Elastic Neural Networks for Classification
In this work we propose a framework for improving the performance of any deep neural network that may suffer from vanishing gradients. To address the vanishing gradient issue, we study a framework, where we insert an intermediate output branch after each layer in the computational graph and use the corresponding prediction loss for feeding the gradient to the early layers. The framework – which we name Elastic network – is tested with several well-known networks on CIFAR10 and CIFAR100 datasets, and the experimental results show that the proposed framework improves the accuracy on both shallow networks (e.g., MobileNet) and deep convolutional neural networks (e.g., DenseNet). We also identify the types of networks where the framework does not improve the performance and discuss the reasons. Finally, as a side product, the computational complexity of the resulting networks can be adjusted in an elastic manner by selecting the output branch according to current computational budget.
Taming VAEs
In spite of remarkable progress in deep latent variable generative modeling, training still remains a challenge due to a combination of optimization and generalization issues. In practice, a combination of heuristic algorithms (such as hand-crafted annealing of KL-terms) is often used in order to achieve the desired results, but such solutions are not robust to changes in model architecture or dataset. The best settings can often vary dramatically from one problem to another, which requires doing expensive parameter sweeps for each new case. Here we develop on the idea of training VAEs with additional constraints as a way to control their behaviour. We first present a detailed theoretical analysis of constrained VAEs, expanding our understanding of how these models work. We then introduce and analyze a practical algorithm termed Generalized ELBO with Constrained Optimization, GECO. The main advantage of GECO for the machine learning practitioner is a more intuitive, yet principled, process of tuning the loss. This involves defining of a set of constraints, which typically have an explicit relation to the desired model performance, in contrast to tweaking abstract hyper-parameters which implicitly affect the model behavior. Encouraging experimental results in several standard datasets indicate that GECO is a very robust and effective tool to balance reconstruction and compression constraints.
Predicted Variables in Programming
We present Predicted Variables (PVars), an approach to making machine learning (ML) a first class citizen in programming languages. There is a growing divide in approaches to building systems: using human experts (e.g. programming) on the one hand, and using behavior learned from data (e.g. ML) on the other hand. PVars aim to make ML in programming as easy as `if’ statements and with that hybridize ML with programming. We leverage the existing concept of variables and create a new type, a predicted variable. PVars are akin to native variables with one important distinction: PVars determine their value using ML when evaluated. We describe PVars and their interface, how they can be used in programming, and demonstrate the feasibility of our approach on three algorithmic problems: binary search, Quicksort, and caches. We show experimentally that PVars are able to improve over the commonly used heuristics and lead to a better performance than the original algorithms. As opposed to previous work applying ML to algorithmic problems, PVars have the advantage that they can be used within the existing frameworks and do not require the existing domain knowledge to be replaced. PVars allow for a seamless integration of ML into existing systems and algorithms. Our PVars implementation currently relies on standard Reinforcement Learning (RL) methods. To learn faster, PVars use the heuristic function, which they are replacing, as an initial function. We show that PVars quickly pick up the behavior of the initial function and then improve performance beyond that without ever performing substantially worse — allowing for a safe deployment in critical applications.
Fusion Hashing: A General Framework for Self-improvement of Hashing
Hashing has been widely used for efficient similarity search based on its query and storage efficiency. To obtain better precision, most studies focus on designing different objective functions with different constraints or penalty terms that consider neighborhood information. In this paper, in contrast to existing hashing methods, we propose a novel generalized framework called fusion hashing (FH) to improve the precision of existing hashing methods without adding new constraints or penalty terms. In the proposed FH, given an existing hashing method, we first execute it several times to get several different hash codes for a set of training samples. We then propose two novel fusion strategies that combine these different hash codes into one set of final hash codes. Based on the final hash codes, we learn a simple linear hash function for the samples that can significantly improve model precision. In general, the proposed FH can be adopted in existing hashing method and achieve more precise and stable performance compared to the original hashing method with little extra expenditure in terms of time and space. Extensive experiments were performed based on three benchmark datasets and the results demonstrate the superior performance of the proposed framework
Perfect Match: A Simple Method for Learning Representations For Counterfactual Inference With Neural Networks
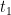
Rare event simulation for stochastic dynamics in continuous time
Large deviations for additive path functionals and convergence properties for numerical approaches based on population dynamics have attracted recent research interest. The aim of this paper is twofold. Extending results from the literature of particle filters and sequential Monte Carlo methods we can establish rigorous bounds on convergence properties of the cloning algorithm in continuous time, which are reported in this paper with details of proofs given in a further publication. Secondly, the tilted generator characterizing the large deviation rate function can be associated to non-linear processes which give rise to several representations of the dynamics and additional freedom for associated particle approximations. We discuss these choices in detail, and combine insights from the filtering literature and the cloning algorithm to suggest a more efficient version of the algorithm.
