Multi-hop assortativities for networks classification
Several social, medical, engineering and biological challenges rely on discovering the functionality of networks from their structure and node metadata, when is available. For example, in chemoinformatics one might want to detect whether a molecule is toxic based on structure and atomic types, or discover the research field for scientific collaboration networks. Existing techniques rely on counting or measuring structural patterns that are known to show large variations from network to network, such as number of triangles, or the assortativity of node metadata. We introduce the concept of multi-hop assortativity, that captures the similarity of node situated at the extremities of a randomly selected path of a given length. We show that multi-hop assortativity unifies various existing concepts and offers a versatile family of fingerprints to characterize networks. These fingerprints allow in turn to recover the functionalities of a network, with the help of the machine learning toolbox. Our method is evaluated empirically on established social and chemoinformatic network benchmarks. Results reveal that our assortativity based features are competitive providing highly accurate results often outperforming state of the art methods for the network classification task
Multiple Workflows Scheduling in Multi-tenant Distributed Systems: A Taxonomy and Future Directions
Scientific workflows are commonly used to automate scientific experiments. The automation ensures the applications being executed in the order. This feature attracts more scientists to build the workflow. However, the computational requirements are enormous. To cater the broader needs, the multi-tenant platforms for scientific workflows in distributed systems environment were built. In this paper, we identify the problems and challenges in the multiple workflows scheduling that adhere to the multi-tenant platforms in distributed systems environment. We present a detailed taxonomy from the existing solutions on scheduling and resource provisioning aspects followed by the survey in this area. We open up the problems and challenges to shove up the research on multiple workflows scheduling in multi-tenant distributed systems.
Ensemble Clustering for Graphs
We propose an ensemble clustering algorithm for graphs (ECG), which is based on the Louvain algorithm and the concept of consensus clustering. We validate our approach by replicating a recently published study comparing graph clustering algorithms over artificial networks, showing that ECG outperforms the leading algorithms from that study. We also illustrate how the ensemble obtained with ECG can be used to quantify the presence of community structure in the graph.
The Generic Holdout: Preventing False-Discoveries in Adaptive Data Science
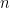
Multi-Task Learning for Email Search Ranking with Auxiliary Query Clustering
User information needs vary significantly across different tasks, and therefore their queries will also differ considerably in their expressiveness and semantics. Many studies have been proposed to model such query diversity by obtaining query types and building query-dependent ranking models. These studies typically require either a labeled query dataset or clicks from multiple users aggregated over the same document. These techniques, however, are not applicable when manual query labeling is not viable, and aggregated clicks are unavailable due to the private nature of the document collection, e.g., in email search scenarios. In this paper, we study how to obtain query type in an unsupervised fashion and how to incorporate this information into query-dependent ranking models. We first develop a hierarchical clustering algorithm based on truncated SVD and varimax rotation to obtain coarse-to-fine query types. Then, we study three query-dependent ranking models, including two neural models that leverage query type information as additional features, and one novel multi-task neural model that views query type as the label for the auxiliary query cluster prediction task. This multi-task model is trained to simultaneously rank documents and predict query types. Our experiments on tens of millions of real-world email search queries demonstrate that the proposed multi-task model can significantly outperform the baseline neural ranking models, which either do not incorporate query type information or just simply feed query type as an additional feature.
ROC-Guided Survival Trees and Forests
Tree-based methods are popular nonparametric tools in studying time-to-event outcomes. In this article, we introduce a novel framework for survival trees and forests, where the trees partition the dynamic survivor population and can handle time-dependent covariates. Using the idea of randomized tests, we develop generalized time-dependent ROC curves to evaluate the performance of survival trees and establish the optimality of the target hazard function with respect to the ROC curve. The tree-growing algorithm is guided by decision-theoretic criteria based on ROC, targeting specifically for prediction accuracy. While existing survival trees with time-dependent covariates have practical limitations due to ambiguous prediction, the proposed method provides a consistent prediction of the failure risk. We further extend the survival trees to random forests, where the ensemble is based on martingale estimating equations, in contrast with many existing survival forest algorithms that average the predicted survival or cumulative hazard functions. Simulations studies demonstrate strong performances of the proposed methods. We apply the methods to a study on AIDS for illustration.
