Trimmed Ensemble Kalman Filter for Nonlinear and Non-Gaussian Data Assimilation Problems
We study the ensemble Kalman filter (EnKF) algorithm for sequential data assimilation in a general situation, that is, for nonlinear forecast and measurement models with non-additive and non-Gaussian noises. Such applications traditionally force us to choose between inaccurate Gaussian assumptions that permit efficient algorithms (e.g., EnKF), or more accurate direct sampling methods which scale poorly with dimension (e.g., particle filters, or PF). We introduce a trimmed ensemble Kalman filter (TEnKF) which can interpolate between the limiting distributions of the EnKF and PF to facilitate adaptive control over both accuracy and efficiency. This is achieved by introducing a trimming function that removes non-Gaussian outliers that introduce errors in the correlation between the model and observed forecast, which otherwise prevent the EnKF from proposing accurate forecast updates. We show for specific trimming functions that the TEnKF exactly reproduces the limiting distributions of the EnKF and PF. We also develop an adaptive implementation which provides control of the effective sample size and allows the filter to overcome periods of increased model nonlinearity. This algorithm allow us to demonstrate substantial improvements over the traditional EnKF in convergence and robustness for the nonlinear Lorenz-63 and Lorenz-96 models.
Decision-Making with Belief Functions: a Review
Approaches to decision-making under uncertainty in the belief function framework are reviewed. Most methods are shown to blend criteria for decision under ignorance with the maximum expected utility principle of Bayesian decision theory. A distinction is made between methods that construct a complete preference relation among acts, and those that allow incomparability of some acts due to lack of information. Methods developed in the imprecise probability framework are applicable in the Dempster-Shafer context and are also reviewed. Shafer’s constructive decision theory, which substitutes the notion of goal for that of utility, is described and contrasted with other approaches. The paper ends by pointing out the need to carry out deeper investigation of fundamental issues related to decision-making with belief functions and to assess the descriptive, normative and prescriptive values of the different approaches.
SWAG: A Large-Scale Adversarial Dataset for Grounded Commonsense Inference
Given a partial description like ‘she opened the hood of the car,’ humans can reason about the situation and anticipate what might come next (‘then, she examined the engine’). In this paper, we introduce the task of grounded commonsense inference, unifying natural language inference and commonsense reasoning. We present SWAG, a new dataset with 113k multiple choice questions about a rich spectrum of grounded situations. To address the recurring challenges of the annotation artifacts and human biases found in many existing datasets, we propose Adversarial Filtering (AF), a novel procedure that constructs a de-biased dataset by iteratively training an ensemble of stylistic classifiers, and using them to filter the data. To account for the aggressive adversarial filtering, we use state-of-the-art language models to massively oversample a diverse set of potential counterfactuals. Empirical results demonstrate that while humans can solve the resulting inference problems with high accuracy (88%), various competitive models struggle on our task. We provide comprehensive analysis that indicates significant opportunities for future research.
Propensity Score Weighting for Causal Inference with Multi-valued Treatments
This article proposes a unified framework, the balancing weights, for estimating causal effects with multi-valued treatments using propensity score weighting. These weights incorporate the generalized propensity score to balance the weighted covariate distribution of each treatment group, all weighted toward a common pre-specified target population. The class of balancing weights include several existing approaches such as inverse probability weights and trimming weights as special cases. Within this framework, we propose a class of target estimands based on linear contrasts and their corresponding nonparametric weighting estimators. We further propose the generalized overlap weights, constructed as the product of the inverse probability weights and the harmonic mean of the generalized propensity scores, to focus on the target population with the most overlap in covariates. These weights are bounded and thus bypass the problem of extreme propensities. We show that the generalized overlap weights minimize the total asymptotic variance of the nonparametric estimators for the pairwise contrasts within the class of balancing weights. We also develop two new balance check criteria and a sandwich variance estimator for estimating the causal effects with generalized overlap weights. We illustrate these methods by simulations and apply them to study the racial disparities in medical expenditure.
Neural Architecture Search: A Survey
Deep Learning has enabled remarkable progress over the last years on a variety of tasks, such as image recognition, speech recognition, and machine translation. One crucial aspect for this progress are novel neural architectures. Currently employed architectures have mostly been developed manually by human experts, which is a time-consuming and error-prone process. Because of this, there is growing interest in automated neural architecture search methods. We provide an overview of existing work in this field of research and categorize them according to three dimensions: search space, search strategy, and performance estimation strategy.