Counterfactually Fair Prediction Using Multiple Causal Models
In this paper we study the problem of making predictions using multiple structural casual models defined by different agents, under the constraint that the prediction satisfies the criterion of counterfactual fairness. Relying on the frameworks of causality, fairness and opinion pooling, we build upon and extend previous work focusing on the qualitative aggregation of causal Bayesian networks and causal models. In order to complement previous qualitative results, we devise a method based on Monte Carlo simulations. This method enables a decision-maker to aggregate the outputs of the causal models provided by different experts while guaranteeing the counterfactual fairness of the result. We demonstrate our approach on a simple, yet illustrative, toy case study.
Classification Using Link Prediction
Link prediction in a graph is the problem of detecting the missing links that would be formed in the near future. Using a graph representation of the data, we can convert the problem of classification to the problem of link prediction which aims at finding the missing links between the unlabeled data (unlabeled nodes) and their classes. To our knowledge, despite the fact that numerous algorithms use the graph representation of the data for classification, none are using link prediction as the heart of their classifying procedure. In this work, we propose a novel algorithm called CULP (Classification Using Link Prediction) which uses a new structure namely Label Embedded Graph or LEG and a link predictor to find the class of the unlabeled data. Different link predictors along with Compatibility Score – a new link predictor we proposed that is designed specifically for our settings – has been used and showed promising results for classifying different datasets. This paper further improved CULP by designing an extension called CULM which uses a majority vote (hence the M in the acronym) procedure with weights proportional to the predictions’ confidences to use the predictive power of multiple link predictors and also exploits the low level features of the data. Extensive experimental evaluations shows that both CULP and CULM are highly accurate and competitive with the cutting edge graph classifiers and general classifiers.
The Profiling Machine: Active Generalization over Knowledge
The human mind is a powerful multifunctional knowledge storage and management system that performs generalization, type inference, anomaly detection, stereotyping, and other tasks. A dynamic KR system that appropriately profiles over sparse inputs to provide complete expectations for unknown facets can help with all these tasks. In this paper, we introduce the task of profiling, inspired by theories and findings in social psychology about the potential of profiles for reasoning and information processing. We describe two generic state-of-the-art neural architectures that can be easily instantiated as profiling machines to generate expectations and applied to any kind of knowledge to fill gaps. We evaluate these methods against Wikidata and crowd expectations, and compare the results to gain insight in the nature of knowledge captured by various profiling methods. We make all code and data available to facilitate future research.
On Theory for BART
Ensemble learning is a statistical paradigm built on the premise that many weak learners can perform exceptionally well when deployed collectively. The BART method of Chipman et al. (2010) is a prominent example of Bayesian ensemble learning, where each learner is a tree. Due to its impressive performance, BART has received a lot of attention from practitioners. Despite its wide popularity, however, theoretical studies of BART have begun emerging only very recently. Laying the foundations for the theoretical analysis of Bayesian forests, Rockova and van der Pas (2017) showed optimal posterior concentration under conditionally uniform tree priors. These priors deviate from the actual priors implemented in BART. Here, we study the exact BART prior and propose a simple modification so that it also enjoys optimality properties. To this end, we dive into branching process theory. We obtain tail bounds for the distribution of total progeny under heterogeneous Galton-Watson (GW) processes exploiting their connection to random walks. We conclude with a result stating the optimal rate of posterior convergence for BART.
Graph Diffusion-Embedding Networks
We present a novel graph diffusion-embedding networks (GDEN) for graph structured data. GDEN is motivated by our closed-form formulation on regularized feature diffusion on graph. GDEN integrates both regularized feature diffusion and low-dimensional embedding simultaneously in a unified network model. Moreover, based on GDEN, we can naturally deal with structured data with multiple graph structures. Experiments on semi-supervised learning tasks on several benchmark datasets demonstrate the better performance of the proposed GDEN when comparing with the traditional GCN models.
How Powerful are Graph Neural Networks?