Towards Better Interpretability in Deep Q-Networks
Deep reinforcement learning techniques have demonstrated superior performance in a wide variety of environments. As improvements in training algorithms continue at a brisk pace, theoretical or empirical studies on understanding what these networks seem to learn, are far behind. In this paper we propose an interpretable neural network architecture for Q-learning which provides a global explanation of the model’s behavior using key-value memories, attention and reconstructible embeddings. With a directed exploration strategy, our model can reach training rewards comparable to the state-of-the-art deep Q-learning models. However, results suggest that the features extracted by the neural network are extremely shallow and subsequent testing using out-of-sample examples shows that the agent can easily overfit to trajectories seen during training.
Detecting and Explaining Drifts in Yearly Grant Applications
During the lifetime of a Business Process changes can be made to the workflow, the required resources, required documents, . . . . Different traces from the same Business Process within a single log file can thus differ substantially due to these changes. We propose a method that is able to detect concept drift in multivariate log files with a dozen attributes. We test our approach on the BPI Challenge 2018 data con- sisting of applications for EU direct payment from farmers in Germany where we use it to detect Concept Drift. In contrast to other methods our algorithm does not require the manual selection of the features used to detect drift. Our method first creates a model that captures the re- lations between attributes and between events of different time steps. This model is then used to score every event and trace. These scores can be used to detect outlying cases and concept drift. Thanks to the decomposability of the score we are able to perform detailed root-cause analysis.
Wasserstein Autoencoders for Collaborative Filtering


Deterministic Implementations for Reproducibility in Deep Reinforcement Learning
While deep reinforcement learning (DRL) has led to numerous successes in recent years, reproducing these successes can be extremely challenging. One reproducibility challenge particularly relevant to DRL is nondeterminism in the training process, which can substantially affect the results. Motivated by this challenge, we study the positive impacts of deterministic implementations in eliminating nondeterminism in training. To do so, we consider the particular case of the deep Q-learning algorithm, for which we produce a deterministic implementation by identifying and controlling all sources of nondeterminism in the training process. One by one, we then allow individual sources of nondeterminism to affect our otherwise deterministic implementation, and measure the impact of each source on the variance in performance. We find that individual sources of nondeterminism can substantially impact the performance of agent, illustrating the benefits of deterministic implementations. In addition, we also discuss the important role of deterministic implementations in achieving exact replicability of results.
Graph Convolutional Networks for Text Classification
Text Classification is an important and classical problem in natural language processing. There have been a number of studies that applied convolutional neural networks (convolution on regular grid, e.g., sequence) to classification. However, only a limited number of studies have explored the more flexible graph convolutional neural networks (e.g., convolution on non-grid, e.g., arbitrary graph) for the task. In this work, we propose to use graph convolutional networks for text classification. We build a single text graph for a corpus based on word co-occurrence and document word relations, then learn a Text Graph Convolutional Network (Text GCN) for the corpus. Our Text GCN is initialized with one-hot representation for word and document, it then jointly learns the embeddings for both words and documents, as supervised by the known class labels for documents. Our experimental results on multiple benchmark datasets demonstrate that a vanilla Text GCN without any external word embeddings or knowledge outperforms state-of-the-art methods for text classification. On the other hand, Text GCN also learns predictive word and document embeddings. In addition, experimental results show that the improvement of Text GCN over state-of-the-art comparison methods become more prominent as we lower the percentage of training data, suggesting the robustness of Text GCN to less training data in text classification.
CLUSE: Cross-Lingual Unsupervised Sense Embeddings
This paper proposes a modularized sense induction and representation learning model that jointly learns bilingual sense embeddings that align well in the vector space, where the cross-lingual signal in the English-Chinese parallel corpus is exploited to capture the collocation and distributed characteristics in the language pair. The model is evaluated on the Stanford Contextual Word Similarity (SCWS) dataset to ensure the quality of monolingual sense embeddings. In addition, we introduce Bilingual Contextual Word Similarity (BCWS), a large and high-quality dataset for evaluating cross-lingual sense embeddings, which is the first attempt of measuring whether the learned embeddings are indeed aligned well in the vector space. The proposed approach shows the superior quality of sense embeddings evaluated in both monolingual and bilingual spaces.
