaussian distributions. The results in this paper are all known, but we bring a fresh and somewhat unified approach by using, in contrast to most proofs in the literature, a smooth sequence of non truncated priors. This approach leads to some simplifications in the minimaxity proofs.
Longest Property-Preserved Common Factor



Semi-Supervised Methods for Out-of-Domain Dependency Parsing
Dependency parsing is one of the important natural language processing tasks that assigns syntactic trees to texts. Due to the wider availability of dependency corpora and improved parsing and machine learning techniques, parsing accuracies of supervised learning-based systems have been significantly improved. However, due to the nature of supervised learning, those parsing systems highly rely on the manually annotated training corpora. They work reasonably good on the in-domain data but the performance drops significantly when tested on out-of-domain texts. To bridge the performance gap between in-domain and out-of-domain, this thesis investigates three semi-supervised techniques for out-of-domain dependency parsing, namely co-training, self-training and dependency language models. Our approaches use easily obtainable unlabelled data to improve out-of-domain parsing accuracies without the need of expensive corpora annotation. The evaluations on several English domains and multi-lingual data show quite good improvements on parsing accuracy. Overall this work conducted a survey of semi-supervised methods for out-of-domain dependency parsing, where I extended and compared a number of important semi-supervised methods in a unified framework. The comparison between those techniques shows that self-training works equally well as co-training on out-of-domain parsing, while dependency language models can improve both in- and out-of-domain accuracies.
Distributed Reconfiguration of Maximal Independent Sets


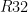


Monte Carlo Dependency Estimation
Estimating the dependency of variables is a fundamental task in data analysis. Identifying the relevant attributes in databases leads to better data understanding and also improves the performance of learning algorithms, both in terms of runtime and quality. In data streams, dependency monitoring provides key insights into the underlying process, but is challenging. In this paper, we propose Monte Carlo Dependency Estimation (MCDE), a theoretical framework to estimate multivariate dependency in static and dynamic data. MCDE quantifies dependency as the average discrepancy between marginal and conditional distributions via Monte Carlo simulations. Based on this framework, we present Mann-Whitney P (MWP), a novel dependency estimator. We show that MWP satisfies a number of desirable properties and can accommodate any kind of numerical data. We demonstrate the superiority of our estimator by comparing it to the state-of-the-art multivariate dependency measures.
Zooming Network
Structural information is important in natural language understanding. Although some current neural net-based models have a limited ability to take local syntactic information, they fail to use high-level and large-scale structures of documents. This information is valuable for text understanding since it contains the author’s strategy to express information, in building an effective representation and forming appropriate output modes. We propose a neural net-based model, Zooming Network, capable of representing and leveraging text structure of long document and developing its own analyzing rhythm to extract critical information. Generally, ZN consists of an encoding neural net that can build a hierarchical representation of a document, and an interpreting neural model that can read the information at multi-levels and issuing labeling actions through a policy-net. Our model is trained with a hybrid paradigm of supervised learning (distinguishing right and wrong decision) and reinforcement learning (determining the goodness among multiple right paths). We applied the proposed model to long text sequence labeling tasks, with performance exceeding baseline model (biLSTM-crf) by 10 F1-measure.
A Machine Learning-based Recommendation System for Swaptions Strategies
Derivative traders are usually required to scan through hundreds, even thousands of possible trades on a daily basis. Up to now, not a single solution is available to aid in their job. Hence, this work aims to develop a trading recommendation system, and apply this system to the so-called Mid-Curve Calendar Spread (MCCS), an exotic swaption-based derivatives package. In summary, our trading recommendation system follows this pipeline: (i) on a certain trade date, we compute metrics and sensitivities related to an MCCS; (ii) these metrics are feed in a model that can predict its expected return for a given holding period; and after repeating (i) and (ii) for all trades we (iii) rank the trades using some dominance criteria. To suggest that such approach is feasible, we used a list of 35 different types of MCCS; a total of 11 predictive models; and 4 benchmark models. Our results suggest that in general linear regression with lasso regularisation compared favourably to other approaches from a predictive and interpretability perspective.