Graph Neural Networks (GNNs) for representation learning of graphs broadly follow a neighborhood aggregation framework, where the representation vector of a node is computed by recursively aggregating and transforming feature vectors of its neighboring nodes. Many GNN variants have been proposed and have achieved state-of-the-art results on both node and graph classification tasks. However, despite GNNs revolutionizing graph representation learning, there is limited understanding of their representational properties and limitations. Here, we present a theoretical framework for analyzing the expressive power of GNNs in capturing different graph structures. Our results characterize the discriminative power of popular GNN variants, such as Graph Convolutional Networks and GraphSAGE, and show that they cannot learn to distinguish certain simple graph structures. We then develop a simple architecture that is provably the most expressive among the class of GNNs and is as powerful as the Weisfeiler-Lehman graph isomorphism test. We empirically validate our theoretical findings on a number of graph classification benchmarks, and demonstrate that our model achieves state-of-the-art performance.
Integrated Principal Components Analysis
Data integration, or the strategic analysis of multiple sources of data simultaneously, can often lead to discoveries that may be hidden in individualistic analyses of a single data source. We develop a new statistical data integration method named Integrated Principal Components Analysis (iPCA), which is a model-based generalization of PCA and serves as a practical tool to find and visualize common patterns that occur in multiple datasets. The key idea driving iPCA is the matrix-variate normal model, whose Kronecker product covariance structure captures both individual patterns within each dataset and joint patterns shared by multiple datasets. Building upon this model, we develop several penalized (sparse and non-sparse) covariance estimators for iPCA and study their theoretical properties. We show that our sparse iPCA estimator consistently estimates the underlying joint subspace, and using geodesic convexity, we prove that our non-sparse iPCA estimator converges to the global solution of a non-convex problem. We also demonstrate the practical advantages of iPCA through simulations and a case study application to integrative genomics for Alzheimer’s Disease. In particular, we show that the joint patterns extracted via iPCA are highly predictive of a patient’s cognition and Alzheimer’s diagnosis.
Challenges of Using Text Classifiers for Causal Inference
Causal understanding is essential for many kinds of decision-making, but causal inference from observational data has typically only been applied to structured, low-dimensional datasets. While text classifiers produce low-dimensional outputs, their use in causal inference has not previously been studied. To facilitate causal analyses based on language data, we consider the role that text classifiers can play in causal inference through established modeling mechanisms from the causality literature on missing data and measurement error. We demonstrate how to conduct causal analyses using text classifiers on simulated and Yelp data, and discuss the opportunities and challenges of future work that uses text data in causal inference.
Neural Regression Trees
Regression-via-Classification (RvC) is the process of converting a regression problem to a classification one. Current approaches for RvC use ad-hoc discretization strategies and are suboptimal. We propose a neural regression tree model for RvC. In this model, we employ a joint optimization framework where we learn optimal discretization thresholds while simultaneously optimizing the features for each node in the tree. We empirically show the validity of our model by testing it on two challenging regression tasks where we establish the state of the art.
plsRglm: Partial least squares linear and generalized linear regression for processing incomplete datasets by cross-validation and bootstrap techniques with R
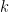
Feature Selection Approach with Missing Values Conducted for Statistical Learning: A Case Study of Entrepreneurship Survival Dataset
In this article, we investigate the features which enhanced discriminate the survival in the micro and small business (MSE) using the approach of data mining with feature selection. According to the complexity of the data set, we proposed a comparison of three data imputation methods such as mean imputation (MI), k-nearest neighbor (KNN) and expectation maximization (EM) using mutually the selection of variables technique, whereby t-test, then through the data mining process using logistic regression classification methods, naive Bayes algorithm, linear discriminant analysis and support vector machine hence comparing their respective performances. The experimental results will be spread in developing a model to predict the MSE survival, providing a better understanding in the topic once it is a significant part of the Brazilian’ GPA and macroeconomy.
A flexible sequential Monte Carlo algorithm for shape-constrained regression
We propose an algorithm that is capable of imposing shape constraints on regression curves, without requiring the constraints to be written as closed-form expressions, nor assuming the functional form of the loss function. Our algorithm, which is based on Sequential Monte Carlo-Simulated Annealing, only relies on an indicator function that assesses whether or not the constraints are fulfilled, thus allowing us to enforce various complex constraints by specifying an appropriate indicator function without altering other parts of the algorithm. We demonstrate our algorithm by fitting rational function models subject to monotonicity and continuity constraints. The algorithm was implemented using R (R Core Team, 2018) and the code is freely available on GitHub.
