Federated AI for building AI Solutions across Multiple Agencies
The different sets of regulations existing for differ-ent agencies within the government make the task of creating AI enabled solutions in government dif-ficult. Regulatory restrictions inhibit sharing of data across different agencies, which could be a significant impediment to training AI models. We discuss the challenges that exist in environments where data cannot be freely shared and assess tech-nologies which can be used to work around these challenges. We present results on building AI models using the concept of federated AI, which allows creation of models without moving the training data around.
Morphed Learning: Towards Privacy-Preserving for Deep Learning Based Applications
The concern of potential privacy violation has prevented efficient use of big data for improving deep learning based applications. In this paper, we propose Morphed Learning, a privacy-preserving technique for deep learning based on data morphing that, allows data owners to share their data without leaking sensitive privacy information. Morphed Learning allows the data owners to send securely morphed data and provides the server with an Augmented Convolutional layer to train the network on morphed data without performance loss. Morphed Learning has these three features: (1) Strong protection against reverse-engineering on the morphed data; (2) Acceptable computational and data transmission overhead with no correlation to the depth of the neural network; (3) No degradation of the neural network performance. Theoretical analyses on CIFAR-10 dataset and VGG-16 network show that our method is capable of providing 10^89 morphing possibilities with only 5% computational overhead and 10% transmission overhead under limited knowledge attack scenario. Further analyses also proved that our method can offer same resilience against full knowledge attack if more resources are provided.
Programming at Exascale: Challenges and Innovations
Supercomputers become faster as hardware and software technologies continue to evolve. Current supercomputers are capable of 1015 floating point operations per second (FLOPS) that called Petascale system. The High Performance Computer (HPC) community is Looking forward to the system with capability of 1018 (FLOPS) that is called Exascale. Having a system to thousand times faster than the previous one produces challenges to the high performance computer (HPC) community. These challenges require innovation in software and hardware. In this paper, the challenges posed for programming at Exascale systems are reviewed and the developments in the main programming models and systems are surveyed.
A general space-time model for combinatorial optimization problems (and not only)

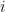
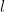
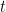

LOBO — Evaluation of Generalization Deficiencies in Twitter Bot Classifiers
Botnets in online social networks are increasingly often affecting the regular flow of discussion, attacking regular users and their posts, spamming them with irrelevant or offensive content, and even manipulating the popularity of messages and accounts. Researchers and cybercriminals are involved in an arms race, and new and updated botnets designed to defeat current detection systems are constantly developed, rendering such detection systems obsolete. In this paper, we motivate the need for a generalized evaluation in Twitter bot detection and propose a methodology to evaluate bot classifiers by testing them on unseen bot classes. We show that this methodology is empirically robust, using bot classes of varying sizes and characteristics and reaching similar results, and argue that methods trained and tested on single bot classes or datasets might not able to generalize to new bot classes. We train one such classifier on over 200,000 data points and show that it achieves over 97% accuracy. The data used to train and test this classifier includes some of the largest and most varied collections of bots used in literature. We then test this theoretically sound classifier using our methodology, highlighting that it does not generalize well to unseen bot classes. Finally, we discuss the implications of our results, and reasons why some bot classes are easier and faster to detect than others.
Learning Consumer and Producer Embeddings for User-Generated Content Recommendation
User-Generated Content (UGC) is at the core of web applications where users can both produce and consume content. This differs from traditional e-Commerce domains where content producers and consumers are usually from two separate groups. In this work, we propose a method CPRec (consumer and producer based recommendation), for recommending content on UGC-based platforms. Specifically, we learn a core embedding for each user and two transformation matrices to project the user’s core embedding into two ‘role’ embeddings (i.e., a producer and consumer role). We model each interaction by the ternary relation between the consumer, the consumed item, and its producer. Empirical studies on two large-scale UGC applications show that our method outperforms standard collaborative filtering methods as well as recent methods that model producer information via item features.
