Out-of-Distribution Detection Using an Ensemble of Self Supervised Leave-out Classifiers

Improving Question Answering by Commonsense-Based Pre-Training
Although neural network approaches achieve remarkable success on a variety of NLP tasks, many of them struggle to answer questions that require commonsense knowledge. We believe the main reason is the lack of commonsense connections between concepts. To remedy this, we provide a simple and effective method that leverages external commonsense knowledge base such as ConceptNet. We pre-train direct and indirect relational functions between concepts, and show that these pre-trained functions could be easily added to existing neural network models. Results show that incorporating commonsense-based function improves the state-of-the-art on two question answering tasks that require commonsense reasoning. Further analysis shows that our system discovers and leverages useful evidences from an external commonsense knowledge base, which is missing in existing neural network models and help derive the correct answer.
Topological Brain Network Distances
Existing brain network distances are often based on matrix norms. The element-wise differences in the existing matrix norms may fail to capture underlying topological differences. Further, matrix norms are sensitive to outliers. A major disadvantage to element-wise distance calculations is that it could be severely affected even by a small number of extreme edge weights. Thus it is necessary to develop network distances that recognize topology. In this paper, we provide a survey of bottleneck, Gromov-Hausdorff (GH) and Kolmogorov-Smirnov (KS) distances that are adapted for brain networks, and compare them against matrix-norm based network distances. Bottleneck and GH-distances are often used in persistent homology. However, they were rarely utilized to measure similarity between brain networks. KS-distance is recently introduced to measure the similarity between networks across different filtration values. The performance analysis was conducted using the random network simulations with the ground truths. Using a twin imaging study, which provides biological ground truth, we demonstrate that the KS distance has the ability to determine heritability.
A Correlation Maximization Approach for Cross Domain Co-Embeddings
Although modern recommendation systems can exploit the structure in users’ item feedback, most are powerless in the face of new users who provide no structure for them to exploit. In this paper we introduce ImplicitCE, an algorithm for recommending items to new users during their sign-up flow. ImplicitCE works by transforming users’ implicit feedback towards auxiliary domain items into an embedding in the target domain item embedding space. ImplicitCE learns these embedding spaces and transformation function in an end-to-end fashion and can co-embed users and items with any differentiable similarity function. To train ImplicitCE we explore methods for maximizing the correlations between model predictions and users’ affinities and introduce Sample Correlation Update, a novel and extremely simple training strategy. Finally, we show that ImplicitCE trained with Sample Correlation Update outperforms a variety of state of the art algorithms and loss functions on both a large scale Twitter dataset and the DBLP dataset.
Bayesian Patchworks: An Approach to Case-Based Reasoning
Doctors often rely on their past experience in order to diagnose patients. For a doctor with enough experience, almost every patient would have similarities to key cases seen in the past, and each new patient could be viewed as a mixture of these key past cases. Because doctors often tend to reason this way, an efficient computationally aided diagnostic tool that thinks in the same way might be helpful in locating key past cases of interest that could assist with diagnosis. This article develops a novel mathematical model to mimic the type of logical thinking that physicians use when considering past cases. The proposed model can also provide physicians with explanations that would be similar to the way they would naturally reason about cases. The proposed method is designed to yield predictive accuracy, computational efficiency, and insight into medical data; the key element is the insight into medical data, in some sense we are automating a complicated process that physicians might perform manually. We finally implemented the result of this work on two publicly available healthcare datasets, for heart disease prediction and breast cancer prediction.
VPE: Variational Policy Embedding for Transfer Reinforcement Learning
Reinforcement Learning methods are capable of solving complex problems, but resulting policies might perform poorly in environments that are even slightly different. In robotics especially, training and deployment conditions often vary and data collection is expensive, making retraining undesirable. Simulation training allows for feasible training times, but on the other hand suffers from a reality-gap when applied in real-world settings. This raises the need of efficient adaptation of policies acting in new environments. We consider this as a problem of transferring knowledge within a family of similar Markov decision processes. For this purpose we assume that Q-functions are generated by some low-dimensional latent variable. Given such a Q-function, we can find a master policy that can adapt given different values of this latent variable. Our method learns both the generative mapping and an approximate posterior of the latent variables, enabling identification of policies for new tasks by searching only in the latent space, rather than the space of all policies. The low-dimensional space, and master policy found by our method enables policies to quickly adapt to new environments. We demonstrate the method on both a pendulum swing-up task in simulation, and for simulation-to-real transfer on a pushing task.