On the Decision Boundary of Deep Neural Networks
Metric Learning for Novelty and Anomaly Detection
When neural networks process images which do not resemble the distribution seen during training, so called out-of-distribution images, they often make wrong predictions, and do so too confidently. The capability to detect out-of-distribution images is therefore crucial for many real-world applications. We divide out-of-distribution detection between novelty detection —images of classes which are not in the training set but are related to those—, and anomaly detection —images with classes which are unrelated to the training set. By related we mean they contain the same type of objects, like digits in MNIST and SVHN. Most existing work has focused on anomaly detection, and has addressed this problem considering networks trained with the cross-entropy loss. Differently from them, we propose to use metric learning which does not have the drawback of the softmax layer (inherent to cross-entropy methods), which forces the network to divide its prediction power over the learned classes. We perform extensive experiments and evaluate both novelty and anomaly detection, even in a relevant application such as traffic sign recognition, obtaining comparable or better results than previous works.
A Survey on Influence Maximization in a Social Network
Given a social network with diffusion probabilities as edge weights and an integer k, which k nodes should be chosen for initial injection of information to maximize influence in the network? This problem is known as Target Set Selection in a social network (TSS Problem) and more popularly, Social Influence Maximization Problem (SIM Problem). This is an active area of research in computational social network analysis domain since one and half decades or so. Due to its practical importance in various domains, such as viral marketing, target advertisement, personalized recommendation, the problem has been studied in different variants, and different solution methodologies have been proposed over the years. Hence, there is a need for an organized and comprehensive review on this topic. This paper presents a survey on the progress in and around TSS Problem. At last, it discusses current research trends and future research directions as well.
Combining time-series and textual data for taxi demand prediction in event areas: a deep learning approach
Accurate time-series forecasting is vital for numerous areas of application such as transportation, energy, finance, economics, etc. However, while modern techniques are able to explore large sets of temporal data to build forecasting models, they typically neglect valuable information that is often available under the form of unstructured text. Although this data is in a radically different format, it often contains contextual explanations for many of the patterns that are observed in the temporal data. In this paper, we propose two deep learning architectures that leverage word embeddings, convolutional layers and attention mechanisms for combining text information with time-series data. We apply these approaches for the problem of taxi demand forecasting in event areas. Using publicly available taxi data from New York, we empirically show that by fusing these two complementary cross-modal sources of information, the proposed models are able to significantly reduce the error in the forecasts.
Distributionally Adversarial Attack




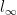



Switching Regression Models and Causal Inference in the Presence of Latent Variables
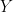

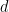
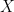
LARNN: Linear Attention Recurrent Neural Network
BlockQNN: Efficient Block-wise Neural Network Architecture Generation
Convolutional neural networks have gained a remarkable success in computer vision. However, most usable network architectures are hand-crafted and usually require expertise and elaborate design. In this paper, we provide a block-wise network generation pipeline called BlockQNN which automatically builds high-performance networks using the Q-Learning paradigm with epsilon-greedy exploration strategy. The optimal network block is constructed by the learning agent which is trained to choose component layers sequentially. We stack the block to construct the whole auto-generated network. To accelerate the generation process, we also propose a distributed asynchronous framework and an early stop strategy. The block-wise generation brings unique advantages: (1) it yields state-of-the-art results in comparison to the hand-crafted networks on image classification, particularly, the best network generated by BlockQNN achieves 2.35% top-1 error rate on CIFAR-10. (2) it offers tremendous reduction of the search space in designing networks, spending only 3 days with 32 GPUs. A faster version can yield a comparable result with only 1 GPU in 20 hours. (3) it has strong generalizability in that the network built on CIFAR also performs well on the larger-scale dataset. The best network achieves very competitive accuracy of 82.0% top-1 and 96.0% top-5 on ImageNet.
Learning Graph Embeddings from WordNet-based Similarity Measures
We present a new approach for learning graph embeddings, that relies on structural measures of node similarities for generation of training data. The model learns node embeddings that are able to approximate a given measure, such as the shortest path distance or any other. Evaluations of the proposed model on semantic similarity and word sense disambiguation tasks (using WordNet as the source of gold similarities) show that our method yields state-of-the-art results, but also is capable in certain cases to yield even better performance than the input similarity measure. The model is computationally efficient, orders of magnitude faster than the direct computation of graph distances.