Assessing Method Agreement for Paired Repeated Binary Measurements
Method comparison studies are essential for development in medical and clinical fields. These studies often compare a cheaper, faster, or less invasive measuring method with a widely used one to see if they have sufficient agreement for interchangeable use. In the clinical and medical context, the response measurement is usually impacted not only by the measuring method but by the rater as well. This paper proposes a model-based approach to assess agreement of two measuring methods for paired repeated binary measurements under the scenario when the agreement between two measuring methods and the agreement among raters are required to be studied in a unified framework. Based upon the generalized linear mixed models (GLMM), the decision on the adequacy of interchangeable use is made by testing the equality of fixed effects of methods. Approaches for assessing method agreement, such as the Bland-Altman diagram and Cohen’s kappa, are also developed for repeated binary measurements based upon the latent variables in GLMMs. We assess our novel model-based approach by simulation studies and a real clinical research application, in which patients are evaluated repeatedly for delirium with two validated screening methods: the Confusion Assessment Method and the 3-Minute Diagnostic Interview for Confusion Assessment Method. Both the simulation studies and the real data analyses demonstrate that our new approach can effectively assess method agreement.
An Algorithm for Reducing Approximate Nearest Neighbor to Approximate Near Neighbor with O(logn) Query Time
This paper proposes a new algorithm for reducing Approximate Nearest Neighbor problem to Approximate Near Neighbor problem. The advantage of this algorithm is that it achieves O(log n) query time. As a reduction problem, the uery time complexity is the times of invoking the algorithm for Approximate Near Neighbor problem. All former algorithms for the same reduction need polylog(n) query time. A box split method proposed by Vaidya is used in our paper to achieve the O(log n) query time complexity.
A new Gini correlation between quantitative and qualitative variables
A novel approach for venue recommendation using cross-domain techniques
Finding the next venue to be visited by a user in a specific city is an interesting, but challenging, problem. Different techniques have been proposed, combining collaborative, content, social, and geographical signals; however it is not trivial to decide which tech- nique works best, since this may depend on the data density or the amount of activity logged for each user or item. At the same time, cross-domain strategies have been exploited in the recommender systems literature when dealing with (very) sparse situations, such as those inherently arising when recommendations are produced based on information from a single city. In this paper, we address the problem of venue recommendation from a novel perspective: applying cross-domain recommendation techniques considering each city as a different domain. We perform an experimental comparison of several recommendation techniques in a temporal split under two conditions: single-domain (only information from the target city is considered) and cross- domain (information from many other cities is incorporated into the recommendation algorithm). For the latter, we have explored two strategies to transfer knowledge from one domain to another: testing the target city and training a model with information of the k cities with more ratings or only using the k closest cities. Our results show that, in general, applying cross-domain by proximity increases the performance of the majority of the recom- menders in terms of relevance. This is the first work, to the best of our knowledge, where so many domains (eight) are combined in the tourism context where a temporal split is used, and thus we expect these results could provide readers with an overall picture of what can be achieved in a real-world environment.
Effects of Storage Heterogeneity in Distributed Cache Systems
In this work, we focus on distributed cache systems with non-uniform storage capacity across caches. We compare the performance of our system with the performance of a system with the same cumulative storage distributed evenly across the caches. We characterize the extent to which the performance of the distributed cache system deteriorates due to storage heterogeneity. The key takeaway from this work is that the effects of heterogeneity in the storage capabilities depend heavily on the popularity profile of the contents being cached and delivered. We analytically show that compared to the case where contents popularity is comparable across contents, lopsided popularity profiles are more tolerant to heterogeneity in storage capabilities. We validate our theoretical results via simulations.
PeSOA: Penguins Search Optimisation Algorithm for Global Optimisation Problems
This paper develops Penguin search Optimisation Algorithm (PeSOA), a new metaheuristic algorithm which is inspired by the foraging behaviours of penguins. A population of penguins located in the solution space of the given search and optimisation problem is divided into groups and tasked with finding optimal solutions. The penguins of a group perform simultaneous dives and work as a team to collaboratively feed on fish the energy content of which corresponds to the fitness of candidate solutions. Fish stocks have higher fitness and concentration near areas of solution optima and thus drive the search. Penguins can migrate to other places if their original habitat lacks food. We identify two forms of penguin communication both intra-group and inter-group which are useful in designing intensification and diversification strategies. An efficient intensification strategy allows fast convergence to a local optimum, whereas an effective diversification strategy avoids cyclic behaviour around local optima and explores more effectively the space of potential solutions. The proposed PeSOA algorithm has been validated on a well-known set of benchmark functions. Comparative performances with six other nature-inspired metaheuristics show that the PeSOA performs favourably in these tests. A run-time analysis shows that the performance obtained by the PeSOA is very stable at any time of the evolution horizon, making the PeSOA a viable approach for real world applications.