Annotations for Rule-Based Models
The chapter reviews the syntax to store machine-readable annotations and describes the mapping between rule-based modelling entities (e.g., agents and rules) and these annotations. In particular, we review an annotation framework and the associated guidelines for annotating rule-based models of molecular interactions, encoded in the commonly used Kappa and BioNetGen languages, and present prototypes that can be used to extract and query the annotations. An ontology is used to annotate models and facilitate their description.
Alternate Estimation of a Classifier and the Class-Prior from Positive and Unlabeled Data
We consider a problem of learning a binary classifier only from positive data and unlabeled data (PU learning) and estimating the class-prior in unlabeled data under the case-control scenario. Most of the recent methods of PU learning require an estimate of the class-prior probability in unlabeled data, and it is estimated in advance with another method. However, such a two-step approach which first estimates the class prior and then trains a classifier may not be the optimal approach since the estimation error of the class-prior is not taken into account when a classifier is trained. In this paper, we propose a novel unified approach to estimating the class-prior and training a classifier alternately. Our proposed method is simple to implement and computationally efficient. Through experiments, we demonstrate the practical usefulness of the proposed method.
Multi-Scale Deep Compressive Sensing Network
With joint learning of sampling and recovery, the deep learning-based compressive sensing (DCS) has shown significant improvement in performance and running time reduction. Its reconstructed image, however, losses high-frequency content especially at low subrates. This happens similarly in the multi-scale sampling scheme which also samples more low-frequency components. In this paper, we propose a multi-scale DCS convolutional neural network (MS-DCSNet) in which we convert image signal using multiple scale-based wavelet transform, then capture it through convolution block by block across scales. The initial reconstructed image is directly recovered from multi-scale measurements. Multi-scale wavelet convolution is utilized to enhance the final reconstruction quality. The network is able to learn both multi-scale sampling and multi-scale reconstruction, thus results in better reconstruction quality.
Incorporating Behavioral Constraints in Online AI Systems
AI systems that learn through reward feedback about the actions they take are increasingly deployed in domains that have significant impact on our daily life. However, in many cases the online rewards should not be the only guiding criteria, as there are additional constraints and/or priorities imposed by regulations, values, preferences, or ethical principles. We detail a novel online agent that learns a set of behavioral constraints by observation and uses these learned constraints as a guide when making decisions in an online setting while still being reactive to reward feedback. To define this agent, we propose to adopt a novel extension to the classical contextual multi-armed bandit setting and we provide a new algorithm called Behavior Constrained Thompson Sampling (BCTS) that allows for online learning while obeying exogenous constraints. Our agent learns a constrained policy that implements the observed behavioral constraints demonstrated by a teacher agent, and then uses this constrained policy to guide the reward-based online exploration and exploitation. We characterize the upper bound on the expected regret of the contextual bandit algorithm that underlies our agent and provide a case study with real world data in two application domains. Our experiments show that the designed agent is able to act within the set of behavior constraints without significantly degrading its overall reward performance.
Statistical Inference for Mixture of Cauchy Distributions
Improving Natural Language Inference Using External Knowledge in the Science Questions Domain
Natural Language Inference (NLI) is fundamental to many Natural Language Processing (NLP) applications including semantic search and question answering. The NLI problem has gained significant attention thanks to the release of large scale, challenging datasets. Present approaches to the problem largely focus on learning-based methods that use only textual information in order to classify whether a given premise entails, contradicts, or is neutral with respect to a given hypothesis. Surprisingly, the use of methods based on structured knowledge — a central topic in artificial intelligence — has not received much attention vis-a-vis the NLI problem. While there are many open knowledge bases that contain various types of reasoning information, their use for NLI has not been well explored. To address this, we present a combination of techniques that harness knowledge graphs to improve performance on the NLI problem in the science questions domain. We present the results of applying our techniques on text, graph, and text-to-graph based models, and discuss implications for the use of external knowledge in solving the NLI problem. Our model achieves the new state-of-the-art performance on the NLI problem over the SciTail science questions dataset.