• Overview of the CLEF-2018 CheckThat! Lab on Automatic Identification and Verification of Political Claims. Task 1: Check-Worthiness• Transfer Learning for Brain-Computer Interfaces: An Euclidean Space Data Alignment Approach• A new Newton-type inequality and the concavity of a class of k-trace functions• An iterative method to estimate the combinatorial background• High-Performance Reconstruction of Microscopic Force Fields from Brownian Trajectories• Control Energy of Lattice Graphs• Cross-view image synthesis using geometry-guided conditional GANs• Strong Coordination over Noisy Channels• Non-iterative Joint Detection-Decoding Receiver for LDPC-Coded MIMO Systems Based on SDR• Quasi-transversal in Latin Squares• Characterization of multivariate distributions by means of univariate one• A novel Empirical Bayes with Reversible Jump Markov Chain in User-Movie Recommendation system• Vis4DD: A visualization system that supports Data Quality Visual Assessment• CBinfer: Exploiting Frame-to-Frame Locality for Faster Convolutional Network Inference on Video Streams• Configuration-Controlled Many-Body Localization and the Mobility Emulsion• Neural-network states for the classical simulation of quantum computing• Bit Threads and Holographic Monogamy• AnatomyNet: Deep 3D Squeeze-and-excitation U-Nets for fast and fully automated whole-volume anatomical segmentation• Control of Generalized Discrete-time SIS Epidemics via Submodular Function Minimization• Blended Coarse Gradient Descent for Full Quantization of Deep Neural Networks• LSTM-Based Goal Recognition in Latent Space• A Combinatorial-Probabilistic Analysis of Bitcoin Attacks• Edge Disjoint Spanning Trees in an Undirected Graph with E=2(V-1)• Edge Coloring Technique to Remove Small Elementary Trapping Sets from Tanner Graph of QC-LDPC Codes with Column Weight 4• Testing for Balance in Social Networks• DeepDownscale: a Deep Learning Strategy for High-Resolution Weather Forecast• Frank-Wolfe Style Algorithms for Large Scale Optimization• Tropical Cyclone Intensity Evolution Modeled as a Dependent Hidden Markov Process• Matrices in the Hosoya triangle• Measuring Human Assessed Complexity in Synthetic Aperture Sonar Imagery Using the Elo Rating System• DNN Feature Map Compression using Learned Representation over GF(2)• A New Nonparametric Estimate of the Risk-Neutral Density with Application to Variance Swap• Outer Approximation With Conic Certificates For Mixed-Integer Convex Problems• Tensor models for linguistics pitch curve data of native speakers of Afrikaans• Design-based Analysis in Difference-In-Differences Settings with Staggered Adoption• SINH-acceleration: efficient evaluation of probability distributions, option pricing, and Monte-Carlo simulations• Model Selection via the VC-Dimension• Monitoring through many eyes: Integrating scientific and crowd-sourced datasets to improve monitoring of the Great Barrier Reef• Linearly Solvable Mean-Field Road Traffic Games• Incorporating Consistency Verification into Neural Data-to-Document Generation• Treatment of material radioassay measurements in projecting sensitivity for low-background experiments• Toward domain-invariant speech recognition via large scale training• Edge-transitive graphs of small order and the answer to a 1967 question by Folkman• Self-supervised CNN for Unconstrained 3D Facial Performance Capture from a Single RGB-D Camera• Electronic properties of binary compounds with high fidelity and high throughput• Tier structure of strongly endotactic reaction networks• Sequential Behavioral Data Processing Using Deep Learning and the Markov Transition Field in Online Fraud Detection• On the Convergence of Learning-based Iterative Methods for Nonconvex Inverse Problems• Active Distribution Learning from Indirect Samples• Improved Chord Recognition by Combining Duration and Harmonic Language Models• Simultaneous Localization And Mapping with depth Prediction using Capsule Networks for UAVs• Limitations of performance of Exascale Applications and supercomputers they are running on• Genre-Agnostic Key Classification With Convolutional Neural Networks• Automatic Chord Recognition with Higher-Order Harmonic Language Modelling• Quality-Net: An End-to-End Non-intrusive Speech Quality Assessment Model based on BLSTM• Tool Breakage Detection using Deep Learning• Stochastic epidemics in a homogeneous community• Some Aspects on Solving Transportation Problem• Sparse Multivariate ARCH Models: Finite Sample Properties• Identifying Implementation Bugs in Machine Learning based Image Classifiers using Metamorphic Testing• Conceptual Domain Adaptation Using Deep Learning• Adversarial Collaborative Auto-encoder for Top-N Recommendation• Generalized