Target Aware Network Adaptation for Efficient Representation Learning
This paper presents an automatic network adaptation method that finds a ConvNet structure well-suited to a given target task, e.g., image classification, for efficiency as well as accuracy in transfer learning. We call the concept target-aware transfer learning. Given only small-scale labeled data, and starting from an ImageNet pre-trained network, we exploit a scheme of removing its potential redundancy for the target task through iterative operations of filter-wise pruning and network optimization. The basic motivation is that compact networks are on one hand more efficient and should also be more tolerant, being less complex, against the risk of overfitting which would hinder the generalization of learned representations in the context of transfer learning. Further, unlike existing methods involving network simplification, we also let the scheme identify redundant portions across the entire network, which automatically results in a network structure adapted to the task at hand. We achieve this with a few novel ideas: (i) cumulative sum of activation statistics for each layer, and (ii) a priority evaluation of pruning across multiple layers. Experimental results by the method on five datasets (Flower102, CUB200-2011, Dog120, MIT67, and Stanford40) show favorable accuracies over the related state-of-the-art techniques while enhancing the computational and storage efficiency of the transferred model.
AI Benchmark: Running Deep Neural Networks on Android Smartphones
Over the last years, the computational power of mobile devices such as smartphones and tablets has grown dramatically, reaching the level of desktop computers available not long ago. While standard smartphone apps are no longer a problem for them, there is still a group of tasks that can easily challenge even high-end devices, namely running artificial intelligence algorithms. In this paper, we present a study of the current state of deep learning in the Android ecosystem and describe available frameworks, programming models and the limitations of running AI on smartphones. We give an overview of the hardware acceleration resources available on four main mobile chipset platforms: Qualcomm, HiSilicon, MediaTek and Samsung. Additionally, we present the real-world performance results of different mobile SoCs collected with AI Benchmark that are covering all main existing hardware configurations.
Sinkhorn AutoEncoders
Optimal Transport offers an alternative to maximum likelihood for learning generative autoencoding models. We show how this principle dictates the minimization of the Wasserstein distance between the encoder aggregated posterior and the prior, plus a reconstruction error. We prove that in the non-parametric limit the autoencoder generates the data distribution if and only if the two distributions match exactly, and that the optimum can be obtained by deterministic autoencoders. We then introduce the Sinkhorn AutoEncoder (SAE), which casts the problem into Optimal Transport on the latent space. The resulting Wasserstein distance is minimized by backpropagating through the Sinkhorn algorithm. SAE models the aggregated posterior as an implicit distribution and therefore does not need a reparameterization trick for gradients estimation. Moreover, it requires virtually no adaptation to different prior distributions. We demonstrate its flexibility by considering models with hyperspherical and Dirichlet priors, as well as a simple case of probabilistic programming. SAE matches or outperforms other autoencoding models in visual quality and FID scores.
Robust Optimization through Neuroevolution
We propose a method for evolving solutions that are robust with respect to variations of the environmental conditions (i.e. that can operate effectively in new conditions immediately, without the need to adapt to variations). The obtained results show how the method proposed is effective and computational tractable. It permits to improve performance on an extended version of the double-pole balancing problem, to outperform the best available human-designed controllers on a car racing problem, and to generate rather effective solutions for a swarm robotic problem. The comparison of different algorithms indicates that the CMA-ES and xNES methods, that operate by optimizing a distribution of parameters, represent the best options for the evolution of robust neural network controllers.
Adversarial Examples – A Complete Characterisation of the Phenomenon
We provide a complete characterisation of the phenomenon of adversarial examples – inputs intentionally crafted to fool machine learning models. We aim to cover all the important concerns in this field of study: (1) the conjectures on the existence of adversarial examples, (2) the security, safety and robustness implications, (3) the methods used to generate and (4) protect against adversarial examples and (5) the ability of adversarial examples to transfer between different machine learning models. We provide ample background information in an effort to make this document self-contained. Therefore, this document can be used as survey, tutorial or as a catalog of attacks and defences using adversarial examples.
Inference Over Programs That Make Predictions
This abstract extends on the previous work (arXiv:1407.2646, arXiv:1606.00075) on program induction using probabilistic programming. It describes possible further steps to extend that work, such that, ultimately, automatic probabilistic program synthesis can generalise over any reasonable set of inputs and outputs, in particular in regard to text, image and video data.