Inter-Rater: Software for analysis of inter-rater reliability by permutating pairs of multiple users
Inter-Rater quantifies the reliability between multiple raters who evaluate a group of subjects. It calculates the group quantity, Fleiss kappa, and it improves on existing software by keeping information about each user and quantifying how each user agreed with the rest of the group. This is accomplished through permutations of user pairs. The software was written in Python, can be run in Linux, and the code is deposited in Zenodo and GitHub. This software can be used for evaluation of inter-rater reliability in systematic reviews, medical diagnosis algorithms, education applications, and others.
Using Artificial Intelligence to Support Compliance with the General Data Protection Regulation
The General Data Protection Regulation (GDPR) is a European Union regulation that will replace the existing Data Protection Directive on 25 May 2018. The most significant change is a huge increase in the maximum fine that can be levied for breaches of the regulation. Yet fewer than half of UK companies are fully aware of GDPR – and a number of those who were preparing for it stopped doing so when the Brexit vote was announced. A last-minute rush to become compliant is therefore expected, and numerous companies are starting to offer advice, checklists and consultancy on how to comply with GDPR. In such an environment, artificial intelligence technologies ought to be able to assist by providing best advice; asking all and only the relevant questions; monitoring activities; and carrying out assessments. The paper considers four areas of GDPR compliance where rule based technologies and/or machine learning techniques may be relevant: * Following compliance checklists and codes of conduct; * Supporting risk assessments; * Complying with the new regulations regarding technologies that perform automatic profiling; * Complying with the new regulations concerning recognising and reporting breaches of security. It concludes that AI technology can support each of these four areas. The requirements that GDPR (or organisations that need to comply with GDPR) state for explanation and justification of reasoning imply that rule-based approaches are likely to be more helpful than machine learning approaches. However, there may be good business reasons to take a different approach in some circumstances.
Direct Training for Spiking Neural Networks: Faster, Larger, Better
Spiking neural networks (SNNs) are gaining more attention as a promising way that enables energy efficient implementation on emerging neuromorphic hardware. Yet now, SNNs have not shown competitive performance compared with artificial neural networks (ANNs), due to the lack of effective learning algorithms and efficient programming frameworks. We address this issue from two aspects: (1) We propose a neuron normalization technique to adjust the neural selectivity and develop a direct learning algorithm for large-scale SNNs. (2) We present a Pytorch-based implementation method towards the training of deep SNNs by narrowing the rate coding window and converting the leaky integrate-and-fire (LIF) model into an explicitly iterative version. With this method, we are able to train large-scale SNNs with tens of times speedup. As a result, we achieve significantly better accuracy than the reported works on neuromorphic datasets (N-MNIST and DVS-CIFAR10), and comparable accuracy as existing ANNs and pre-trained SNNs on non-spiking datasets (CIFAR10). To our best knowledge, this is the first work that demonstrates direct training of large-scale SNNs with high performance, and the efficient implementation is a key step to explore the potential of SNNs.
Dual Memory Network Model for Biased Product Review Classification
In sentiment analysis (SA) of product reviews, both user and product information are proven to be useful. Current tasks handle user profile and product information in a unified model which may not be able to learn salient features of users and products effectively. In this work, we propose a dual user and product memory network (DUPMN) model to learn user profiles and product reviews using separate memory networks. Then, the two representations are used jointly for sentiment prediction. The use of separate models aims to capture user profiles and product information more effectively. Compared to state-of-the-art unified prediction models, the evaluations on three benchmark datasets, IMDB, Yelp13, and Yelp14, show that our dual learning model gives performance gain of 0.6%, 1.2%, and 0.9%, respectively. The improvements are also deemed very significant measured by p-values.
A Novel Algorithm for Unbiased Learning to Rank
Although click data is widely used in search systems in practice, so far the inherent bias, most notably position bias, has prevented it from being used in training of a ranker for search, i.e., learning-to-rank. Recently, a number of authors have proposed new techniques referred to as ‘unbiased learning-to-rank’, which can reduce position bias and train a relatively high-performance ranker using click data. Most of the algorithms, based on the inverse propensity weighting (IPW) principle, first estimate the click bias at each position, and then train an unbiased ranker with the estimated biases using a learning-to-rank algorithm. However, there has not been a method for pairwise learning-to-rank that can jointly conduct debiasing of click data and training of a ranker using a pairwise loss function. In this paper, we propose a novel algorithm, which can jointly estimate the biases at click positions and the biases at unclick positions, and learn an unbiased ranker. Experiments on benchmark data show that our algorithm can significantly outperform existing algorithms. In addition, an online A/B Testing at a commercial search engine shows that our algorithm can effectively conduct debiasing of click data and enhance relevance ranking.