Every Node Counts: Self-Ensembling Graph Convolutional Networks for Semi-Supervised Learning
Graph convolutional network (GCN) provides a powerful means for graph-based semi-supervised tasks. However, as a localized first-order approximation of spectral graph convolution, the classic GCN can not take full advantage of unlabeled data, especially when the unlabeled node is far from labeled ones. To capitalize on the information from unlabeled nodes to boost the training for GCN, we propose a novel framework named Self-Ensembling GCN (SEGCN), which marries GCN with Mean Teacher – another powerful model in semi-supervised learning. SEGCN contains a student model and a teacher model. As a student, it not only learns to correctly classify the labeled nodes, but also tries to be consistent with the teacher on unlabeled nodes in more challenging situations, such as a high dropout rate and graph collapse. As a teacher, it averages the student model weights and generates more accurate predictions to lead the student. In such a mutual-promoting process, both labeled and unlabeled samples can be fully utilized for backpropagating effective gradients to train GCN. In three article classification tasks, i.e. Citeseer, Cora and Pubmed, we validate that the proposed method matches the state of the arts in the classification accuracy.
Multivariate Stochastic Volatility Model with Realized Volatilities and Pairwise Realized Correlations
Although stochastic volatility and GARCH models have been successful to describe the volatility dynamics of univariate asset returns, their natural extension to the multivariate models with dynamic correlations has been difficult due to several major problems. Firstly, there are too many parameters to estimate if available data are only daily returns, which results in unstable estimates. One solution to this problem is to incorporate additional observations based on intraday asset returns such as realized covariances. However, secondly, since multivariate asset returns are not traded synchronously, we have to use largest time intervals so that all asset returns are observed to compute the realized covariance matrices, where we fail to make full use of available intraday informations when there are less frequently traded assets. Thirdly, it is not straightforward to guarantee that the estimated (and the realized) covariance matrices are positive definite. Our contributions are : (1) we obtain the stable parameter estimates for dynamic correlation models using the realized measures, (2) we make full use of intraday informations by using pairwise realized correlations, (3) the covariance matrices are guaranteed to be positive definite, (4) we avoid the arbitrariness of the ordering of asset returns, (5) propose the flexible correlation structure model (e.g. such as setting some correlations to be identically zeros if necessary), and (6) the parsimonious specification for the leverage effect is proposed. Our proposed models are applied to daily returns of nine U.S. stocks with their realized volatilities and pairwise realized correlations, and are shown to outperform the existing models with regard to portfolio performances.
GPU Accelerated Similarity Self-Join for Multi-Dimensional Data
The self-join finds all objects in a dataset that are within a search distance, epsilon, of each other; therefore, the self-join is a building block of many algorithms. We advance a GPU-accelerated self-join algorithm targeted towards high dimensional data. The massive parallelism afforded by the GPU and high aggregate memory bandwidth makes the architecture well-suited for data-intensive workloads. We leverage a grid-based, GPU-tailored index to perform range queries. We propose the following optimizations: (i) a trade-off between candidate set filtering and index search overhead by exploiting properties of the index; (ii) reordering the data based on variance in each dimension to improve the filtering power of the index; and (iii) a pruning method for reducing the number of expensive distance calculations. Across most scenarios on real-world and synthetic datasets, our algorithm outperforms the parallel state-of-the-art approach. Exascale systems are converging on heterogeneous distributed-memory architectures. We show that an entity partitioning method can be utilized to achieve a balanced workload, and thus good scalability for multi-GPU or distributed-memory self-joins.