High-dimensional functional time series forecasting: An application to age-specific mortality rates
We address the problem of forecasting high-dimensional functional time series through a two-fold dimension reduction procedure. The difficulty of forecasting high-dimensional functional time series lies in the curse of dimensionality. In this paper, we propose a novel method to solve this problem. Dynamic functional principal component analysis is first applied to reduce each functional time series to a vector. We then use the factor model as a further dimension reduction technique so that only a small number of latent factors are preserved. Classic time series models can be used to forecast the factors and conditional forecasts of the functions can be constructed. Asymptotic properties of the approximated functions are established, including both estimation error and forecast error. The proposed method is easy to implement especially when the dimension of the functional time series is large. We show the superiority of our approach by both simulation studies and an application to Japanese age-specific mortality rates.
Near-Linear Approximation Algorithms for Scheduling Problems with Batch Setup Times
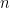


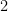
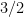
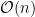
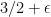
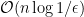


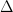



Causal inference under over-simplified longitudinal causal models
Most causal models of interest involve longitudinal exposures, confounders and mediators. However, in practice, repeated measurements are rarely available. Then, practitioners tend to overlook the time-varying nature of exposures and work under over-simplified causal models. In this work, we investigate whether, and how, the quantities estimated under these simplified models can be related to the true longitudinal causal effects. We focus on two common situations regarding the type of available data for exposures: when they correspond to (i) ‘instantaneous’ levels measured at inclusion in the study or (ii) summary measures of their levels up to inclusion in the study. Our results state that inference based on either ‘instantaneous’ levels or summary measures usually returns quantities that do not directly relate to any causal effect of interest and should be interpreted with caution. They raise the need for the availability of repeated measurements and/or the development of sensitivity analyses when such data is not available.
Learning with Random Learning Rates
Hyperparameter tuning is a bothersome step in the training of deep learning models. One of the most sensitive hyperparameters is the learning rate of the gradient descent. We present the ‘All Learning Rates At Once’ (Alrao) optimization method for neural networks: each unit or feature in the network gets its own learning rate sampled from a random distribution spanning several orders of magnitude. This comes at practically no computational cost. Perhaps surprisingly, stochastic gradient descent (SGD) with Alrao performs close to SGD with an optimally tuned learning rate, for various architectures and problems. Alrao could save time when testing deep learning models: a range of models could be quickly assessed with Alrao, and the most promising models could then be trained more extensively. This text comes with a PyTorch implementation of the method, which can be plugged on an existing PyTorch model.
Generative Ensembles for Robust Anomaly Detection


Optimal Completion Distillation for Sequence Learning

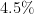
GLAD: GLocalized Anomaly Detection via Active Feature Space Suppression
We propose an algorithm called GLAD (GLocalized Anomaly Detection) that allows end-users to retain the use of simple and understandable global anomaly detectors by automatically learning their local relevance to specific data instances using label feedback. The key idea is to place a uniform prior over the input feature space for each member of the anomaly detection ensemble via a neural network trained on unlabeled instances, and tune the weights of the neural network to adjust the local relevance of each ensemble member using all labeled instances. Our experiments on synthetic and real-world data show the effectiveness of GLAD in learning the local relevance of ensemble members and discovering anomalies via label feedback.