Cross-Domain Labeled LDA for Cross-Domain Text Classification
Cross-domain text classification aims at building a classifier for a target domain which leverages data from both source and target domain. One promising idea is to minimize the feature distribution differences of the two domains. Most existing studies explicitly minimize such differences by an exact alignment mechanism (aligning features by one-to-one feature alignment, projection matrix etc.). Such exact alignment, however, will restrict models’ learning ability and will further impair models’ performance on classification tasks when the semantic distributions of different domains are very different. To address this problem, we propose a novel group alignment which aligns the semantics at group level. In addition, to help the model learn better semantic groups and semantics within these groups, we also propose a partial supervision for model’s learning in source domain. To this end, we embed the group alignment and a partial supervision into a cross-domain topic model, and propose a Cross-Domain Labeled LDA (CDL-LDA). On the standard 20Newsgroup and Reuters dataset, extensive quantitative (classification, perplexity etc.) and qualitative (topic detection) experiments are conducted to show the effectiveness of the proposed group alignment and partial supervision.
f-VAEs: Improve VAEs with Conditional Flows
In this paper, we integrate VAEs and flow-based generative models successfully and get f-VAEs. Compared with VAEs, f-VAEs generate more vivid images, solved the blurred-image problem of VAEs. Compared with flow-based models such as Glow, f-VAE is more lightweight and converges faster, achieving the same performance under smaller-size architecture.
Continuous-Time Robust Dynamic Programming
This paper presents a new theory, known as robust dynamic programming, for a class of continuous-time dynamical systems. Different from traditional dynamic programming (DP) methods, this new theory serves as a fundamental tool to analyze the robustness of DP algorithms, and in particular, to develop novel adaptive optimal control and reinforcement learning methods. In order to demonstrate the potential of this new framework, four illustrative applications in the fields of stochastic optimal control and adaptive DP are presented. Three numerical examples arising from both finance and engineering industries are also given, along with several possible extensions of the proposed framework.
On-Line Learning of Linear Dynamical Systems: Exponential Forgetting in Kalman Filters
Kalman filter is a key tool for time-series forecasting and analysis. We show that the dependence of a prediction of Kalman filter on the past is decaying exponentially, whenever the process noise is non-degenerate. Therefore, Kalman filter may be approximated by regression on a few recent observations. Surprisingly, we also show that having some process noise is essential for the exponential decay. With no process noise, it may happen that the forecast depends on all of the past uniformly, which makes forecasting more difficult. Based on this insight, we devise an on-line algorithm for improper learning of a linear dynamical system (LDS), which considers only a few most recent observations. We use our decay results to provide the first regret bounds w.r.t. to Kalman filters within learning an LDS. That is, we compare the results of our algorithm to the best, in hindsight, Kalman filter for a given signal. Also, the algorithm is practical: its per-update run-time is linear in the regression depth.
A Data Analytics Framework for Aggregate Data Analysis
In many contexts, we have access to aggregate data, but individual level data is unavailable. For example, medical studies sometimes report only aggregate statistics about disease prevalence because of privacy concerns. Even so, many a time it is desirable, and in fact could be necessary to infer individual level characteristics from aggregate data. For instance, other researchers who want to perform more detailed analysis of disease characteristics would require individual level data. Similar challenges arise in other fields too including politics, and marketing. In this paper, we present an end-to-end pipeline for processing of aggregate data to derive individual level statistics, and then using the inferred data to train machine learning models to answer questions of interest. We describe a novel algorithm for reconstructing fine-grained data from summary statistics. This step will create multiple candidate datasets which will form the input to the machine learning models. The advantage of the highly parallel architecture we propose is that uncertainty in the generated fine-grained data will be compensated by the use of multiple candidate fine-grained datasets. Consequently, the answers derived from the machine learning models will be more valid and usable. We validate our approach using data from a challenging medical problem called Acute Traumatic Coagulopathy.