Deep Learning Towards Mobile Applications
Recent years have witnessed an explosive growth of mobile devices. Mobile devices are permeating every aspect of our daily lives. With the increasing usage of mobile devices and intelligent applications, there is a soaring demand for mobile applications with machine learning services. Inspired by the tremendous success achieved by deep learning in many machine learning tasks, it becomes a natural trend to push deep learning towards mobile applications. However, there exist many challenges to realize deep learning in mobile applications, including the contradiction between the miniature nature of mobile devices and the resource requirement of deep neural networks, the privacy and security concerns about individuals’ data, and so on. To resolve these challenges, during the past few years, great leaps have been made in this area. In this paper, we provide an overview of the current challenges and representative achievements about pushing deep learning on mobile devices from three aspects: training with mobile data, efficient inference on mobile devices, and applications of mobile deep learning. The former two aspects cover the primary tasks of deep learning. Then, we go through our two recent applications that apply the data collected by mobile devices to inferring mood disturbance and user identification. Finally, we conclude this paper with the discussion of the future of this area.
Learning Named Entity Tagger using Domain-Specific Dictionary
Recent advances in deep neural models allow us to build reliable named entity recognition (NER) systems without handcrafting features. However, such methods require large amounts of manually-labeled training data. There have been efforts on replacing human annotations with distant supervision (in conjunction with external dictionaries), but the generated noisy labels pose significant challenges on learning effective neural models. Here we propose two neural models to suit noisy distant supervision from the dictionary. First, under the traditional sequence labeling framework, we propose a revised fuzzy CRF layer to handle tokens with multiple possible labels. After identifying the nature of noisy labels in distant supervision, we go beyond the traditional framework and propose a novel, more effective neural model AutoNER with a new Tie or Break scheme. In addition, we discuss how to refine distant supervision for better NER performance. Extensive experiments on three benchmark datasets demonstrate that AutoNER achieves the best performance when only using dictionaries with no additional human effort, and delivers competitive results with state-of-the-art supervised benchmarks.
Threshold factor models for high-dimensional time series
We consider a threshold factor model for high-dimensional time series in which the dynamics of the time series is assumed to switch between different regimes according to the value of a threshold variable. This is an extension of threshold modeling to a high-dimensional time series setting under a factor structure. Specifically, within each threshold regime, the time series is assumed to follow a factor model. The factor loading matrices are different in different regimes. The model can also be viewed as an extension of the traditional factor models for time series. It provides flexibility in dealing with situations that the underlying states may be changing over time, as often observed in economic time series and other applications. We develop the procedures for the estimation of the loading spaces, the number of factors and the threshold value, as well as the identification of the threshold variable. The theoretical properties are investigated. Simulated and real data examples are presented to illustrate the performance of the proposed method.
Energy-efficient Decision Fusion for Distributed Detection in Wireless Sensor Networks

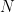


An Efficient ADMM-Based Algorithm to Nonconvex Penalized Support Vector Machines

New models for symbolic data analysis
Symbolic data analysis (SDA) is an emerging area of statistics based on aggregating individual level data into group-based distributional summaries (symbols), and then developing statistical methods to analyse them. It is ideal for analysing large and complex datasets, and has immense potential to become a standard inferential technique in the near future. However, existing SDA techniques are either non-inferential, do not easily permit meaningful statistical models, are unable to distinguish between competing models, and are based on simplifying assumptions that are known to be false. Further, the procedure for constructing symbols from the underlying data is erroneously not considered relevant to the resulting statistical analysis. In this paper we introduce a new general method for constructing likelihood functions for symbolic data based on a desired probability model for the underlying classical data, while only observing the distributional summaries. This approach resolves many of the conceptual and practical issues with current SDA methods, opens the door for new classes of symbol design and construction, in addition to developing SDA as a viable tool to enable and improve upon classical data analyses, particularly for very large and complex datasets. This work creates a new direction for SDA research, which we illustrate through several real and simulated data analyses.