Four Moment Theorem and an Application to CLT for Spiked Eigenvalues of Large-dimensional Covariance Matrices• A Smooth Double Proximal Primal-Dual Algorithm for a Class of Distributed Nonsmooth Optimization Problem• Strong Converse for Hypothesis Testing Against Independence over a Two-Hop Network• Some results and a conjecture on certain subclasses of graphs according to the relations among certain energies, degrees and conjugate degrees of graphs• Computing Word Classes Using Spectral Clustering• Local photo-mechanical stiffness revealed in gold nanoparticles supracrystals by ultrafast small-angle electron diffraction• Egocentric Gesture Recognition for Head-Mounted AR devices• Typhoon track prediction using satellite images in a Generative Adversarial Network• A Pipeline for Lenslet Light Field Quality Enhancement• Simple Load Balancing• Landmark Weighting for 3DMM Shape Fitting• Quasi-Sturmian colorings on regular trees• Nonconvex Regularization Based Sparse and Low-Rank Recovery in Signal Processing, Statistics, and Machine Learning• Novel Model-based Methods for Performance Optimization of Multithreaded 2D Discrete Fourier Transform on Multicore Processors• Decentralized Tube-based Model Predictive Control of Uncertain Nonlinear Multi-Agent Systems• Interleaving Channel Estimation and Limited Feedback for Point-to-Point Systems with a Large Number of Transmit Antennas• Optimal Designs for Poisson Count Data with Gamma Block Effects• Functional Outlier Detection and Taxonomy by Sequential Transformations• The Stochastic Fixed Point Problem and Consistent Stochastic Feasibility• Permutations avoiding 312 and another pattern, Chebyshev polynomials and longest increasing subsequences• Symmetric punctured intervals tile $\mathbb Z^3$• Sememe Prediction: Learning Semantic Knowledge from Unstructured Textual Wiki Descriptions• Linguistic data mining with complex networks: a stylometric-oriented approach• A comparative study of structural similarity and regularization for joint inverse problems governed by PDEs• Decomposing Correlated Random Walks on Common and Counter Movements• Transfer Learning and Organic Computing for Autonomous Vehicles• From $1$ to $6$: a finer analysis of perturbed branching Brownian motion• Automatic Generation of a Hybrid Query Execution Engine• Shared-memory Exact Minimum Cuts• Two first-order logics of permutations• Perfect $L_p$ Sampling in a Data Stream• Occlusion Resistant Object Rotation Regression from Point Cloud Segments• Measuring the Temporal Behavior of Real-World Person Re-Identification• Robust training of recurrent neural networks to handle missing data for disease progression modeling• Paraphrase Thought: Sentence Embedding Module Imitating Human Language Recognition• An Experimental Evaluation of Covariates Effects on Unconstrained Face Verification• Code generation for generally mapped finite elements• Network Decoupling: From Regular to Depthwise Separable Convolutions• Experiential Robot Learning with Accelerated Neuroevolution• Deep Learning for Energy Markets• Permutation-based simultaneous confidence bounds for the false discovery proportion• Simulation of McKean Vlasov SDEs with super linear growth• Szemerédi-Trotter type results in arbitrary finite fields• Weakly mixing smooth planar vector field without asymptotic directions• Growing Graceful Trees• Rigid linkages and partial zero forcing• The DALPHI annotation framework & how its pre-annotations can improve annotator efficiency• R$^3$-Net: A Deep Network for Multi-oriented Vehicle Detection in Aerial Images and Videos• Emotion Recognition in Speech using Cross-Modal Transfer in the Wild• Learning Invariances using the Marginal Likelihood• The linear hidden subset problem for the (1+1) EA with scheduled and adaptive mutation rates• Anatomy Of High-Performance Deep Learning Convolutions On SIMD Architectures• When Do Households Invest in Solar Photovoltaics? An Application of Prospect Theory• Toward a Nordhaus-Gaddum Inequality for the Number of Dominating Sets• Deeper Image Quality Transfer: Training Low-Memory Neural Networks for 3D Images• Deep Convolutional Networks as shallow Gaussian Processes• An orthosymplectic Pieri rule• Randomization for the direct effect of an infectious disease intervention in a clustered study population• Improving Conditional Sequence Generative Adversarial Networks by Stepwise Evaluation• An information-theoretic approach to self-organisation: Emergence of complex interdependencies in coupled dynamical systems• Volume Bounds for the Phase-locking Region in the Kuramoto Model with Asymmetric Coupling• Universal Covertness for Discrete Memoryless Sources
Like this:
Like Loading…
Related