An investigation of a deep learning based malware detection system
We investigate a Deep Learning based system for malware detection. In the investigation, we experiment with different combination of Deep Learning architectures including Auto-Encoders, and Deep Neural Networks with varying layers over Malicia malware dataset on which earlier studies have obtained an accuracy of (98%) with an acceptable False Positive Rates (1.07%). But these results were done using extensive man-made custom domain features and investing corresponding feature engineering and design efforts. In our proposed approach, besides improving the previous best results (99.21% accuracy and a False Positive Rate of 0.19%) indicates that Deep Learning based systems could deliver an effective defense against malware. Since it is good in automatically extracting higher conceptual features from the data, Deep Learning based systems could provide an effective, general and scalable mechanism for detection of existing and unknown malware.
Classifying Process Instances Using Recurrent Neural Networks
Process Mining consists of techniques where logs created by operative systems are transformed into process models. In process mining tools it is often desired to be able to classify ongoing process instances, e.g., to predict how long the process will still require to complete, or to classify process instances to different classes based only on the activities that have occurred in the process instance thus far. Recurrent neural networks and its subclasses, such as Gated Recurrent Unit (GRU) and Long Short-Term Memory (LSTM), have been demonstrated to be able to learn relevant temporal features for subsequent classification tasks. In this paper we apply recurrent neural networks to classifying process instances. The proposed model is trained in a supervised fashion using labeled process instances extracted from event log traces. This is the first time we know of GRU having been used in classifying business process instances. Our main experimental results shows that GRU outperforms LSTM remarkably in training time while giving almost identical accuracies to LSTM models. Additional contributions of our paper are improving the classification model training time by filtering infrequent activities, which is a technique commonly used, e.g., in Natural Language Processing (NLP).
Memory Efficient Experience Replay for Streaming Learning
In supervised machine learning, an agent is typically trained once and then deployed. While this works well for static settings, robots often operate in changing environments and must quickly learn new things from data streams. In this paradigm, known as streaming learning, a learner is trained online, in a single pass, from a data stream that cannot be assumed to be independent and identically distributed (iid). Streaming learning will cause conventional deep neural networks (DNNs) to fail for two reasons: 1) they need multiple passes through the entire dataset; and 2) non-iid data will cause catastrophic forgetting. An old fix to both of these issues is rehearsal. To learn a new example, rehearsal mixes it with previous examples, and then this mixture is used to update the DNN. Full rehearsal is slow and memory intensive because it stores all previously observed examples, and its effectiveness for preventing catastrophic forgetting has not been studied in modern DNNs. Here, we describe the ExStream algorithm for memory efficient rehearsal and compare it to alternatives. We find that full rehearsal can eliminate catastrophic forgetting in a variety of streaming learning settings, with ExStream performing well using far less memory and computation.
• Player Experience Extraction from Gameplay Video• Binary Classification of Alzheimer Disease using sMRI Imaging modality and Deep Learning• ManifoldNet: A Deep Network Framework for Manifold-valued Data• Context-Dependent Diffusion Network for Visual Relationship Detection• Computer Aided Automatic Brain Segmentation from Computed Tomography Images using Multilevel Masking• Unsupervised Stylish Image Description Generation via Domain Layer Norm• A Dataset and Preliminary Results for Umpire Pose Detection Using SVM Classification of Deep Features• Facial Recognition with Encoded Local Projections• Ensemble learning with 3D convolutional neural networks for connectome-based prediction• Fairness in Online Social Network Timelines: Measurements, Models and Mechanism Design• Investigation of Multimodal Features, Classifiers and Fusion Methods for Emotion Recognition• Linear and Deformable Image Registration with 3D Convolutional