Multitask Learning on Graph Neural Networks – Learning Multiple Graph Centrality Measures with a Unified Network
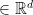

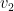





Higher-order Graph Convolutional Networks
Following the success of deep convolutional networks in various vision and speech related tasks, researchers have started investigating generalizations of the well-known technique for graph-structured data. A recently-proposed method called Graph Convolutional Networks has been able to achieve state-of-the-art results in the task of node classification. However, since the proposed method relies on localized first-order approximations of spectral graph convolutions, it is unable to capture higher-order interactions between nodes in the graph. In this work, we propose a motif-based graph attention model, called Motif Convolutional Networks (MCNs), which generalizes past approaches by using weighted multi-hop motif adjacency matrices to capture higher-order neighborhoods. A novel attention mechanism is used to allow each individual node to select the most relevant neighborhood to apply its filter. Experiments show that our proposed method is able to achieve state-of-the-art results on the semi-supervised node classification task.
On the Fly Orchestration of Unikernels: Tuning and Performance Evaluation of Virtual Infrastructure Managers
Network operators are facing significant challenges meeting the demand for more bandwidth, agile infrastructures, innovative services, while keeping costs low. Network Functions Virtualization (NFV) and Cloud Computing are emerging as key trends of 5G network architectures, providing flexibility, fast instantiation times, support of Commercial Off The Shelf hardware and significant cost savings. NFV leverages Cloud Computing principles to move the data-plane network functions from expensive, closed and proprietary hardware to the so-called Virtual Network Functions (VNFs). In this paper we deal with the management of virtual computing resources (Unikernels) for the execution of VNFs. This functionality is performed by the Virtual Infrastructure Manager (VIM) in the NFV MANagement and Orchestration (MANO) reference architecture. We discuss the instantiation process of virtual resources and propose a generic reference model, starting from the analysis of three open source VIMs, namely OpenStack, Nomad and OpenVIM. We improve the aforementioned VIMs introducing the support for special-purpose Unikernels and aiming at reducing the duration of the instantiation process. We evaluate some performance aspects of the VIMs, considering both stock and tuned versions. The VIM extensions and performance evaluation tools are available under a liberal open source licence.
Design and Implementation of High-throughput PCIe with DMA Architecture between FPGA and PowerPC
We designed and implemented a direct memory access (DMA) architecture of PCI-Express(PCIe) between Xilinx Field Program Gate Array(FPGA) and Freescale PowerPC. The DMA architecture based on FPGA is compatible with the Xilinx PCIe core while the DMA architecture based on POWERPC is compatible with VxBus of VxWorks. The solutions provide a high-performance and low-occupancy alternative to commercial. In order to maximize the PCIe throughput while minimizing the FPGA resources utilization, the DMA engine adopts a novel strategy where the DMA register list is stored both inside the FPGA during initialization phase and inside the central memory of the host CPU. The FPGA design package is complemented with simple register access to control the DMA engine by a VxWorks driver. The design is compatible with Xilinx FPGA Kintex Ultrascale Family, and operates with the Xilinx PCIe endpoint Generation 1 with lane configurations x8. A data throughput of more than 666 MBytes/s(memory write with data from FPGA to PowerPC) has been achieved with the single PCIe Gen1 x8 lanes endpoint of this design, PowerPC and FPGA can send memory write request to each other.
An Efficient Approximation Algorithm for Multi-criteria Indoor Route Planning Queries
A route planning query has many real-world applications and has been studied extensively in outdoor spaces such as road networks or Euclidean space. Despite its many applications in indoor venues (e.g., shopping centres, libraries, airports), almost all existing studies are specifically designed for outdoor spaces and do not take into account unique properties of the indoor spaces such as hallways, stairs, escalators, rooms etc. We identify this research gap and formally define the problem of category aware multi-criteria route planning query, denoted by CAM, which returns the optimal route from an indoor source point to an indoor target point that passes through at least one indoor point from each given category while minimizing the total cost of the route in terms of travel distance and other relevant attributes. We show that CAM query is NP-hard. Based on a novel dominance-based pruning, we propose an efficient algorithm which generates high-quality results. We provide an extensive experimental study conducted on the largest shopping centre in Australia and compare our algorithm with alternative approaches. The experiments demonstrate that our algorithm is highly efficient and produces quality results.