• Optimal Adaptive and Accelerated Stochastic Gradient Descent• Probabilistic Meta-Representations Of Neural Networks• The information-theoretic meaning of Gagliardo–Nirenberg type inequalities• Performance Evaluation for LTE-V based Vehicle-to-Vehicle Platooning Communication• Adaptive Polling in Hierarchical Social Networks using Blackwell Dominance• On valid descriptive inference from non-probability sample• Slaying Hydrae: Improved Bounds for Generalized k-Server in Uniform Metrics• Spectra of networks• Selberg integrals in 1D random Euclidean optimization problems• Improved Ramsey-type results in comparability graphs• Detecting Satire in the News with Machine Learning• Composite optimization for the resource allocation problem• Fault Tolerant Adaptive Parallel and Distributed Simulation through Functional Replication• Unsupervised Trajectory Segmentation and Promoting of Multi-Modal Surgical Demonstrations• Orbital Stabilization of Nonlinear Systems via the Immersion and Invariance Technique• Privado: Practical and Secure DNN Inference• One-Click Annotation with Guided Hierarchical Object Detection• Phase resetting and intermittent control at critical edge of stability as major mechanisms of fractality in human gait cycle variability• Central Values for Clebsch-Gordan coefficients• Design and simulation of 1.28 Tbps dense wavelength division multiplex system suitable for long haul backbone• Explicit solutions of the kinetic and potential matching conditions of the energy shaping method• Polyline Simplification has Cubic Complexity• Approximation bounds on maximum edge 2-coloring of dense graphs• Neighborhood complexes, homotopy test graphs and a contribution to a conjecture of Hedetniemi• Role of time scales and topology on the dynamics of complex networks• Part-Level Convolutional Neural Networks for Pedestrian Detection Using Saliency and Boundary Box Alignment• Random Finite Set Theory and Optimal Control for Large Spacecraft Swarms• Data-driven Discovery of Cyber-Physical Systems• Well-posedness and Stability for Interconnection Structures of Port-Hamiltonian Type• On the existence of O’Nan configurations in Buekenhout unitals in PG(2,q^2)• TOP: Time-to-Event Bayesian Optimal Phase II Trial Design for Cancer Immunotherapy• Complete intersection Jordan types in height two• Joint Activity Detection and Channel Estimation for IoT Networks: Phase Transition and Computation-Estimation Tradeoff• SurfelMeshing: Online Surfel-Based Mesh Reconstruction• Towards Cereceda’s conjecture for planar graphs• Smeared phase transitions in percolation on real complex networks• Benchmark Analysis of Representative Deep Neural Network Architectures• Risk-Averse Stochastic Convex Bandit• Bayesian inference in high-dimensional linear models using an empirical correlation-adaptive prior• Game-Theoretic Choice of Curing Rates Against Networked SIS Epidemics by Human Decision-Makers• Improving the Generalization of Adversarial Training with Domain Adaptation• Quantum asymptotic spectra of graphs and non-commutative graphs, and quantum Shannon capacities• Bayesian Prediction of Future Street Scenes using Synthetic Likelihoods• CBPF: leveraging context and content information for better recommendations• Analysis of the shortest relay queue policy in a cooperative random access network with collisions• Riemannian Adaptive Optimization Methods• Bisectors and pinned distances• Geometric Constellation Shaping for Fiber Optic Communication Systems via End-to-end Learning• Computing Dynamic User Equilibria on Large-Scale Networks: From Theory to Software Implementation• Mean Field Control and Mean Field Game Models with Several Populations• Enumerating minimal dominating sets in triangle-free graphs• Optimal Pricing For MHR Distributions• Accelerated Training of Large-Scale Gaussian Mixtures by a Merger of Sublinear Approaches• Solving 3SAT By Reduction To Testing For Odd Hole• Graph Isomorphism by Conversion to Chordal (6, 3) Graphs• Multilevel Adaptive Sparse Grid Quadrature for Monte Carlo models• Caterpillars in Erdős-Hajnal• Hypergraph polynomials and the Bernardi process• Two types of slow waves in anesthetized and sleeping brains• On the maximum number of copies of H in graphs with given size and order• RGB-D Object Detection and Semantic Segmentation for Autonomous Manipulation in Clutter• Variational Discriminator Bottleneck: Improving Imitation Learning, Inverse RL, and GANs by Constraining Information Flow• Approximating mixed Hölder functions using random samples• Set Transformer• Singularity, Misspecification, and the Convergence Rate of EM• Adaptive Game-Theoretic Decision Making for Autonomous Vehicle Control at Roundabouts• Network Modeling and Pathway Inference from Incomplete Data (‘PathInf’)• CHET: Compiler and Runtime for Homomorphic Evaluation of Tensor Programs• Classification from Positive, Unlabeled and Biased Negative Data• Augmented Mitotic Cell Count using Field Of Interest Proposal• Truncated Laplacian Mechanism for Approximate Differential Privacy• Dynamic Sparse Graph for Efficient Deep Learning• ProxQuant: Quantized Neural Networks via Proximal Operators• Geometry of quadratic maps via convex relaxation• Dealing with State Estimation in Fractional-Order Systems under Artifacts• A Statistical Exploration of Duckworth-Lewis Method Using Bayesian Inference• Visual Curiosity: Learning to Ask Questions to Learn Visual Recognition• Degree versions of theorems on intersecting families via stability• Handling Nominals and Inverse Roles using Algebraic Reasoning• Robust multivariate and functional archetypal analysis with application to financial time series analysis• Structure and properties of large intersecting families• Secrecy Analysis of Random MIMO Wireless Networks over $α$-$μ$ Fading Channels• Joint On-line Learning of a Zero-shot Spoken Semantic Parser and a Reinforcement Learning Dialogue Manager• Wikidata: A New Paradigm of Human-Bot Collaboration?