Neural Networks• Improving Reinforcement Learning Based Image Captioning with Natural Language Prior• On Bayesian Consistency for Flows Observed Through a Passive Scalar• GANs for Medical Image Analysis• Investigating Crowd Creativity in Online Music Communities• Left Ventricle Segmentation and Volume Estimation on Cardiac MRI using Deep Learning• A Virtual Testbed for Critical Incident Investigation with Autonomous Remote Aerial Vehicle Surveying, Artificial Intelligence, and Decision Support• Arithmetic of (independent) sigma-fields on probability spaces• Efficient Structured Surrogate Loss and Regularization in Structured Prediction• Non-Matrix Tactile Sensors: How Can Be Exploited Their Local Connectivity For Predicting Grasp Stability?• Packing colorings of subcubic outerplanar graphs• Identification of multi-scale hierarchical brain functional networks using deep matrix factorization• Identification of temporal transition of functional states using recurrent neural networks from functional MRI• Brain decoding from functional MRI using long short-term memory recurrent neural networks• Some exit times estimates for Super-Brownian motion and Fleming-Viot Process• Hyperuniformity of generalized random organization models• On prime order automorphisms of generalized quadrangles• Models Matter, So Does Training: An Empirical Study of CNNs for Optical Flow Estimation• Entropic optimal transport is maximum-likelihood deconvolution• Events Beyond ACE: Curated Training for Events• Assessing Bayes factor surfaces using interactive visualization and computer surrogate modeling• Image registration and super resolution from first principles• An improved decoupling inequality for random interlacements• Limit shape of probability measure on tensor product of $B_n$ algebra modules• Non-iterative recomputation of dense layers for performance improvement of DCNN• A study on the use of Boundary Equilibrium GAN for Approximate Frontalization of Unconstrained Faces to aid in Surveillance• DocFace+: ID Document to Selfie Matching• Optimal spatial-dynamic management to minimize the damages caused by aquatic invasive species• A sharp threshold of propagation connectivity for mixed random hypergraphs• Hierarchical Graphical Models for Context-Aware Hybrid Brain-Machine Interfaces• Geo-Text Data and Data-Driven Geospatial Semantics• Learning high-dimensional graphical models with regularized quadratic scoring• Distributed Transient Frequency Control for Power Networks with Stability and Performance Guarantees• Kernel-based collocation methods for Heath-Jarrow-Morton models with Musiela parametrization• Transient frequency control with regional cooperation for power networks• OffsetNet: Deep Learning for Localization in the Lung using Rendered Images• Algebraic Optimization of Binary Spatially Coupled Measurement Matrices for Interval Passing• Omitted and Included Variable Bias in Tests for Disparate Impact• Changes of graph structure of transition probability matrices indicate the slowest kinetic relaxations• HDArray: Parallel Array Interface for Distributed Heterogeneous Devices• On stability of a class of filters for non-linear stochastic systems• Multi-Vehicle Trajectories Generation for Vehicle-to-Vehicle Encounters• Commentary on Quantum-Inspired Information Retrieval• Attention as a Perspective for Learning Tempo-invariant Audio Queries• apk2vec: Semi-supervised multi-view representation learning for profiling Android applications• Multi-UAV Interference Coordination via Joint Trajectory and Power Control• Inferring Political Alignments of Twitter Users: A case study on 2017 Turkish constitutional referendum• Control Variables, Discrete Instruments, and Identification of Structural Functions• Dirichlet problem for supercritical nonlocal operators• Learning Robust Manipulation Skills with Guided Policy Search via Generative Motor Reflexes• Abstractive Dialogue Summarization with Sentence-Gated Modeling Optimized by Dialogue Acts• Completely Uncoupled Algorithms for Network Utility Maximization• Completely Uncoupled User Association Algorithms for State Dependent Wireless Networks• Answering Science Exam Questions Using Query Rewriting with Background Knowledge• Aspects of the topology and combinatorics of Higgs bundle moduli spaces• Neural Networks and Quantifier Conservativity: Does Data Distribution Affect Learnability?