Investigating Linguistic Pattern Ordering in Hierarchical Natural Language Generation
Natural language generation (NLG) is a critical component in spoken dialogue system, which can be divided into two phases: (1) sentence planning: deciding the overall sentence structure, (2) surface realization: determining specific word forms and flattening the sentence structure into a string. With the rise of deep learning, most modern NLG models are based on a sequence-to-sequence (seq2seq) model, which basically contains an encoder-decoder structure; these NLG models generate sentences from scratch by jointly optimizing sentence planning and surface realization. However, such simple encoder-decoder architecture usually fail to generate complex and long sentences, because the decoder has difficulty learning all grammar and diction knowledge well. This paper introduces an NLG model with a hierarchical attentional decoder, where the hierarchy focuses on leveraging linguistic knowledge in a specific order. The experiments show that the proposed method significantly outperforms the traditional seq2seq model with a smaller model size, and the design of the hierarchical attentional decoder can be applied to various NLG systems. Furthermore, different generation strategies based on linguistic patterns are investigated and analyzed in order to guide future NLG research work.
A Dataset for Document Grounded Conversations
This paper introduces a document grounded dataset for text conversations. We define ‘Document Grounded Conversations’ as conversations that are about the contents of a specified document. In this dataset the specified documents were Wikipedia articles about popular movies. The dataset contains 4112 conversations with an average of 21.43 turns per conversation. This positions this dataset to not only provide a relevant chat history while generating responses but also provide a source of information that the models could use. We describe two neural architectures that provide benchmark performance on the task of generating the next response. We also evaluate our models for engagement and fluency, and find that the information from the document helps in generating more engaging and fluent responses.
Learning, Planning, and Control in a Monolithic Neural Event Inference Architecture
We introduce a dynamic artificial neural network-based (ANN) adaptive inference process, which learns temporal predictive models of dynamical systems. We term the process REPRISE, a REtrospective and PRospective Inference SchEme. REPRISE infers the unobservable contextual state that best explains its recently encountered sensorimotor experiences as well as accompanying, context-dependent temporal predictive models retrospectively. Meanwhile, it executes prospective inference, optimizing upcoming motor activities in a goal-directed manner. In a first implementation, a recurrent neural network (RNN) is trained to learn a temporal forward model, which predicts the sensorimotor contingencies of different simulated dynamic vehicles. The RNN is augmented with contextual neurons, which enable the compact encoding of distinct, but related sensorimotor dynamics. We show that REPRISE is able to concurrently learn to separate and approximate the encountered sensorimotor dynamics. Moreover, we show that REPRISE can exploit the learned model to induce goal-directed, model-predictive control, that is, approximate active inference: Given a goal state, the system imagines a motor command sequence optimizing it with the prospective objective to minimize the distance to a given goal. Meanwhile, the system evaluates the encountered sensorimotor contingencies retrospectively, adapting its neural hidden states for maintaining model coherence. The RNN activities thus continuously imagine the upcoming future and reflect on the recent past, optimizing both, hidden state and motor activities. In conclusion, the combination of temporal predictive structures with modulatory, generative encodings offers a way to develop compact event codes, which selectively activate particular types of sensorimotor event-specific dynamics.
Bias corrected minimum distance estimator for short and long memory processes
This work proposes a new minimum distance estimator (MDE) for the parameters of short and long memory models. This bias corrected minimum distance estimator (BCMDE) considers a correction in the usual MDE to account for the bias of the sample autocorrelation function when the mean is unknown. We prove the weak consistency of the BCMDE for the general fractional autoregressive moving average (ARFIMA(p, d, q)) model and derive its asymptotic distribution for some particular cases. Simulation studies show that the BCMDE presents a good performance compared to other procedures frequently used in the literature, such as the maximum likelihood estimator, the Whittle estimator and the MDE. The results also show that the BCMDE presents, in general, the smallest mean squared error and is less biased than the MDE when the mean is a non-trivial function of time.