Topic Memory Networks for Short Text Classification
Many classification models work poorly on short texts due to data sparsity. To address this issue, we propose topic memory networks for short text classification with a novel topic memory mechanism to encode latent topic representations indicative of class labels. Different from most prior work that focuses on extending features with external knowledge or pre-trained topics, our model jointly explores topic inference and text classification with memory networks in an end-to-end manner. Experimental results on four benchmark datasets show that our model outperforms state-of-the-art models on short text classification, meanwhile generates coherent topics.
Deep Interest Evolution Network for Click-Through Rate Prediction
Click-through rate~(CTR) prediction, whose goal is to estimate the probability of the user clicks, has become one of the core tasks in advertising systems. For CTR prediction model, it is necessary to capture the latent user interest behind the user behavior data. Besides, considering the changing of the external environment and the internal cognition, user interest evolves over time dynamically. There are several CTR prediction methods for interest modeling, while most of them regard the representation of behavior as the interest directly, and lack specially modeling for latent interest behind the concrete behavior. Moreover, few work consider the changing trend of interest. In this paper, we propose a novel model, named Deep Interest Evolution Network~(DIEN), for CTR prediction. Specifically, we design interest extractor layer to capture temporal interests from history behavior sequence. At this layer, we introduce an auxiliary loss to supervise interest extracting at each step. As user interests are diverse, especially in the e-commerce system, we propose interest evolving layer to capture interest evolving process that is relative to the target item. At interest evolving layer, attention mechanism is embedded into the sequential structure novelly, and the effects of relative interests are strengthened during interest evolution. In the experiments on both public and industrial datasets, DIEN significantly outperforms the state-of-the-art solutions. Notably, DIEN has been deployed in the display advertisement system of Taobao, and obtained 20.7\% improvement on CTR.
Learning Scripts as Hidden Markov Models
Scripts have been proposed to model the stereotypical event sequences found in narratives. They can be applied to make a variety of inferences including filling gaps in the narratives and resolving ambiguous references. This paper proposes the first formal framework for scripts based on Hidden Markov Models (HMMs). Our framework supports robust inference and learning algorithms, which are lacking in previous clustering models. We develop an algorithm for structure and parameter learning based on Expectation Maximization and evaluate it on a number of natural datasets. The results show that our algorithm is superior to several informed baselines for predicting missing events in partial observation sequences.
Massively Parallel Dynamic Programming on Trees

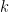
A Joint Model of Conversational Discourse and Latent Topics on Microblogs
Conventional topic models are ineffective for topic extraction from microblog messages, because the data sparseness exhibited in short messages lacking structure and contexts results in poor message-level word co-occurrence patterns. To address this issue, we organize microblog messages as conversation trees based on their reposting and replying relations, and propose an unsupervised model that jointly learns word distributions to represent: 1) different roles of conversational discourse, 2) various latent topics in reflecting content information. By explicitly distinguishing the probabilities of messages with varying discourse roles in containing topical words, our model is able to discover clusters of discourse words that are indicative of topical content. In an automatic evaluation on large-scale microblog corpora, our joint model yields topics with better coherence scores than competitive topic models from previous studies. Qualitative analysis on model outputs indicates that our model induces meaningful representations for both discourse and topics. We further present an empirical study on microblog summarization based on the outputs of our joint model. The results show that the jointly modeled discourse and topic representations can effectively indicate summary-worthy content in microblog conversations.
Factorized Q-Learning for Large-Scale Multi-Agent Systems
Deep Q-learning has achieved a significant success in single-agent decision making tasks. However, it is challenging to extend Q-learning to large-scale multi-agent scenarios, due to the explosion of action space resulting from the complex dynamics between the environment and the agents. In this paper, we propose to make the computation of multi-agent Q-learning tractable by treating the Q-function (w.r.t. state and joint-action) as a high-order high-dimensional tensor and then approximate it with factorized pairwise interactions. Furthermore, we utilize a composite deep neural network architecture for computing the factorized Q-function, share the model parameters among all the agents within the same group, and estimate the agents’ optimal joint actions through a coordinate descent type algorithm. All these simplifications greatly reduce the model complexity and accelerate the learning process. Extensive experiments on two different multi-agent problems have demonstrated the performance gain of our proposed approach in comparison with strong baselines, particularly when there are a large number of agents.