On $k$-Maximal Submonoids, with Applications in Combinatorics on Words





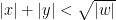
Revealing Network Structure, Confidentially: Improved Rates for Node-Private Graphon Estimation
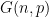
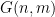
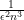
OPERA: Reasoning about continuous common knowledge in asynchronous distributed systems

Approximate Dynamic Programming with Probabilistic Temporal Logic Constraints
In this paper, we develop approximate dynamic programming methods for stochastic systems modeled as Markov Decision Processes, given both soft performance criteria and hard constraints in a class of probabilistic temporal logic called Probabilistic Computation Tree Logic (PCTL). Our approach consists of two steps: First, we show how to transform a class of PCTL formulas into chance constraints that can be enforced during planning in stochastic systems. Second, by integrating randomized optimization and entropy-regulated dynamic programming, we devise a novel trajectory sampling-based approximate value iteration method to iteratively solve for an upper bound on the value function while ensuring the constraints that PCTL specifications are satisfied. Particularly, we show that by the on-policy sampling of the trajectories, a tight bound can be achieved between the upper bound given by the approximation and the true value function. The correctness and efficiency of the method are demonstrated using robotic motion planning examples.
Accelerated Bayesian Additive Regression Trees
Although less widely known than random forests or boosted regression trees, Bayesian additive regression trees (BART) \citep{chipman2010bart} is a powerful predictive model that often outperforms those better-known alternatives at out-of-sample prediction. BART is especially well-suited to settings with unstructured predictor variables and substantial sources of unmeasured variation as is typical in the social, behavioral and health sciences. This paper develops a modified version of BART that is amenable to fast posterior estimation. We present a stochastic hill climbing algorithm that matches the remarkable predictive accuracy of previous BART implementations, but is orders of magnitude faster and uses a fraction of the memory. Simulation studies show that the new method is comparable in computation time and more accurate at function estimation than both random forests and gradient boosting.
Concept-drifting Data Streams are Time Series; The Case for Continuous Adaptation
Learning from data streams is an increasingly important topic in data mining, machine learning, and artificial intelligence in general. A major focus in the data stream literature is on designing methods that can deal with concept drift, a challenge where the generating distribution changes over time. A general assumption in most of this literature is that instances are independently distributed in the stream. In this work we show that, in the context of concept drift, this assumption is contradictory, and that the presence of concept drift necessarily implies temporal dependence; and thus some form of time series. This has important implications on model design and deployment. We explore and highlight the these implications, and show that Hoeffding-tree based ensembles, which are very popular for learning in streams, are not naturally suited to learning \emph{within} drift; and can perform in this scenario only at significant computational cost of destructive adaptation. On the other hand, we develop and parameterize gradient-descent methods and demonstrate how they can perform \emph{continuous} adaptation with no explicit drift-detection mechanism, offering major advantages in terms of accuracy and efficiency. As a consequence of our theoretical discussion and empirical observations, we outline a number of recommendations for deploying methods in concept-drifting streams.
Compound Binary Search Tree and Algorithms
The Binary Search Tree (BST) is average in computer science which supports a compact data structure in memory and oneself even conducts a row of quick algorithms, by which people often apply it in dynamical circumstance. Besides these edges, it is also with weakness on its own structure specially with poor performance at worst case. In this paper, we will develop this data structure into a synthesis to show a series of novel features residing in. Of that, there are new methods invented for raising the performance and efficiency nevertheless some existing ones in logarithm or linear time.