Towards Accountable AI: Hybrid Human-Machine Analyses for Characterizing System Failure
As machine learning systems move from computer-science laboratories into the open world, their accountability becomes a high priority problem. Accountability requires deep understanding of system behavior and its failures. Current evaluation methods such as single-score error metrics and confusion matrices provide aggregate views of system performance that hide important shortcomings. Understanding details about failures is important for identifying pathways for refinement, communicating the reliability of systems in different settings, and for specifying appropriate human oversight and engagement. Characterization of failures and shortcomings is particularly complex for systems composed of multiple machine learned components. For such systems, existing evaluation methods have limited expressiveness in describing and explaining the relationship among input content, the internal states of system components, and final output quality. We present Pandora, a set of hybrid human-machine methods and tools for describing and explaining system failures. Pandora leverages both human and system-generated observations to summarize conditions of system malfunction with respect to the input content and system architecture. We share results of a case study with a machine learning pipeline for image captioning that show how detailed performance views can be beneficial for analysis and debugging.
Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding
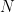
Ranking Distillation: Learning Compact Ranking Models With High Performance for Recommender System
We propose a novel way to train ranking models, such as recommender systems, that are both effective and efficient. Knowledge distillation (KD) was shown to be successful in image recognition to achieve both effectiveness and efficiency. We propose a KD technique for learning to rank problems, called \emph{ranking distillation (RD)}. Specifically, we train a smaller student model to learn to rank documents/items from both the training data and the supervision of a larger teacher model. The student model achieves a similar ranking performance to that of the large teacher model, but its smaller model size makes the online inference more efficient. RD is flexible because it is orthogonal to the choices of ranking models for the teacher and student. We address the challenges of RD for ranking problems. The experiments on public data sets and state-of-the-art recommendation models showed that RD achieves its design purposes: the student model learnt with RD has a model size less than half of the teacher model while achieving a ranking performance similar to the teacher model and much better than the student model learnt without RD.
A Coupled Evolutionary Network for Age Estimation
Age estimation of unknown persons is a challenging pattern analysis task due to the lacking of training data and various aging mechanisms for different people. Label distribution learning-based methods usually make distribution assumptions to simplify age estimation. However, age label distributions are often complex and difficult to be modeled in a parameter way. Inspired by the biological evolutionary mechanism, we propose a Coupled Evolutionary Network (CEN) with two concurrent evolutionary processes: evolutionary label distribution learning and evolutionary slack regression. Evolutionary network learns and refines age label distributions in an iteratively learning way. Evolutionary label distribution learning adaptively learns and constantly refines the age label distributions without making strong assumptions on the distribution patterns. To further utilize the ordered and continuous information of age labels, we accordingly propose an evolutionary slack regression to convert the discrete age label regression into the continuous age interval regression. Experimental results on Morph, ChaLearn15 and MegaAge-Asian datasets show the superiority of our method.
Time is of the Essence: Machine Learning-based Intrusion Detection in Industrial Time Series Data
The Industrial Internet of Things drastically increases connectivity of devices in industrial applications. In addition to the benefits in efficiency, scalability and ease of use, this creates novel attack surfaces. Historically, industrial networks and protocols do not contain means of security, such as authentication and encryption, that are made necessary by this development. Thus, industrial IT-security is needed. In this work, emulated industrial network data is transformed into a time series and analysed with three different algorithms. The data contains labeled attacks, so the performance can be evaluated. Matrix Profiles perform well with almost no parameterisation needed. Seasonal Autoregressive Integrated Moving Average performs well in the presence of noise, requiring parameterisation effort. Long Short Term Memory-based neural networks perform mediocre while requiring a high training- and parameterisation effort.