Visualization of High-dimensional Scalar Functions Using Principal Parameterizations

Integration of Relational and Graph Databases Functionally
A significant category of NoSQL approaches is known as graph databases. They are usually represented by one property graph. We introduce a functional approach to modelling relations and property graphs. Single-valued and multivalued functions will be sufficient in this case. Then, a typed {\lambda}-calculus, i.e., the language of lambda terms, will be used as a data manipulation language. Some integration options at the query language level are discussed.
Learning rate adaptation for differentially private stochastic gradient descent
Differentially private learning has recently emerged as the leading approach for privacy-preserving machine learning. Differential privacy can complicate learning procedures because each access to the data needs to be carefully designed and carries a privacy cost. For example, standard parameter tuning with a validation set cannot be easily applied. In this paper, we propose a differentially private algorithm for the adaptation of the learning rate for differentially private stochastic gradient descent (SGD) that avoids the need for validation set use. The idea for the adaptiveness comes from the technique of extrapolation in classical numerical analysis: to get an estimate for the error against the gradient flow which underlies SGD, we compare the result obtained by one full step and two half-steps. We prove the privacy of the method using the moments accountant mechanism. This allows us to compute tight privacy bounds. Empirically we show that our method is competitive with manually tuned commonly used optimisation methods for training deep neural networks and differentially private variational inference.
Response Characterization for Auditing Cell Dynamics in Long Short-term Memory Networks
In this paper, we introduce a novel method to interpret recurrent neural networks (RNNs), particularly long short-term memory networks (LSTMs) at the cellular level. We propose a systematic pipeline for interpreting individual hidden state dynamics within the network using response characterization methods. The ranked contribution of individual cells to the network’s output is computed by analyzing a set of interpretable metrics of their decoupled step and sinusoidal responses. As a result, our method is able to uniquely identify neurons with insightful dynamics, quantify relationships between dynamical properties and test accuracy through ablation analysis, and interpret the impact of network capacity on a network’s dynamical distribution. Finally, we demonstrate generalizability and scalability of our method by evaluating a series of different benchmark sequential datasets.
Abstraction Learning
There has been a gap between artificial intelligence and human intelligence. In this paper, we identify three key elements forming human intelligence, and suggest that abstraction learning combines these elements and is thus a way to bridge the gap. Prior researches in artificial intelligence either specify abstraction by human experts, or take abstraction as a qualitative explanation for the model. This paper aims to learn abstraction directly. We tackle three main challenges: representation, objective function, and learning algorithm. Specifically, we propose a partition structure that contains pre-allocated abstraction neurons; we formulate abstraction learning as a constrained optimization problem, which integrates abstraction properties; we develop a network evolution algorithm to solve this problem. This complete framework is named ONE (Optimization via Network Evolution). In our experiments on MNIST, ONE shows elementary human-like intelligence, including low energy consumption, knowledge sharing, and lifelong learning.
Reducing Uncertainty of Schema Matching via Crowdsourcing with Accuracy Rates
Schema matching is a central challenge for data integration systems. Inspired by the popularity and the success of crowdsourcing platforms, we explore the use of crowdsourcing to reduce the uncertainty of schema matching. Since crowdsourcing platforms are most effective for simple questions, we assume that each Correspondence Correctness Question (CCQ) asks the crowd to decide whether a given correspondence should exist in the correct matching. Furthermore, members of a crowd may sometimes return incorrect answers with different probabilities. Accuracy rates of individual crowd workers are probabilities of returning correct answers which can be attributes of CCQs as well as evaluations of individual workers. We prove that uncertainty reduction equals to entropy of answers minus entropy of crowds and show how to obtain lower and upper bounds for it. We propose frameworks and efficient algorithms to dynamically manage the CCQs to maximize the uncertainty reduction within a limited budget of questions. We develop two novel approaches, namely Single CCQ’ and Multiple CCQ’, which adaptively select, publish and manage questions. We verify the value of our solutions with simulation and real implementation.