Deep Neural Networks for Estimation and Inference: Application to Causal Effects and Other Semiparametric Estimands
We study deep neural networks and their use in semiparametric inference. We provide new rates of convergence for deep feedforward neural nets and, because our rates are sufficiently fast (in some cases minimax optimal), prove that semiparametric inference is valid using deep nets for first-step estimation. Our estimation rates and semiparametric inference results are the first in the literature to handle the current standard architecture: fully connected feedforward neural networks (multi-layer perceptrons), with the now-default rectified linear unit (ReLU) activation function and a depth explicitly diverging with the sample size. We discuss other architectures as well, including fixed-width, very deep networks. We establish nonasymptotic bounds for these deep ReLU nets, for both least squares and logistic loses in nonparametric regression. We then apply our theory to develop semiparametric inference, focusing on treatment effects and expected profits for concreteness, and demonstrate their effectiveness with an empirical application to direct mail marketing. Inference in many other semiparametric contexts can be readily obtained.
The Internet of Things, Fog and Cloud Continuum: Integration and Challenges
The Internet of Things needs for computing power and storage are expected to remain on the rise in the next decade. Consequently, the amount of data generated by devices at the edge of the network will also grow. While cloud computing has been an established and effective way of acquiring computation and storage as a service to many applications, it may not be suitable to handle the myriad of data from IoT devices and fulfill largely heterogeneous application requirements. Fog computing has been developed to lie between IoT and the cloud, providing a hierarchy of computing power that can collect, aggregate, and process data from/to IoT devices. Combining fog and cloud may reduce data transfers and communication bottlenecks to the cloud and also contribute to reduced latencies, as fog computing resources exist closer to the edge. This paper examines this IoT-Fog-Cloud ecosystem and provides a literature review from different facets of it: how it can be organized, how management is being addressed, and how applications can benefit from it. Lastly, we present challenging issues yet to be addressed in IoT-Fog-Cloud infrastructures.
A Novel Online Stacked Ensemble for Multi-Label Stream Classification
As data streams become more prevalent, the necessity for online algorithms that mine this transient and dynamic data becomes clearer. Multi-label data stream classification is a supervised learning problem where each instance in the data stream is classified into one or more pre-defined sets of labels. Many methods have been proposed to tackle this problem, including but not limited to ensemble-based methods. Some of these ensemble-based methods are specifically designed to work with certain multi-label base classifiers; some others employ online bagging schemes to build their ensembles. In this study, we introduce a novel online and dynamically-weighted stacked ensemble for multi-label classification, called GOOWE-ML, that utilizes spatial modeling to assign optimal weights to its component classifiers. Our model can be used with any existing incremental multi-label classification algorithm as its base classifier. We conduct experiments with 4 GOOWE-ML-based multi-label ensembles and 7 baseline models on 7 real-world datasets from diverse areas of interest. Our experiments show that GOOWE-ML ensembles yield consistently better results in terms of predictive performance in almost all of the datasets, with respect to the other prominent ensemble models.
Learning through Probing: a decentralized reinforcement learning architecture for social dilemmas
Multi-agent reinforcement learning has received significant interest in recent years notably due to the advancements made in deep reinforcement learning which have allowed for the developments of new architectures and learning algorithms. Using social dilemmas as the training ground, we present a novel learning architecture, Learning through Probing (LTP), where agents utilize a probing mechanism to incorporate how their opponent’s behavior changes when an agent takes an action. We use distinct training phases and adjust rewards according to the overall outcome of the experiences accounting for changes to the opponents behavior. We introduce a parameter eta to determine the significance of these future changes to opponent behavior. When applied to the Iterated Prisoner’s Dilemma (IPD), LTP agents demonstrate that they can learn to cooperate with each other, achieving higher average cumulative rewards than other reinforcement learning methods while also maintaining good performance in playing against static agents that are present in Axelrod tournaments. We compare this method with traditional reinforcement learning algorithms and agent-tracking techniques to highlight key differences and potential applications. We also draw attention to the differences between solving games and societal-like interactions and analyze the training of Q-learning agents in makeshift societies. This is to emphasize how cooperation may emerge in societies and demonstrate this using environments where interactions with opponents are determined through a random encounter format of the IPD.
No One is Perfect: Analysing the Performance of Question Answering Components over the DBpedia Knowledge Graph
Question answering (QA) over knowledge graphs has gained significant momentum over the past five years due to the increasing availability of large knowledge graphs and the rising importance of question answering for user interaction. DBpedia has been the most prominently used knowledge graph in this setting and most approaches currently use a pipeline of processing steps connecting a sequence of components. In this article, we analyse and micro evaluate the behaviour of 29 available QA components for DBpedia knowledge graph that were released by the research community since 2010. As a result, we provide a perspective on collective failure cases, suggest characteristics of QA components that prevent them from performing better and provide future challenges and research directions for the field.