DuPLO: A DUal view Point deep Learning architecture for time series classificatiOn
Nowadays, modern Earth Observation systems continuously generate huge amounts of data. A notable example is represented by the Sentinel-2 mission, which provides images at high spatial resolution (up to 10m) with high temporal revisit period (every 5 days), which can be organized in Satellite Image Time Series (SITS). While the use of SITS has been proved to be beneficial in the context of Land Use/Land Cover (LULC) map generation, unfortunately, machine learning approaches commonly leveraged in remote sensing field fail to take advantage of spatio-temporal dependencies present in such data. Recently, new generation deep learning methods allowed to significantly advance research in this field. These approaches have generally focused on a single type of neural network, i.e., Convolutional Neural Networks (CNNs) or Recurrent Neural Networks (RNNs), which model different but complementary information: spatial autocorrelation (CNNs) and temporal dependencies (RNNs). In this work, we propose the first deep learning architecture for the analysis of SITS data, namely \method{} (DUal view Point deep Learning architecture for time series classificatiOn), that combines Convolutional and Recurrent neural networks to exploit their complementarity. Our hypothesis is that, since CNNs and RNNs capture different aspects of the data, a combination of both models would produce a more diverse and complete representation of the information for the underlying land cover classification task. Experiments carried out on two study sites characterized by different land cover characteristics (i.e., the \textit{Gard} site in France and the \textit{Reunion Island} in the Indian Ocean), demonstrate the significance of our proposal.
Sparsified SGD with Memory
Huge scale machine learning problems are nowadays tackled by distributed optimization algorithms, i.e. algorithms that leverage the compute power of many devices for training. The communication overhead is a key bottleneck that hinders perfect scalability. Various recent works proposed to use quantization or sparsification techniques to reduce the amount of data that needs to be communicated, for instance by only sending the most significant entries of the stochastic gradient (top-k sparsification). Whilst such schemes showed very promising performance in practice, they have eluded theoretical analysis so far. In this work we analyze Stochastic Gradient Descent (SGD) with k-sparsification or compression (for instance top-k or random-k) and show that this scheme converges at the same rate as vanilla SGD when equipped with error compensation (keeping track of accumulated errors in memory). That is, communication can be reduced by a factor of the dimension of the problem (sometimes even more) whilst still converging at the same rate. We present numerical experiments to illustrate the theoretical findings and the better scalability for distributed applications.
Spline-Based Probability Calibration
In many classification problems it is desirable to output well-calibrated probabilities on the different classes. We propose a robust, non-parametric method of calibrating probabilities called SplineCalib that utilizes smoothing splines to determine a calibration function. We demonstrate how applying certain transformations as part of the calibration process can improve performance on problems in deep learning and other domains where the scores tend to be ‘overconfident’. We adapt the approach to multi-class problems and find that better calibration can improve accuracy as well as log-loss by better resolving uncertain cases. Finally, we present a cross-validated approach to calibration which conserves data. Significant improvements to log-loss and accuracy are shown on several different problems. We also introduce the ml-insights python package which contains an implementation of the SplineCalib algorithm.
PriPeARL: A Framework for Privacy-Preserving Analytics and Reporting at LinkedIn
Preserving privacy of users is a key requirement of web-scale analytics and reporting applications, and has witnessed a renewed focus in light of recent data breaches and new regulations such as GDPR. We focus on the problem of computing robust, reliable analytics in a privacy-preserving manner, while satisfying product requirements. We present PriPeARL, a framework for privacy-preserving analytics and reporting, inspired by differential privacy. We describe the overall design and architecture, and the key modeling components, focusing on the unique challenges associated with privacy, coverage, utility, and consistency. We perform an experimental study in the context of ads analytics and reporting at LinkedIn, thereby demonstrating the tradeoffs between privacy and utility needs, and the applicability of privacy-preserving mechanisms to real-world data. We also highlight the lessons learned from the production deployment of our system at LinkedIn.