MyCaffe: A Complete C# Re-Write of Caffe with Reinforcement Learning
Over the past few years Caffe, from Berkeley AI Research, has gained a strong following in the deep learning community with over 15K forks on the github.com/BLVC/Caffe site. With its well organized, very modular C++ design it is easy to work with and very fast. However, in the world of Windows development, C# has helped accelerate development with many of the enhancements that it offers over C++, such as garbage collection, a very rich .NET programming framework and easy database access via Entity Frameworks. So how can a C# developer use the advances of C# to take full advantage of the benefits offered by the Berkeley Caffe deep learning system? The answer is the fully open source, ‘MyCaffe’ for Windows .NET programmers. MyCaffe is an open source, complete C# language re-write of Berkeley’s Caffe. This article describes the general architecture of MyCaffe including the newly added MyCaffeTrainerRL for Reinforcement Learning. In addition, this article discusses how MyCaffe closely follows the C++ Caffe, while talking efficiently to the low level NVIDIA CUDA hardware to offer a high performance, highly programmable deep learning system for Windows .NET programmers.
Markov Properties of Discrete Determinantal Point Processes
Determinantal point processes (DPPs) are probabilistic models for repulsion. When used to represent the occurrence of random subsets of a finite base set, DPPs allow to model global negative associations in a mathematically elegant and direct way. Discrete DPPs have become popular and computationally tractable models for solving several machine learning tasks that require the selection of diverse objects, and have been successfully applied in numerous real-life problems. Despite their popularity, the statistical properties of such models have not been adequately explored. In this note, we derive the Markov properties of discrete DPPs and show how they can be expressed using graphical models.
A Practical Approach to Sizing Neural Networks
Memorization is worst-case generalization. Based on MacKay’s information theoretic model of supervised machine learning, this article discusses how to practically estimate the maximum size of a neural network given a training data set. First, we present four easily applicable rules to analytically determine the capacity of neural network architectures. This allows the comparison of the efficiency of different network architectures independently of a task. Second, we introduce and experimentally validate a heuristic method to estimate the neural network capacity requirement for a given dataset and labeling. This allows an estimate of the required size of a neural network for a given problem. We conclude the article with a discussion on the consequences of sizing the network wrongly, which includes both increased computation effort for training as well as reduced generalization capability.
Unsupervised Learning via Meta-Learning
A central goal of unsupervised learning is to acquire representations from unlabeled data or experience that can be used for more effective learning of downstream tasks from modest amounts of labeled data. Many prior unsupervised learning works aim to do so by developing proxy objectives based on reconstruction, disentanglement, prediction, and other metrics. Instead, we develop an unsupervised learning method that explicitly optimizes for the ability to learn a variety of tasks from small amounts of data. To do so, we construct tasks from unlabeled data in an automatic way and run meta-learning over the constructed tasks. Surprisingly, we find that relatively simple mechanisms for task design, such as clustering unsupervised representations, lead to good performance on a variety of downstream tasks. Our experiments across four image datasets indicate that our unsupervised meta-learning approach acquires a learning algorithm without any labeled data that is applicable to a wide range of downstream classification tasks, improving upon the representation learned by four prior unsupervised learning methods.