Rediscovering Deep Neural Networks in Finite-State Distributions
We propose a new way of thinking about deep neural networks, in which the linear and non-linear components of the network are naturally derived and justified in terms of principles in probability theory. In particular, the models constructed in our framework assign probabilities to uncertain realizations, leading to Kullback-Leibler Divergence (KLD) as the linear layer. In our model construction, we also arrive at a structure similar to ReLU activation supported with Bayes’ theorem. The non-linearities in our framework are normalization layers with ReLU and Sigmoid as element-wise approximations. Additionally, the pooling function is derived as a marginalization of spatial random variables according to the mechanics of the framework. As such, Max Pooling is an approximation to the aforementioned marginalization process. Since our models are comprised of finite state distributions (FSD) as variables and parameters, exact computation of information-theoretic quantities such as entropy and KLD is possible, thereby providing more objective measures to analyze networks. Unlike existing designs that rely on heuristics, the proposed framework restricts subjective interpretations of CNNs and sheds light on the functionality of neural networks from a completely new perspective.
Bayesian Data Synthesis and Disclosure Risk Quantification: An Application to the Consumer Expenditure Surveys
The release of synthetic data generated from a model estimated on the data helps statistical agencies disseminate respondent-level data with high utility and privacy protection. Motivated by the challenge of disseminating sensitive variables containing geographic information in the Consumer Expenditure Surveys (CE) at the U.S. Bureau of Labor Statistics, we propose two non-parametric Bayesian models as data synthesizers for the county identifier of each data record: a Bayesian latent class model and a Bayesian areal model. Both data synthesizers use Dirichlet Process priors to cluster observations of similar characteristics and allow borrowing information across observations. We develop innovative disclosure risks measures to quantify inherent risks in the original CE data and how those data risks are ameliorated by our proposed synthesizers. By creating a lower bound and an upper bound of disclosure risks under a minimum and a maximum disclosure risks scenarios respectively, our proposed inherent risks measures provide a range of acceptable disclosure risks for evaluating risks level in the synthetic datasets.
Unsupervised Adversarial Invariance
Data representations that contain all the information about target variables but are invariant to nuisance factors benefit supervised learning algorithms by preventing them from learning associations between these factors and the targets, thus reducing overfitting. We present a novel unsupervised invariance induction framework for neural networks that learns a split representation of data through competitive training between the prediction task and a reconstruction task coupled with disentanglement, without needing any labeled information about nuisance factors or domain knowledge. We describe an adversarial instantiation of this framework and provide analysis of its working. Our unsupervised model outperforms state-of-the-art methods, which are supervised, at inducing invariance to inherent nuisance factors, effectively using synthetic data augmentation to learn invariance, and domain adaptation. Our method can be applied to any prediction task, eg., binary/multi-class classification or regression, without loss of generality.
From Classical to Generalized Zero-Shot Learning: a Simple Adaptation Process
Zero-shot learning (ZSL) is concerned with the recognition of previously unseen classes. It relies on additional semantic knowledge for which a mapping can be learned with training examples of seen classes. While classical ZSL considers the recognition performance on unseen classes only, generalized zero-shot learning (GZSL) aims at maximizing performance on both seen and unseen classes. In this paper, we propose a new process for training and evaluation in the GZSL setting; this process addresses the gap in performance between samples from unseen and seen classes by penalizing the latter, and enables to select hyper-parameters well-suited to the GZSL task. It can be applied to any existing ZSL approach and leads to a significant performance boost: the experimental evaluation shows that GZSL performance, averaged over eight state-of-the-art methods, is improved from 28.5 to 42.2 on CUB and from 28.2 to 57.1 on AwA2.