• Tableaux posets and the fake degrees of coinvariant algebras• ReSyst: a novel technique to Reduce the Systematic uncertainty for precision measurements• Fundamentals on Base Stations in Cellular Networks: From the Perspective of Algebraic Topology• Fighting Redundancy and Model Decay with Embeddings• On Information Transfer Based Characterization of Power System Stability• Model Predictive Controller with Average Emissions Constraints for Diesel Airpath• Deep Hybrid Scattering Image Learning• Autonomous Driving System Design for Formula Student Driverless Racecar• The Read-Optimized Burrows-Wheeler Transform• A game theoretic approach to a network allocation problem• A Generalized Representer Theorem for Hilbert Space – Valued Functions• Revisit of the Eigenfilter Method for the Design of FIR Filters and Wideband Beamformers• Analyzing Social Book Reading Behavior on Goodreads and how it predicts Amazon Best Sellers• Predictive Model for SSVEP Magnitude Variation: Applications to Continuous Control in Brain-Computer Interfaces• Combined Image- and World-Space Tracking in Traffic Scenes• Parameter Recovery with Marginal Maximum Likelihood and Markov Chain Monte Carlo Estimation for the Generalized Partial Credit Model• Stationary distributions and condensation in autocatalytic CRN• Exact formulas of the transition probabilities of the multi-species asymmetric simple exclusion process• Zero-error communication over adder MAC• Decentralized Resource Allocation via Dual Consensus ADMM• Critical groups of iterated cones• On Distance Magic Harary Graphs• Geometric Convergence of Gradient Play Algorithms for Distributed Nash Equilibrium Seeking• New insights on the optimality of parameterized wiener filters for speech enhancement applications• A general framework for secondary constructions of bent and plateaued functions• Improved Bounds on Information Dissemination by Manhattan Random Waypoint Model• Improving Subseasonal Forecasting in the Western U.S. with Machine Learning• Permutation Weights and a $q$-Analogue of the Eulerian Polynomials• Nonisometric Surface Registration via Conformal Laplace-Beltrami Basis Pursuit• Transmission of Macroeconomic Shocks to Risk Parameters: Their uses in Stress Testing• Identifying Generalization Properties in Neural Networks• Distances for WiFi Based Topological Indoor Mapping• Exploiting Tournament Selection for Efficient Parallel Genetic Programming• Egocentric Vision-based Future Vehicle Localization for Intelligent Driving Assistance Systems• Deep Part Induction from Articulated Object Pairs• Randomization Tests for Weak Null Hypotheses• Time dependent fracture under unloading in a fiber bundle model• Sub-Gaussian Mean Estimation in Polynomial Time• CRN++: Molecular Programming Language• On the Cheng-Yau gradient estimate for Carnot groups and sub-Riemannian manifolds• Predicting Periodicity with Temporal Difference Learning• Deep Generative Classifiers for Thoracic Disease Diagnosis with Chest X-ray Images• Distribution-Free Prediction Sets with Random Effects• DP-3-coloring of planar graphs without $4,9$-cycles and two cycles from ${5,6,7,8}$• Tight Continuous-Time Reachtubes for Lagrangian Reachability• Uplink Resource Allocation for Multiple Access Computational Offloading• TasNet: Surpassing Ideal Time-Frequency Masking for Speech Separation• Towards Discrete Solution: A Sparse Preserving Method for Correspondence Problem• Parity of the Partition Function p(n,k)• Absolute moments in terms of characteristic functions• Data Shuffling in Wireless Distributed Computing via Low-Rank Optimization• Joint Distributions of Permutation Statistics and the Parabolic Cylinder Functions• Joint Routing and Resource Allocation for Millimeter Wave Picocellular Backhaul• Local Density Estimation in High Dimensions• Thermally and field-driven mobility of emergent magnetic charges in square artificial spin ice• PP-DBLP: Modeling and Generating Attributed Public-Private Networks with DBLP• Compact Low-Profile Wearable Antennas For Breast Cancer Detection• Zero-shot Sim-to-Real Transfer with Modular Priors• $L_1$ Shortest Path Queries in Simple Polygons• Optimal Guaranteed Cost Control of Discrete-Time Linear Systems subject to Structured Uncertainties• Building Context-aware Clause Representations for Situation Entity Type Classification• A Quantitative Evaluation of Natural Language Question Interpretation for Question Answering Systems• Probabilistic Assessment of PV-Battery System