Training and Prediction Data Discrepancies: Challenges of Text Classification with Noisy, Historical Data
Industry datasets used for text classification are rarely created for that purpose. In most cases, the data and target predictions are a by-product of accumulated historical data, typically fraught with noise, present in both the text-based document, as well as in the targeted labels. In this work, we address the question of how well performance metrics computed on noisy, historical data reflect the performance on the intended future machine learning model input. The results demonstrate the utility of dirty training datasets used to build prediction models for cleaner (and different) prediction inputs.
• The 6-element case of S-Frankl conjecture (I)• Nash Equilibria in the Response Strategy of Correlated Games• Robust Energy Efficient Beamforming in MISOME-SWIPT Systems With Proportional Secrecy Rate• Dual-label Deep LSTM Dereverberation For Speaker Verification• A multifeature fusion approach for power system transient stability assessment using PMU data• Quantitative Reductions and Vertex-Ranked Infinite Games• Constrained Existence Problem for Weak Subgame Perfect Equilibria with $ω$-Regular Boolean Objectives• Decomposition of Augmented Cubes into Regular Connected Pancyclic Subgraphs• Minimum Eccentric Connectivity Index for Graphs with Fixed Order and Fixed Number of Pending Vertices• A comparative stochastic and deterministic study of a class of epidemic dynamic models for malaria: exploring the impacts of noise on eradication and persistence of disease• Geometric Surface-Based Tracking Control of a Quadrotor UAV under Actuator Constraints• Optimal Stochastic Vehicle Path Planning Using Covariance Steering• The Horn Problem for Real Symmetric and Quaternionic Self-Dual Matrices• Qiskit Backend Specifications for OpenQASM and OpenPulse Experiments• Wasserstein Gradients for the Temporal Evolution of Probability Distributions• Energy Disaggregation via Deep Temporal Dictionary Learning• Convolutional Graph Auto-encoder: A Deep Generative Neural Architecture for Probabilistic Spatio-temporal Solar Irradiance Forecasting• Annotating shadows, highlights and faces: the contribution of a ‘human in the loop’ for digital art history• A log-Sobolev inequality for the multislice, with applications• Comparison of signal detectors for time domain radio SETI• Pursuit of Low-Rank Models of Time-Varying Matrices Robust to Sparse and Measurement Noise• Unicyclic Strong Permutations• Partial Recovery of Erdős-Rényi Graph Alignment via $k$-Core Alignment• Quantile Regression for Qualifying Match of GEFCom2017 Probabilistic Load Forecasting• Drying and percolation in spatially correlated porous media• Collapsed Variational Inference for Nonparametric Bayesian Group Factor Analysis• Malliavin Calculus and Density for Singular Stochastic Partial Differential Equations• A Guide to Solar Power Forecasting using ARMA Models• Using Image Fairness Representations in Diversity-Based Re-ranking for Recommendations• Conflict-free connection number of random graphs• Benefits of Positioning-Aided Communication Technology in High-Frequency Industrial IoT• Characteristic-Sorted Portfolios: Estimation and Inference• Unconstraining graph-constrained group testing• On Hydrodynamic Limits of Young Diagrams• Identifying the effect of public holidays on daily demand for gas• Hamiltonian Berge cycles in random hypergraphs• Non-Asymptotic Inference in Instrumental Variables Estimation• PedX: Benchmark Dataset for Metric 3D Pose Estimation of Pedestrians in Complex Urban Intersections• Towards Practical Software Stack Decoding of Polar Codes• Characterizations of Tilt-Stable Minimizers in Second-Order Cone Programming• Optimal Strategies for Disjunctive Sensing and Control• URBAN-i: From urban scenes to mapping slums, transport modes, and pedestrians in cities using deep learning and computer vision• On the Capacity Region for Secure Index Coding• Social cognitive optimization with tent map for combined heat and power economic dispatch• New Lower Bounds for the Number of Pseudoline Arrangements• RFI subspace smearing and projection for array radio telescopes• Approximate abstractions of control systems with an application to aggregation• Improving Adversarial Discriminative Domain