• Few $T$ copies in $H$-saturated graphs• Modified diagonals and linear relations between small diagonals• Improved robustness to adversarial examples using Lipschitz regularization of the loss• The competitive exclusion principle in stochastic environments• On the density of sets of the Euclidean plane avoiding distance 1• Rigidity of the saddle connection complex• Natural measures of alignment• Efficient and Accurate Abnormality Mining from Radiology Reports with Customized False Positive Reduction• Utilizing a Transparency-driven Environment toward Trusted Automatic Genre Classification: A Case Study in Journalism History• On the discovery of the seed in uniform attachment trees• Abstract convex approximations of nonsmooth functions• A sampling framework for counting temporal motifs• Inertial-aided Motion Deblurring with Deep Networks• Ballot Permutations, Odd Order Permutations, and a New Permutation Statistic• A simple parameter-free and adaptive approach to optimization under a minimal local smoothness assumption• Critical groups of van Lint-Schrijver Cyclotomic Strongly Regular Graphs• Learning Hash Codes via Hamming Distance Targets• Power domination throttling• CNN-SVO: Improving the Mapping in Semi-Direct Visual Odometry Using Single-Image Depth Prediction• Distributional Semantics Approach to Detect Intent in Twitter Conversations on Sexual Assaults• AI for Trustworthiness! Credible User Identification on Social Web for Disaster Response Agencies• Bayesian Policy Optimization for Model Uncertainty• Convergence Rates for Empirical Estimation of Binary Classification Bounds• Simultaneously Optimizing Weight and Quantizer of Ternary Neural Network using Truncated Gaussian Approximation• Large batch size training of neural networks with adversarial training and second-order information• Reinforcement Learning with Perturbed Rewards• Heterogeneous Replica for Query on Cassandra• Implementing the Lexicographic Maxmin Bargaining Solution• Nondegenerate spheres in four dimensions• A Unified Framework for Clustering Constrained Data without Locality Property• Improved Parallel Rabin-Karp Algorithm Using Compute Unified Device Architecture• A Sharp Convergence Rate Analysis for Distributed Accelerated Gradient Methods• ChainQueen: A Real-Time Differentiable Physical Simulator for Soft Robotics• Super-Resolution Blind Channel-and-Signal Estimation for Massive MIMO with Arbitrary Array Geometry• Improving Sentence Representations with Multi-view Frameworks• Lattice points in vector-dilated quadratic irrational polytopes• PDE Acceleration: A convergence rate analysis and applications to obstacle problems• Cloud Chaser: Real Time Deep Learning Computer Vision on Low Computing Power Devices• Fully dynamic $3/2$ approximate maximum cardinality matching in $O(\sqrt{n})$ update time• NU-LiteNet: Mobile Landmark Recognition using Convolutional Neural Networks• Implicit Self-Regularization in Deep Neural Networks: Evidence from Random Matrix Theory and Implications for Learning• On the Interference from VDE-SAT Downlink to the Incumbent Land Mobile System• A framework for generalized group testing with inhibitors and its potential application in neuroscience• Statistical learning with Lipschitz and convex loss functions• Ancient Coin Classification Using Graph Transduction Games• Relating Metric Distortion and Fairness of Social Choice Rules• Quantization-Aware Phase Retrieval• Cramér type moderate deviations for self-normalized $ψ$-mixing sequences• Video Imitation GAN: Learning control policies by imitating raw videos using generative adversarial reward estimation• Reconfiguring Graph Homomorphisms on the Sphere• The Dreaming Variational Autoencoder for Reinforcement Learning Environments• Who is Addressed in this Comment? Automatically Classifying Meta-Comments in News Comments• Inverse Gaussian quadrature and finite normal-mixture approximation of generalized hyperbolic distribution• Non-linear Model Predictive Control of Conically Shaped Liquid Storage Tanks• Predicate learning in neural systems: Discovering latent generative structures• Time Reversal as Self-Supervision• A Gini approach to spatial CO2 emissions• A deterministic polynomial kernel for Odd Cycle Transversal and Vertex Multiway Cut in planar graphs• Avoiding Burst-like Error Patterns in Windowed Decoding of