X-GANs: Image Reconstruction Made Easy for Extreme Cases
Image reconstruction including image restoration and denoising is a challenging problem in the field of image computing. We present a new method, called X-GANs, for reconstruction of arbitrary corrupted resource based on a variant of conditional generative adversarial networks (conditional GANs). In our method, a novel generator and multi-scale discriminators are proposed, as well as the combined adversarial losses, which integrate a VGG perceptual loss, an adversarial perceptual loss, and an elaborate corresponding point loss together based on the analysis of image feature. Our conditional GANs have enabled a variety of applications in image reconstruction, including image denoising, image restoration from quite a sparse sampling, image inpainting, image recovery from the severely polluted block or even color-noise dominated images, which are extreme cases and haven’t been addressed in the status quo. We have significantly improved the accuracy and quality of image reconstruction. Extensive perceptual experiments on datasets ranging from human faces to natural scenes demonstrate that images reconstructed by the presented approach are considerably more realistic than alternative work. Our method can also be extended to handle high-ratio image compression.
Deep Learning Based Natural Language Processing for End to End Speech Translation
Deep Learning methods employ multiple processing layers to learn hierarchial representations of data. They have already been deployed in a humongous number of applications and have produced state-of-the-art results. Recently with the growth in processing power of computers to be able to do high dimensional tensor calculations, Natural Language Processing (NLP) applications have been given a significant boost in terms of efficiency as well as accuracy. In this paper, we will take a look at various signal processing techniques and then application of them to produce a speech-to-text system using Deep Recurrent Neural Networks.
Out of the Black Box: Properties of deep neural networks and their applications
Deep neural networks are powerful machine learning approaches that have exhibited excellent results on many classification tasks. However, they are considered as black boxes and some of their properties remain to be formalized. In the context of image recognition, it is still an arduous task to understand why an image is recognized or not. In this study, we formalize some properties shared by eight state-of-the-art deep neural networks in order to grasp the principles allowing a given deep neural network to classify an image. Our results, tested on these eight networks, show that an image can be sub-divided into several regions (patches) responding at different degrees of probability (local property). With the same patch, some locations in the image can answer two (or three) orders of magnitude higher than other locations (spatial property). Some locations are activators and others inhibitors (activation-inhibition property). The repetition of the same patch can increase (or decrease) the probability of recognition of an object (cumulative property). Furthermore, we propose a new approach called Deepception that exploits these properties to deceive a deep neural network. We obtain for the VGG-VDD-19 neural network a fooling ratio of 88\%. Thanks to our ‘Psychophysics’ approach, no prior knowledge on the networks architectures is required.
D-PAGE: Diverse Paraphrase Generation
In this paper, we investigate the diversity aspect of paraphrase generation. Prior deep learning models employ either decoding methods or add random input noise for varying outputs. We propose a simple method Diverse Paraphrase Generation (D-PAGE), which extends neural machine translation (NMT) models to support the generation of diverse paraphrases with implicit rewriting patterns. Our experimental results on two real-world benchmark datasets demonstrate that our model generates at least one order of magnitude more diverse outputs than the baselines in terms of a new evaluation metric Jeffrey’s Divergence. We have also conducted extensive experiments to understand various properties of our model with a focus on diversity.
RedSync : Reducing Synchronization Traffic for Distributed Deep Learning
Data parallelism has already become a dominant method to scale Deep Neural Network (DNN) training to multiple computation nodes. Considering that the synchronization of local model or gradient between iterations can be a bottleneck for large-scale distributed training, compressing communication traffic has gained widespread attention recently. Among several recent proposed compression algorithms, Residual Gradient Compression (RGC) is one of the most successful approaches—it can significantly compress the message size (0.1% of the original size) and still preserve accuracy. However, the literature on compressing deep networks focuses almost exclusively on finding good compression rate, while the efficiency of RGC in real implementation has been less investigated. In this paper, we explore the potential of application RGC method in the real distributed system. Targeting the widely adopted multi-GPU system, we proposed an RGC system design call RedSync, which includes a set of optimizations to reduce communication bandwidth while introducing limited overhead. We examine the performance of RedSync on two different multiple GPU platforms, including a supercomputer and a multi-card server. Our test cases include image classification and language modeling tasks on Cifar10, ImageNet, Penn Treebank and Wiki2 datasets. For DNNs featured with high communication to computation ratio, which have long been considered with poor scalability, RedSync shows significant performance improvement.