Impacts on LV Distribution Networks• Percolation on Homology Generators in Codimension One• OxIOD: The Dataset for Deep Inertial Odometry• Impacts of Community and Distributed Energy Storage Systems on Unbalanced Low Voltage Networks• Learning a Local Feature Descriptor for 3D LiDAR Scans• Optimal mass transport and kernel density estimation for state-dependent networked dynamic systems• MASON: A Model AgnoStic ObjectNess Framework• Local module identification in dynamic networks with correlated noise: the full input case• Cut Topology Optimization for Linear Elasticity with Coupling to Parametric Nondesign Domain Regions• 2018 PIRM Challenge on Perceptual Image Super-resolution• Variable Martingale Hardy Spaces and Their Applications in Fourier Analysis• Catalan-like numbers and Hausdorff moment sequences• Triangle resilience of the square of a Hamilton cycle in random graphs• Multiple Preambles for High Success Rate of Grant-Free Random Access with Massive MIMO• Layered BPSK for High Data Rates• On the self-similarity of line segments in decaying homogeneous isotropic turbulence• Admissibility of the usual confidence set for the mean of a univariate or bivariate normal population: The unknown-variance case• Insider Trading with Penalties• Quasi-stationarity for one-dimensional renormalized Brownian motion• Dynamic Adaptive Computation: Tuning network states to task requirements• On tight $4$-designs in Hamming association schemes• Controllability of a linear system with persistent memory via boundary traction• RGBD2lux: Dense light intensity estimation with an RGBD sensor• Analysis of boundary effects on PDE-based sampling of Whittle-Matérn random fields• Challenges for Toxic Comment Classification: An In-Depth Error Analysis• An interesting family of posets• Symbolic Music Genre Transfer with CycleGAN• New $L^2$-type exponentiality tests• A Fast and Accurate System for Face Detection, Identification, and Verification• Emergence of extended states at zero in the spectrum of sparse random graphs• MIDI-VAE: Modeling Dynamics and Instrumentation of Music with Applications to Style Transfer• High-order structure functions for passive scalar fed by a mean gradient• Syntactico-Semantic Reasoning using PCFG, MEBN, and PR-OWL• Machine Learning for semi linear PDEs• Throughput-Improving Control of Highways Facing Stochastic Perturbations• Optimization of hybrid parallel application execution in heterogeneous high performance computing systems considering execution time and power consumption• Lessons learned in multilingual grounded language learning• On constructing orthogonal generalized doubly stochastic matrices• Faster RER-CNN: application to the detection of vehicles in aerial images• Properties of a $q$-analogue of zero forcing• The dual cone of sums of non-negative circuit polynomials• The unreasonable effectiveness of small neural ensembles in high-dimensional brain• Joint Multilingual Supervision for Cross-lingual Entity Linking• Very Highly Skilled Individuals Do Not Choke Under Pressure: Evidence from Professional Darts• Small Uncolored and Colored Choice Dictionaries• Residual stresses in metal deposition modeling: discretizations of higher order• Dynamic Power Control for Packets with Deadlines• Real Time Dense Depth Estimation by Fusing Stereo with Sparse Depth Measurements• Modeling a Double-Spending Detection System for the Bitcoin Network• Hybrid Precoding-Based Millimeter-Wave Massive MIMO-NOMA with Simultaneous Wireless Information and Power Transfer• On Pareto eigenvalue of distance matrix of graphs• On the largest $A_α$-spectral radius of cacti• Symbolic Priors for RNN-based Semantic Parsing• Specimens as research objects: reconciliation across distributed repositories to enable metadata propagation• The Abelian sandpile model on Ferrers graphs – A classification of recurrent configurations• Evolutionary hypergame dynamics• Benchmarking Reinforcement Learning Algorithms on Real-World Robots• Kernel Density Estimation with Linked Boundary Conditions• Low independence number and Hamiltonicity implies pancyclicity• Capacity lower bound for the Ising perceptron• Shapley-like values without symmetry• Exemplar-based synthesis of geology using kernel discrepancies and generative neural networks• Stability for Take-Away Games• Aldous diffusion I: a projective system of continuum $k$-tree evolutions• Implementing Adaptive Separable Convolution for Video Frame Interpolation
Like this:
Like Loading…
Related