• Compact packings of the plane with three sizes of discs• DATA Agent• A Multi-Face Challenging Dataset for Robust Face Recognition• Multi-directional Geodesic Neural Networks via Equivariant Convolution• LIT: Block-wise Intermediate Representation Training for Model Compression• On the stability of unstable states, bifurcation, chaos of nonlinear dynamic systems• Heuristic Optimization of Electrical Energy Systems: A Perpetual Motion Scheme and Refined Metrics to Compare the Solutions• Generating random networks that consist of a single connected component with a given degree distribution• A Comprehensive Approach for Learning-based Fully-Automated Inter-slice Motion Correction for Short-Axis Cine Cardiac MR Image Stacks• Agnostic Sample Compression for Linear Regression• Robust online identification of thermal models for in-production HPC clusters with machine learning-based data selection• Learning an internal representation of the end-effector configuration space• A Non-linear Approach to Space Dimension Perception by a Naive Agent• Grounding Perception: A Developmental Approach to Sensorimotor Contingencies• Grounding the Experience of a Visual Field through Sensorimotor Contingencies• Learning agent’s spatial configuration from sensorimotor invariants• Understanding Weight Normalized Deep Neural Networks with Rectified Linear Units• On-site surrogates for large-scale calibration• Light Localization and Cooperative Effects in Aperiodic Vogel Spirals• Fast Approach to Build an Automatic Sentiment Annotator for Legal Domain using Transfer Learning• Analysis of Diffractive Optical Neural Networks and Their Integration with Electronic Neural Networks• An FE-dABCD algorithm for elliptic optimal control problems with constraints on the gradient of the state and control• Bandit learning in concave $N$-person games• Procedural Puzzle Challenge Generation in Fujisan• Desynchronization and pattern formation in a noisy feedforward oscillators network• A Comparison of I/O-Efficient Algorithms for Visibility Computation on Massive Grid Terrains• Hindman’s finite sums theorem and its application to topologizations of algebras• CRED: A Deep Residual Network of Convolutional and Recurrent Units for Earthquake Signal Detection• Accuracy of Distance-Based Ranking of Users in the Analysis of NOMA Systems• CoverBLIP: accelerated and scalable iterative matched-filtering for Magnetic Resonance Fingerprint reconstruction• Algorithmic Polarization for Hidden Markov Models• Average connectivity of minimally 2-connected graphs and average edge-connectivity of minimally 2-edge-connected graphs• Sparse Winograd Convolutional neural networks on small-scale systolic arrays• Non-exponential Sanov and Schilder theorems on Wiener space: BSDEs, Schrödinger problems and Control• Surveyor Gender Modifies Average Survey Responses: Evidence from Household Surveys in Four Sub-Saharan African Countries• Discriminative Data-driven Self-adaptive Fraud Control Decision System with Incomplete Information• The Blackbird Dataset: A large-scale dataset for UAV perception in aggressive flight• Exascale Deep Learning for Climate Analytics• Image and Encoded Text Fusion for Multi-Modal Classification• Improving Community Detection by Mining Social Interactions• The Hamilton-Waterloo Problem with even cycle lengths• Domain Specific Approximation for Object Detection• Probabilistic Impact Assessment of Network Tariffs in Low Voltage Distribution Networks• The Four Point Permutation Test for Latent Block Structure in Incidence Matrices• Convergence of the Expectation-Maximization Algorithm Through Discrete-Time Lyapunov Stability Theory• Detecting DGA domains with recurrent neural networks and side information• Convergence to Second-Order Stationarity for Constrained Non-Convex Optimization• EP-based Joint Active User Detection and Channel Estimation for Massive Machine-Type Communications• Polar Feature Based Deep Architectures for Automatic Modulation Classification Considering Channel Fading• Robust Estimation and Generative Adversarial Nets• Gradient descent aligns the layers of deep linear networks• Gaussian approximation of Gaussian scale mixture• A statistical normalization method and differential expression analysis for RNA-seq data between different species• Counting unlabeled interval graphs• On connectivity, conductance and bootstrap percolation for a random k-out, age-biased graph• High-dimensional general linear hypothesis tests via non-linear spectral shrinkage• Convergence of a Solution Algorithm in Indefinite Quadratic Programming• Commutative