Thou shalt not hate: Countering Online Hate Speech
Hate content in social media is ever increasing. While Facebook, Twitter, Google have attempted to take several steps to tackle this hate content, they most often risk the violation of freedom of speech. Counterspeech, on the other hand, provides an effective way of tackling the online hate without the loss of freedom of speech. Thus, an alternative strategy for these platforms could be to promote counterspeech as a defense against hate content. However, in order to have a successful promotion of such counterspeech, one has to have a deep understanding of its dynamics in the online world. Lack of carefully curated data largely inhibits such understanding. In this paper, we create and release the first ever dataset for counterspeech using comments from YouTube. The data contains 9438 manually annotated comments where the labels indicate whether a comment is a counterspeech or not. This data allows us to perform a rigorous measurement study characterizing the linguistic structure of counterspeech for the first time. This analysis results in various interesting insights such as: the counterspeech comments receive double the likes received by the non-counterspeech comments, for certain communities majority of the non-counterspeech comments tend to be hate speech, the different types of counterspeech are not all equally effective and the language choice of users posting counterspeech is largely different from those posting non-counterspeech as revealed by a detailed psycholinguistic analysis. Finally, we build a set of machine learning models that are able to automatically detect counterspeech in YouTube videos with an F1-score of 0.73.
A Feature Selection Method for High Impedance Fault Detection
High impedance fault (HIF) has been a challenging task to detect in distribution networks. On one hand, although several types of HIF models are available for HIF study, they are still not exhibiting satisfactory fault waveforms. On the other hand, utilizing historical data has been a trend recently for using machine learning methods to improve HIF detection. Nonetheless, most proposed methodologies address the HIF issue starting with investigating a limited group of features and can hardly provide a practical and implementable solution. This paper, however, proposes a systematic design of feature extraction, based on an HIF detection and classification method. For example, features are extracted according to when, how long, and what magnitude the fault events create. Complementary power expert information is also integrated into the feature pools. Subsequently, we propose a ranking procedure in the feature pool for balancing the information gain and the complexity to avoid over-fitting. For implementing the framework, we create an HIF detection logic from a practical perspective. Numerical methods show the proposed HIF detector has very high dependability and security performance under multiple fault scenarios comparing with other traditional methods.
Risk-Sensitive Generative Adversarial Imitation Learning
We study risk-sensitive imitation learning where the agent’s goal is to perform at least as well as the expert in terms of a risk profile. We first formulate our risk-sensitive imitation learning setting. We consider the generative adversarial approach to imitation learning (GAIL) and derive an optimization problem for our formulation, which we call risk-sensitive GAIL (RS-GAIL). We then derive two different versions of our RS-GAIL optimization problem that aim at matching the risk profiles of the agent and the expert w.r.t. Jensen-Shannon (JS) divergence and Wasserstein distance, and develop risk-sensitive generative adversarial imitation learning algorithms based on these optimization problems. We evaluate the performance of our JS-based algorithm and compare it with GAIL and the risk-averse imitation learning (RAIL) algorithm in two MuJoCo tasks.
Deep Randomized Ensembles for Metric Learning
Learning embedding functions, which map semantically related inputs to nearby locations in a feature space supports a variety of classification and information retrieval tasks. In this work, we propose a novel, generalizable and fast method to define a family of embedding functions that can be used as an ensemble to give improved results. Each embedding function is learned by randomly bagging the training labels into small subsets. We show experimentally that these embedding ensembles create effective embedding functions. The ensemble output defines a metric space that improves state of the art performance for image retrieval on CUB-200-2011, Cars-196, In-Shop Clothes Retrieval and VehicleID.
DeepBase: Deep Inspection of Neural Networks
Although deep learning models perform remarkably across a range of tasks such as language translation, parsing, and object recognition, it remains unclear whether, and to what extent, these models follow human-understandable logic or procedures when making predictions. Understanding this can lead to more interpretable models, better model design, and faster experimentation. Recent machine learning research has leveraged statistical methods to identify hidden units that behave (e.g., activate) similarly to human understandable logic such as detecting language features, however each analysis requires considerable manual effort. Our insight is that, from a query processing perspective, this high level logic is a query evaluated over a database of neural network hidden unit behaviors. This paper describes DeepBase, a system to inspect neural network behaviors through a query-based interface. We model high-level logic as hypothesis functions that transform an input dataset into time series signals. DeepBase lets users quickly identify individual or groups of units that have strong statistical dependencies with desired hypotheses. In fact, we show how many existing analyses are expressible as a single DeepBase query. We use DeepBase to analyze recurrent neural network models, and propose a set of simple and effective optimizations to speed up existing analysis approaches by up to 413x. We also group and analyze different portions of a real-world neural translation model and show that learns syntactic structure, which is consistent with prior NLP studies, but can be performed with only 3 DeepBase queries.