Adaptation• ClusterGAN : Latent Space Clustering in Generative Adversarial Networks• Network Coded Handover in IEEE 802.11• Path prediction of aggregated $α$-stable moving averages using semi-norm representations• Detecting Gang-Involved Escalation on Social Media Using Context• Unsupervised Cross-lingual Transfer of Word Embedding Spaces• Critical Percolation on Random Networks with Prescribed Degrees• Model Risk Measurement under Wasserstein Distance• A Profile Likelihood Approach to Semiparametric Estimation with Nonignorable Nonresponse• Tuning metaheuristics by sequential optimization of regression models• Learning Root Source with Marked Multivariate Hawkes Processes• Evaluation of Preference of Multimedia Content using Deep Neural Networks for Electroencephalography• Resource-driven Substructural Defeasible Logic• Uplink Cooperative NOMA for Cellular-Connected UAV• Neural Animation and Reenactment of Human Actor Videos• Multiple list colouring triangle-free planar graphs• Comparing Computing Platforms for Deep Learning on a Humanoid Robot• Temporal-Spatial Mapping for Action Recognition• Strategies for quantum races• Planar Cooperative Extremum Seeking with Guaranteed Convergence Using A Three-Robot Formation• Central limit theorem near the critical temperature for the overlap in the 2-spin spherical SK model• Unbiasing Semantic Segmentation For Robot Perception using Synthetic Data Feature Transfer• CNN-Based Signal Detection for Banded Linear Systems• Evaluating Multimodal Representations on Sentence Similarity: vSTS, Visual Semantic Textual Similarity Dataset• CAPRL: Signal Recovery from Compressive Affine Phase Retrieval via Lifting• Sparse Attentive Backtracking: Temporal CreditAssignment Through Reminding• Bio-LSTM: A Biomechanically Inspired Recurrent Neural Network for 3D Pedestrian Pose and Gait Prediction• Robust Resource Allocation for UAV Systems with UAV Jittering and User Location Uncertainty• Answering Visual What-If Questions: From Actions to Predicted Scene Descriptions• The continuous Anderson hamiltonian in $d\le 3$• Deep Asymmetric Networks with a Set of Node-wise Variant Activation Functions• The Maximum Number of Three Term Arithmetic Progressions, and Triangles in Cayley Graphs• Consensus of a class of nonlinear fractional-order multi-agent systems via dynamic output feedback• How much should you ask? On the question structure in QA systems• Forecasting Based on Surveillance Data• Does it care what you asked? Understanding Importance of Verbs in Deep Learning QA System• Bayesian inference for a principal stratum estimand to assess the treatment effect in a subgroup characterized by post-randomization events• Stochastic Multipath Model for the In-Room Radio Channel based on Room Electromagnetics• Joint Spatial Division and Diversity for Massive MIMO Systems• The reproducing kernel Hilbert space approach in nonparametric regression problems with correlated observations• Non-blind Image Restoration Based on Convolutional Neural Network• Threshold-Based Heuristics for Trust Inference in a Social Network• On the aberrations of mixed level Orthogonal Arrays with removed runs• Asymptotic joint spectra of Cartesian powers of strongly regular graphs and bivariate Charlier-Hermite polynomials• A note on reducing the computation time for minimum distance and equivalence check of binary linear codes• 3D Human Body Reconstruction from a Single Image via Volumetric Regression• A few properties of sample variance• Solving Non-identifiable Latent Feature Models• Probabilistic approach to limited-data computed tomography reconstruction• Long-Term Occupancy Grid Prediction Using Recurrent Neural Networks• Normalization in Training Deep Convolutional Neural Networks for 2D Bio-medical Semantic Segmentation• Compressive Massive Random Access for Massive Machine-Type Communications (mMTC)• Convolutional Neural Networks for the segmentation of microcalcification in Mammography Imaging• A new exact algorithm for solving single machine scheduling problems with learning effects and deteriorating jobs• Cut distance identifying graphon parameters over weak* limits• The hiring problem with rank-based strategies• A fast Fourier transform based direct solver for the Helmholtz problem• Predicting Blood Glucose with an LSTM and Bi-LSTM Based Deep Neural Network• Delayed