• Classifying the Order of Higher Derivative Gaussian Pulses in Terahertz Wireless Communications• Classification of a family of maximum sets of equiangular lines in Euclidean space• Finding the way from ä to a: Sub-character morphological inflection for the SIGMORPHON 2018 Shared Task• Approximation algorithms for the three-machine proportionate mixed shop scheduling• Analysis of Risk Factor Domains in Psychosis Patient Health Records• Car-following behavior of connected vehicles in a mixed traffic flow: modeling and stability analysis• Limit theorems for process-level Betti numbers for sparse, critical, and Poisson regimes• Integral functionals for spectrally positive Levy processes• History of art paintings through the lens of entropy and complexity• Sampled Policy Gradient for Learning to Play the Game Agar.io• Budget Allocation for Power Networks Reliability Improvement: Game-Theoretic Approach• UAV Communications Based on Non-Orthogonal Multiple Access• On the growth of the Möbius function of permutations• Statistical Models with Uncertain Error Parameters• Modelling Latent Travel Behaviour Characteristics with Generative Machine Learning• Accident Forecasting in CCTV Traffic Camera Videos• GANVO: Unsupervised Deep Monocular Visual Odometry and Depth Estimation with Generative Adversarial Networks• Mobility Mode Detection Using WiFi Signals• Relations between convolutions and transforms in operator-valued free probability• Constant factor FPT approximation for capacitated k-median• When Lift-and-Project Cuts are Different• An Asymptotic Comparison of Two Time-homogeneous PAM Models• A Strategic Learning Algorithm for State-based Games• Robust Bayesian Synthetic Likelihood via a Semi-Parametric Approach• Low synchronization GMRES algorithms• Robust Cascade Reconstruction by Steiner Tree Sampling• Development of deep learning algorithms to categorize free-text notes pertaining to diabetes: convolution neural networks achieve higher accuracy than support vector machines• Linear Independent Component Analysis over Finite Fields: Algorithms and Bounds• Sequence-Subset Distance and Coding for Error Control in DNA Data Storage• Aesthetic-based Clothing Recommendation• Segmenting Unknown 3D Objects from Real Depth Images using Mask R-CNN Trained on Synthetic Point Clouds• Throughput Optimized Non-Contiguous Wideband Spectrum Sensing via Online Learning and Sub-Nyquist Sampling• Real-Time, Highly Accurate Robotic Grasp Detection using Fully Convolutional Neural Networks with High-Resolution Images• Multiple Abnormality Detection for Automatic Medical Image Diagnosis Using Bifurcated Convolutional Neural Network• Inspecting Interactions: Online News Media Synergies in Social Media• Pervasive Cloud Controller for Geotemporal Inputs• A Generic Multi-modal Dynamic Gesture Recognition System using Machine Learning• A Cloud Controller for Performance-Based Pricing• Performance-Based Pricing in Multi-Core Geo-Distributed Cloud Computing• Two faces of greedy leaf removal procedure on graphs• Calculation of extended gcd by normalization• Towards Good Practices for Multi-modal Fusion in Large-scale Video Classification• Geometry-Consistent Adversarial Networks for One-Sided Unsupervised Domain Mapping• Energy Efficient Cloud Control and Pricing in Geographically Distributed Data Centers• Exploiting Errors for Efficiency: A Survey from Circuits to Algorithms• In Defense of the Classification Loss for Person Re-Identification• Inspiration Learning through Preferences• Road Detection Technique Using Filters with Application to Autonomous Driving System• An FPGA-Accelerated Design for Deep Learning Pedestrian Detection in Self-Driving Vehicles• Multi-Label Image Classification via Knowledge Distillation from Weakly-Supervised Detection• Semi-Supervised Multi-Task Word Embeddings• Comparison of Deep Learning and the Classical Machine Learning Algorithm for the Malware Detection• Semantic Interoperability Middleware Architecture for Heterogeneous Environmental Data Sources• Existence and Cyclical monotonicity for weak transport costs• Primal-dual accelerated gradient descent with line search for convex and nonconvex optimization problems• Systems of bounded rational agents with information-theoretic constraints• Trends in the Diffusion of Misinformation on Social Media• Stochastic differential equations for infinite particle systems of jump type with long range interactions• A Storm in an IoT Cup: The Emergence of Cyber-Physical Social Machines• From Integrable to Chaotic Systems: Universal Local Statistics of Lyapunov exponents• MeshCNN: A Network with an Edge• Target Defense Against Link-Prediction-Based Attacks via Evolutionary Perturbations• Curriculum-Based Neighborhood Sampling For Sequence Prediction• Analysis of Dynamic Memory Bandwidth Regulation in Multi-core Real-Time Systems
Like this:
Like Loading…
Related