Fine-Grained Representation Learning and Recognition by Exploiting Hierarchical Semantic Embedding
Object categories inherently form a hierarchy with different levels of concept abstraction, especially for fine-grained categories. For example, birds (Aves) can be categorized according to a four-level hierarchy of order, family, genus, and species. This hierarchy encodes rich correlations among various categories across different levels, which can effectively regularize the semantic space and thus make prediction less ambiguous. However, previous studies of fine-grained image recognition primarily focus on categories of one certain level and usually overlook this correlation information. In this work, we investigate simultaneously predicting categories of different levels in the hierarchy and integrating this structured correlation information into the deep neural network by developing a novel Hierarchical Semantic Embedding (HSE) framework. Specifically, the HSE framework sequentially predicts the category score vector of each level in the hierarchy, from highest to lowest. At each level, it incorporates the predicted score vector of the higher level as prior knowledge to learn finer-grained feature representation. During training, the predicted score vector of the higher level is also employed to regularize label prediction by using it as soft targets of corresponding sub-categories. To evaluate the proposed framework, we organize the 200 bird species of the Caltech-UCSD birds dataset with the four-level category hierarchy and construct a large-scale butterfly dataset that also covers four level categories. Extensive experiments on these two and the newly-released VegFru datasets demonstrate the superiority of our HSE framework over the baseline methods and existing competitors.
A Record Linkage Model Incorporating Relational Data
In this paper we introduce a novel Bayesian approach for linking multiple social networks in order to discover the same real world person having different accounts across networks. In particular, we develop a latent model that allow us to jointly characterize the network and linkage structures relying in both relational and profile data. In contrast to other existing approaches in the machine learning literature, our Bayesian implementation naturally provides uncertainty quantification via posterior probabilities for the linkage structure itself or any function of it. Our findings clearly suggest that our methodology can produce accurate point estimates of the linkage structure even in the absence of profile information, and also, in an identity resolution setting, our results confirm that including relational data into the matching process improves the linkage accuracy. We illustrate our methodology using real data from popular social networks such as Twitter, Facebook, and YouTube.
Ridge Rerandomization: An Experimental Design Strategy in the Presence of Collinearity
Randomization ensures that observed and unobserved covariates are balanced, on average. However, randomizing units to treatment and control often leads to covariate imbalances in realization, and such imbalances can inflate the variance of estimators of the treatment effect. One solution to this problem is rerandomization—an experimental design strategy that randomizes units until some balance criterion is fulfilled—which yields more precise estimators of the treatment effect if covariates are correlated with the outcome. Most rerandomization schemes in the literature utilize the Mahalanobis distance, which may not be preferable when covariates are correlated or vary in importance. As an alternative, we introduce an experimental design strategy called ridge rerandomization, which utilizes a modified Mahalanobis distance that addresses collinearities among covariates and automatically places a hierarchy of importance on the covariates according to their eigenstructure. This modified Mahalanobis distance has connections to principal components and the Euclidean distance, and—to our knowledge—has remained unexplored. We establish several theoretical properties of this modified Mahalanobis distance and our ridge rerandomization scheme. These results guarantee that ridge rerandomization is preferable over randomization and suggest when ridge rerandomization is preferable over standard rerandomization schemes. We also provide simulation evidence that suggests that ridge rerandomization is particularly preferable over typical rerandomization schemes in high-dimensional or high-collinearity settings.