linear logic as a multiple context-free grammar• Proceedings 11th Interaction and Concurrency Experience• Qualitative Properties of the Minimum Sum-of-Squares Clustering Problem• Turning Lemons into Peaches using Secure Computation• Chaos and relaxation oscillations in spin-torque windmill neurons• Unsupervised Adversarial Visual Level Domain Adaptation for Learning Video Object Detectors from Images• Transferring Physical Motion Between Domains for Neural Inertial Tracking• General drawdown of general tax model in a time-homogeneous Markov framework• On toric ideals arising from signed graphs• Designing Anti-Jamming Receivers for NR-DCSK Systems Utilizing ICA, WPD, and VMD Methods• Extremely Large Aperture Massive MIMO: Low Complexity Receiver Architectures• Temporal variation of the spectrum of continuously-pumped random fiber laser. Phenomenological model• Quantum nilpotent subalgebras of classical quantum groups and affine crystals• A framework for the comparison of different EEG acquisition solutions• Improving the Segmentation of Anatomical Structures in Chest Radiographs using U-Net with an ImageNet Pre-trained Encoder• Infill Criterion for Multimodal Model-Based Optimisation• A Proximal Diffusion Strategy for Multi-Agent Optimization with Sparse Affine Constraints• Learning Finer-class Networks for Universal Representations• Real Differences between OT and CRDT for Co-Editors• Unstable maps• Combinatorial study of graphs arising from the Sachdev-Ye-Kitaev model• Neural Networks for Cross-lingual Negation Scope Detection• Construction D$^\prime$ Lattices from Quasi-Cyclic Low-Density Parity-Check Codes• On the Performance of Space-Time MIMO Multiplexing for Free Space Optical Communications• Ergodic Capacity of Triple-Hop All-Optical Amplify-and-Forward Relaying over Free-Space Optical Channels• COMIT – Cryptographically-secure Off-chain Multi-asset Instant Transaction Network• Adaptive Policies for Perimeter Surveillance Problems• Berry-Esséen bound for the Parameter Estimation of Fractional Ornstein-Uhlenbeck Processes with the Hurst Parameter 0<H<1/2• Improved generalization bounds for robust learning• A Note on the Nash Equilibria of Some Multi-Player Reachability / Safety Games• Posterior contraction for empirical Bayesian approach to inverse problems under non-diagonal assumption• Randen – fast backtracking-resistant random generator with AES+Feistel+Reverie• Italian Event Detection Goes Deep Learning• Recursion schemes, discrete differential equations and characterization of polynomial time computation• Weisfeiler and Leman Go Neural: Higher-order Graph Neural Networks• A Span Selection Model for Semantic Role Labeling• A combinatorial formula for the Ehrhart $h^{*}$-vector of the hypersimplex• Convergence of the ADAM algorithm from a Dynamical System Viewpoint• Distinguishing locally finite trees• A Large-Scale Test Set for the Evaluation of Context-Aware Pronoun Translation in Neural Machine Translation• Episodic Curiosity through Reachability• Direct Prediction of Cardiovascular Mortality from Low-dose Chest CT using Deep Learning• A Convergence Analysis of Gradient Descent for Deep Linear Neural Networks• Averaging principle for two dimensional stochastic Navier-Stokes equations• Progressive Feature Fusion Network for Realistic Image Dehazing• ASIED: A Bayesian Adaptive Subgroup-Identification Enrichment Design• On the volumes and affine types of trades• Polynomial-time Recognition of 4-Steiner Powers• Global Solutions of Nonconvex Standard Quadratic Programs via Mixed Integer Linear Programming Reformulations• Learning Compressed Transforms with Low Displacement Rank• DER Allocation and Line Repair Scheduling for Storm-induced Failures in Distribution Networks• Information Market for Web Browsing: Design, Usability and Incremental Adoption• Computer vision-based framework for extracting geological lineaments from optical remote sensing data• Optimal Learning with Anisotropic Gaussian SVMs• Machine learning electron correlation in a disordered medium• A Microscopic Model of Holography: Survival by the Burden of Memory• Neural-Symbolic VQA: Disentangling Reasoning from Vision and Language Understanding• SNIP: Single-shot Network Pruning based on Connection Sensitivity• Multi-view X-ray R-CNN• Perron-Frobenius Theory in Nearly Linear Time: Positive Eigenvectors, M-matrices, Graph Kernels, and Other Applications• Efficient Representation of Topologically Ordered States with Restricted Boltzmann Machines• Map Memorization and Forgetting in the IARA Autonomous Car
Like this:
Like Loading…
Related