Spatially Coupled LDPC Codes• Training compact deep learning models for video classification using circulant matrices• Retrofit Control with Approximate Environment Modeling• Coupled McKean-Vlasov diffusions: wellposedness, propagation of chaos and invariant measures• On characterizations of the covariance matrix• Know What Your Neighbors Do: 3D Semantic Segmentation of Point Clouds• Learning Discriminators as Energy Networks in Adversarial Learning• On Learning How to Communicate Over Noisy Channels for Collaborative Tasks• Sharp bounds for the chromatic number of random Kneser graphs• An Entropic Optimal Transport Loss for Learning Deep Neural Networks under Label Noise in Remote Sensing Images• Advanced Simulation of Droplet Microfluidics• Semi-supervised Text Regression with Conditional Generative Adversarial Networks• Variations on the CSC model• Findings of the E2E NLG Challenge• Note on the Estimation of Embedded Hermitian Gaussian Graphical Models for MEEG Source Activity and Connectivity Analysis in the Frequency Domain. Part I: Single Frequency Component and Subject• EMI: Exploration with Mutual Information Maximizing State and Action Embeddings• A variational formula for risk-sensitive control of diffusions in $\mathbb{R}^d$• Stochastic maximal regularity for rough time-dependent problems• Thompson Sampling for Cascading Bandits• Large deviations for the largest eigenvalue of Rademacher matrices• Sharp spectral bounds for the edge-connectivity of a regular graph• Characterization of Visual Object Representations in Rat Primary Visual Cortex• Consistent Maximum Likelihood Estimation Using Subsets with Applications to Multivariate Mixed Models• Bayesian approach to SETI• On non-repetitive sequences of arithmetic progressions:the cases $k \in {4,5,6,7,8}$• Rough infection fronts in a random medium• Approximation and sampling of multivariate probability distributions in the tensor train decomposition• All-optical Nonlinear Activation Function for Photonic Neural Networks• Sparse Gaussian Process Temporal Difference Learning for Marine Robot Navigation• CEM-RL: Combining evolutionary and gradient-based methods for policy search• The largest projective cube-free subsets of $\mathbb{Z}_{2^n}$• Long term behaviour of a reversible system of interacting random walks• Combinatorial Algorithms for General Linear Arrow-Debreu Markets• Sketching, Streaming, and Fine-Grained Complexity of (Weighted) LCS• A Deep Autoencoder System for Differentiation of Cancer Types Based on DNA Methylation State• Fragility and anomalous susceptibility of weakly interacting networks• Near-Optimal Representation Learning for Hierarchical Reinforcement Learning• From phase to amplitude oscillators• Bias Reduced Peaks over Threshold Tail Estimation• Sampling-based Estimation of In-degree Distribution with Applications to Directed Complex Networks• Strong solutions of SDEs with random and unbounded drifts• Landmine Detection Using Autoencoders on Multi-polarization GPR Volumetric Data• Moderate-Dimensional Inferences on Quadratic Functionals in Ordinary Least Squares• Hypocoercivity in Wasserstein-1 for the kinetic Fokker-Planck equation via Malliavin Calculus• FutureGAN: Anticipating the Future Frames of Video Sequences using Spatio-Temporal 3d Convolutions in Progressively Growing Autoencoder GANs• Finite Codimensional Controllability, and Optimal Control Problems with Endpoint State Constraints• The gap in Pure Traction Problems between Linear Elasticity and Variational Limit of Finite Elasticity• Majorization by Hemispheres & Quadratic Isoperimetric Constants• Unsupervised Emergence of Spatial Structure from Sensorimotor Prediction• Efficient Detectors for MIMO-OFDM Systems under Spatial Correlation Antenna Arrays• The structure of normal lattice supercharacter theories• Energy-Based Hindsight Experience Prioritization• On Self Modulation for Generative Adversarial Networks• FFJORD: Free-form Continuous Dynamics for Scalable Reversible Generative Models• Speed-Gradient Control of the Brockett Integrator• Semi-dense Stereo Matching using Dual CNNs• Covariate Distribution Balance via Propensity Scores• Efficient Dialog Policy Learning via Positive Memory Retention• Multi-scale Convolution Aggregation and Stochastic Feature Reuse for DenseNets• A Knowledge Hunting Framework for Common Sense Reasoning• Unbiased estimation of log normalizing constants with applications to Bayesian cross-validation• Archimedean toroidal maps and their minimal almost regular covers• Approximating the Existential Theory of the Reals• Phasebook and Friends: Leveraging Discrete Representations for Source Separation• Sketching for Latent Dirichlet-Categorical Models• Attention Models with Random Features for Multi-layered Graph Embeddings• Super-Resolution via Conditional Implicit Maximum Likelihood Estimation• Can Adversarially Robust Learning Leverage Computational Hardness?
Like this:
Like Loading…
Related