and rushed motions through time change• The Undirected Two Disjoint Shortest Paths Problem• Real-time force control of an SEA-based body weight support unit with the 2-DOF control structure• Unsupervised Domain Adaptation Based on Source-guided Discrepancy• Visualizing Convolutional Neural Networks to Improve Decision Support for Skin Lesion Classification• EXS: Explainable Search Using Local Model Agnostic Interpretability• Studying the History of the Arabic Language: Language Technology and a Large-Scale Historical Corpus• LOS MIMO Design based on Multiple Optimum Antenna Separations• Mitigating Confirmation Bias on Twitter by Recommending Opposing Views• Regression Discontinuity Designs Using Covariates• Spatial Item Factor Analysis With Application to Mapping Food Insecurity• Review of several false positive error rate estimates for latent fingerprint examination proposed based on the 2014 Miami Dade Police Department study• Detecting Intentions of Vulnerable Road Users Based on Collective Intelligence• A Two-Stage Method for Skin Lesion Analysis• Computing the resolvent of the sum of operators with application to best approximation problems• Constructive regularization of the random matrix norm• SAI, a Sensible Artificial Intelligence that plays Go• Localization of Brain Activity from EEG/MEG Using MV-PURE Framework• A Short Note on Integral Transformations and Conversion Formulas for Sequence Generating Functions• Permutation inference methods for multivariate meta-analysis• MIMO Mutli-Cell Processing: Optimal Precoding and Power Allocation• Structural Analysis and Control of a Model of Two-site Electricity and Heat Supply• Multilingual Cross-domain Perspectives on Online Hate Speech• Hubless keypoint-based 3D deformable groupwise registration• Non-convex image reconstruction via Expectation Propagation• Atomic positions independent descriptor for machine learning of material properties• Deep Inferential Spatial-Temporal Network for Forecasting Air Pollution Concentrations• More Cases Where the Kruskal-Katona Bound is Tight• Cusp Universality for Random Matrices I: Local Law and the Complex Hermitian Case• Endowing Robots with Longer-term Autonomy by Recovering from External Disturbances in Manipulation through Grounded Anomaly Classification and Recovery Policies• On The Alignment Problem In Multi-Head Attention-Based Neural Machine Translation• Efficient Statistics, in High Dimensions, from Truncated Samples• The $ε$-error Capacity of Symmetric PIR with Byzantine Adversaries• DLR equations and rigidity for the Sine-beta process• Assessing Composition in Sentence Vector Representations• Efficient Road Lane Marking Detection with Deep Learning• Convex functions on graphs: Sum of the eigenvalues• Evaluating Semantic Rationality of a Sentence: A Sememe-Word-Matching Neural Network based on HowNet• Failure Rate Properties of Parallel Systems• Shift-Inequivalent Decimations of the Sidelnikov-Lempel-Cohn-Eastman Sequences• On the approximation of Lévy driven Volterra processes and their integrals• Bootstrap Methods in Econometrics• T-statistic for Autoregressive process• Can LSTM Learn to Capture Agreement? The Case of Basque• Stochastic growth rates for populations in random environments with rare migration• Stability of fixed life histories to perturbation by rare diapause• p-Bits for Probabilistic Spin Logic• Hyperbolic normal stochastic volatility model• Bit-Metric Decoding of Non-Binary LDPC Codes with Probabilistic Amplitude Shaping• Small-Gain-Based Boundary Feedback Design for Global Exponential Stabilization of 1-D Semilinear Parabolic PDEs• Solving Imperfect-Information Games via Discounted Regret Minimization• Statistical post-processing of ensemble forecasts of temperature in Santiago de Chile• AWE: Asymmetric Word Embedding for Textual Entailment• Accurate Tracking of Aggressive Quadrotor Trajectories using Incremental Nonlinear Dynamic Inversion and Differential Flatness• Maximally Consistent Sampling and the Jaccard Index of Probability Distributions• Observation of many-body localization in a one-dimensional system with single-particle mobility edge• Neural-Augmented Static Analysis of Android Communication• SNS: A Solution-based Nonlinear Subspace method for time-dependent nonlinear model order reduction
Like this:
Like Loading…
Related