• Development of spatial suppression surrounding the focus of visual attention• Learning short-term past as predictor of human behavior in commercial buildings• A big data based method for pass rates optimization in mathematics university lower division courses• Dynamical anomalies in terrestrial proxies of North Atlantic climate variability during the last 2 ka• Multispecies fruit flower detection using a refined semantic segmentation network• Topological Data Analysis of Task-Based fMRI Data from Experiments on Schizophrenia• TDMA in Adaptive Resonant Beam Charging for IoT Devices• Performances of a GNSS receiver for space-based applications• Real-time Interference Identification via Supervised Learning: A Coexistence Framework for Massive IoT Networks• Computational and informatics advances for reproducible data analysis in neuroimaging• Personalized Education at Scale• Satellite Imagery Multiscale Rapid Detection with Windowed Networks• RAFP-Pred: Robust Prediction of Antifreeze Proteins using Localized Analysis of n-Peptide Compositions• On recovery of signals with single point spectrum degeneracy• Inferring Complementary Products from Baskets and Browsing Sessions• MPRAD: A Multiparametric Radiomics Framework• Optimal Renormalization Group Transformation from Information Theory• Some Double Sums Involving Ratios of Binomial Coefficients Arising From Urn Models• Sparse Recovery and Dictionary Learning from Nonlinear Compressive Measurements• Deep Neural Networks for Pattern Recognition• Non-native children speech recognition through transfer learning• Physical Uplink Control Channel Design for 5G New Radio• BanditSum: Extractive Summarization as a Contextual Bandit• Chip-Firing and Fractional Bases• An upper bound on $\ell_q$ norms of noisy functions• Finding Sparse Solutions for Packing and Covering Semidefinite Programs• A Gradient-Based Split Criterion for Highly Accurate and Transparent Model Trees• Minimal descriptions of cyclic memory behaviors• Sampling-based Polytopic Trees for Approximate Optimal Control of Piecewise Affine Systems• Dynamic detection of anomalous regions within distributed acoustic sensing data streams using locally stationary wavelet time series• Quantum Circuit Designs of Integer Division Optimizing T-count and T-depth• Bayesian Persuasive Driving• La prédiction des intérêts des utilisateurs pour la RI contextuelle et la recommandation d’amis dans un environnement mobile• Surface Type Estimation from GPS Tracked Bicycle Activities• Analyzing CDR/IPDR data to find People Network from Encrypted Messaging Services• Noise Thresholds for Amplification: From Quantum Foundations to Classical Fault-Tolerant Computation• Map matching when the map is wrong: Efficient vehicle tracking on- and off-road for map learning• Confidence Inference for Focused Learning in Stereo Matching• PhotoShape: Photorealistic Materials for Large-Scale Shape Collections• Towards Game-based Metrics for Computational Co-creativity• DSR: Direct Self-rectification for Uncalibrated Dual-lens Cameras• Evolving Agents for the Hanabi 2018 CIG Competition• Night-to-Day Image Translation for Retrieval-based Localization• Rotor walks on transient graphs and the wired spanning forest• Deep contextualized word representations for detecting sarcasm and irony• Penalized Parabolic Relaxation for Optimal Power Flow Problem• Robot Bed-Making: Deep Transfer Learning Using Depth Sensing of Deformable Fabric• Sequential Relaxation of Unit Commitment with AC Transmission Constraints• Predicting Outcome of Indian Premier League (IPL) Matches Using Classification Based Machine Learning Algorithm• Convex Relaxation of Bilinear Matrix Inequalities Part I: Theoretical Results• Convex Relaxation of Bilinear Matrix Inequalities Part II: Applications to Optimal Control Synthesis• Improved bounds on Fourier entropy and Min-entropy• Robust Tube-based Model Predictive Control for Time-constrained Robot Navigation• A Problem Reduction Approach for Visual Relationships Detection• Eigenvalues of Cayley graphs• Notes on toric Fano varieties associated to building sets• Graph Laplacian Regularized Graph Convolutional Networks for Semi-supervised Learning• S-SPADE Done Right: Detailed Study of the Sparse Audio Declipper Algorithms• Stochastic Second-order Methods for Non-convex Optimization with Inexact Hessian and Gradient• Bialgebras for Stanley symmetric functions• Dissecting Tendermint• Converse for Multi-Server Single-Message PIR with Side Information• Phase Diagram of Disordered Higher Order Topological Insulator: a Machine Learning Study• Borodin-Péché fluctuations of the free energy in directed random polymer models• A Two Stage Mechanism For Selling Random Power• Active Learning for Deep Object Detection• 3D Pursuit-Evasion for AUVs• Learning random points from geometric graphs or orderings• Boosting Functional Response Models for Location, Scale and Shape with an Application to Bacterial Competition• Distributed Optimization over Lossy Networks via Relaxed Peaceman-Rachford Splitting: a Robust ADMM Approach• Capturing Model Risk and Rating Momentum in the Estimation of Probabilities of Default and Credit Rating Migrations• A Partition-Based Implementation of the Relaxed ADMM for Distributed Convex Optimization over Lossy Networks• A system reference frame approach for stability analysis and control of power grids• Asymptotics for the maximum regression depth estimator• Some Sufficient Conditions on Pancyclic Graphs• A theoretical investigation of Brockett’s ensemble optimal control problems• Packing coloring of generalized Sierpiński graphs• Generalization Properties of hyper-RKHS and its Application to Out-of-Sample Extensions• A sequence of quasipolynomials arising from random numerical semigroups• Optimal control problems with control complementarity constraints• A Generalized Voltage-Stability Index for Unbalanced Polyphase Power Systems including Thévenin Equivalents and Polynomial Models• Hierarchy-based Image Embeddings for Semantic Image Retrieval• Vision-based Semantic Mapping and Localization for Autonomous Indoor Parking• Unboundedness of Markov complexity of monomial curves in ${\mathbb A}^n$ for $n\geq 4$• Moment ideals of local Dirac mixtures• Perfect weak modular product graphs• Jamming in multilayer supervised learning models• Distances and large deviations in the spatial preferential attachment model• Random Occlusion-recovery for Person Re-identification• Normal Inverse Gaussian Approximation for Arrival Time Difference in Flow-Induced Molecular Communications• Random field solutions to linear SPDEs driven by symmetric pure jump Lévy space-time white noises• Order parameter allows classification of planar graphs based on balanced fixed points in the Kuramoto model• Two-Layer Model Predictive Battery Thermal and Energy Management Optimization for Connected and Automated Electric Vehicles• Using Neural Networks to Generate Information Maps for Mobile Sensors• Weak martingale solutions for the stochastic nonlinear Schrödinger equation driven by pure jump noise• Optimal Control of the Two-Dimensional Vlasov-Maxwell System• There does not exist a distance-regular graph with intersection array ${80, 54,12; 1, 6, 60}$• Computational Courtship: Understanding the Evolution of Online Dating through Large-scale Data Analysis• Integer moments of complex Wishart matrices and Hurwitz numbers• A Randomized Block Coordinate Iterative Regularized Gradient Method for High-dimensional Ill-posed Convex Optimization• Language Modeling Teaches You More Syntax than Translation Does: Lessons Learned Through Auxiliary Task Analysis• On Bioelectric Algorithms: A Novel Application of Theoretical Computer Science to Core Problems in Developmental Biology• Sampling Theory for Graph Signals on Product Graphs• An Iterative Regularized Incremental Projected Subgradient Method for a Class of Bilevel Optimization Problems• General-purpose Declarative Inductive Programming with Domain-Specific Background Knowledge for Data Wrangling Automation• Smart Grids empowerment with Edge Computing: An Overview• Estimates for the difference between approximate and exact solutions to stochastic differential equations in the G-framework• Multi-Cell Multi-User Massive FD-MIMO: Downlink Precoding and Throughput Analysis• Non-monochromatic Triangles in a 2-Edge-Coloured Graph• Residuum-Condition Diagram and Reduction of Over-Complete Endmember-Sets• Pay attention! – Robustifying a Deep Visuomotor Policy through Task-Focused Attention• Joint Hölder continuity of parabolic Anderson model• Photometric Depth Super-Resolution• Redundant Perception and State Estimation for Reliable Autonomous Racing• Electrical networks and frame matroids• Mean and dispersion of harmonic measure• Glorious pairs of roots and Abelian ideals of a Borel subalgebra• Convolutional Neural Networks for Video Quality Assessment• Safely Learning to Control the Constrained Linear Quadratic Regulator• Trading Strategies Generated by Path-dependent Functionals of Market Weights• Learning Navigation Behaviors End to End• Specht modules decompose as alternating sums of restrictions of Schur modules• Dynamic Solar Hosting Capacity Calculations in Microgrids
Like this:
Like Loading…
Related