A Comprehensive Survey for Low Rank Regularization
Low rank regularization, in essence, involves introducing a low rank or approximately low rank assumption for matrix we aim to learn, which has achieved great success in many fields including machine learning, data mining and computer version. Over the last decade, much progress has been made in theories and practical applications. Nevertheless, the intersection between them is very slight. In order to construct a bridge between practical applications and theoretical research, in this paper we provide a comprehensive survey for low rank regularization. We first review several traditional machine learning models using low rank regularization, and then show their (or their variants) applications in solving practical issues, such as non-rigid structure from motion and image denoising. Subsequently, we summarize the regularizers and optimization methods that achieve great success in traditional machine learning tasks but are rarely seen in solving practical issues. Finally, we provide a discussion and comparison for some representative regularizers including convex and non-convex relaxations. Extensive experimental results demonstrate that non-convex regularizers can provide a large advantage over the nuclear norm, the regularizer widely used in solving practical issues.
Discrete Structural Planning for Neural Machine Translation
Structural planning is important for producing long sentences, which is a missing part in current language generation models. In this work, we add a planning phase in neural machine translation to control the coarse structure of output sentences. The model first generates some planner codes, then predicts real output words conditioned on them. The codes are learned to capture the coarse structure of the target sentence. In order to obtain the codes, we design an end-to-end neural network with a discretization bottleneck, which predicts the simplified part-of-speech tags of target sentences. Experiments show that the translation performance are generally improved by planning ahead. We also find that translations with different structures can be obtained by manipulating the planner codes.
MT-VAE: Learning Motion Transformations to Generate Multimodal Human Dynamics
Long-term human motion can be represented as a series of motion modes—motion sequences that capture short-term temporal dynamics—with transitions between them. We leverage this structure and present a novel Motion Transformation Variational Auto-Encoders (MT-VAE) for learning motion sequence generation. Our model jointly learns a feature embedding for motion modes (that the motion sequence can be reconstructed from) and a feature transformation that represents the transition of one motion mode to the next motion mode. Our model is able to generate multiple diverse and plausible motion sequences in the future from the same input. We apply our approach to both facial and full body motion, and demonstrate applications like analogy-based motion transfer and video synthesis.
Small Sample Learning in Big Data Era
As a promising area in artificial intelligence, a new learning paradigm, called Small Sample Learning (SSL), has been attracting prominent research attention in the recent years. In this paper, we aim to present a survey to comprehensively introduce the current techniques proposed on this topic. Specifically, current SSL techniques can be mainly divided into two categories. The first category of SSL approaches can be called ‘concept learning’, which emphasizes learning new concepts from only few related observations. The purpose is mainly to simulate human learning behaviors like recognition, generation, imagination, synthesis and analysis. The second category is called ‘experience learning’, which usually co-exists with the large sample learning manner of conventional machine learning. This category mainly focuses on learning with insufficient samples, and can also be called small data learning in some literatures. More extensive surveys on both categories of SSL techniques are introduced and some neuroscience evidences are provided to clarify the rationality of the entire SSL regime, and the relationship with human learning process. Some discussions on the main challenges and possible future research directions along this line are also presented.
Reconciling Irrational Human Behavior with AI based Decision Making: A Quantum Probabilistic Approach
There are many examples of human decision making which cannot be modeled by classical probabilistic and logic models, on which the current AI systems are based. Hence the need for a modeling framework which can enable intelligent systems to detect and predict cognitive biases in human decisions to facilitate better human-agent interaction. We give a few examples of irrational behavior and use a generalized probabilistic model inspired by the mathematical framework of Quantum Theory to model and explain such behavior.
R-grams: Unsupervised Learning of Semantic Units in Natural Language
This paper introduces a novel type of data-driven segmented unit that we call r-grams. We illustrate one algorithm for calculating r-grams, and discuss its properties and impact on the frequency distribution of text representations. The proposed approach is evaluated by demonstrating its viability in embedding techniques, both in monolingual and multilingual test settings. We also provide a number of qualitative examples of the proposed methodology, demonstrating its viability as a language-invariant segmentation procedure.
Probabilistic forecasting of heterogeneous consumer transaction-sales time series
We present new Bayesian methodology for consumer sales forecasting. With a focus on multi-step ahead forecasting of daily sales of many supermarket items, we adapt dynamic count mixture models to forecast individual customer transactions, and introduce novel dynamic binary cascade models for predicting counts of items per transaction. These transactions-sales models can incorporate time-varying trend, seasonal, price, promotion, random effects and other outlet-specific predictors for individual items. Sequential Bayesian analysis involves fast, parallel filtering on sets of decoupled items and is adaptable across items that may exhibit widely varying characteristics. A multi-scale approach enables information sharing across items with related patterns over time to improve prediction while maintaining scalability to many items. A motivating case study in many-item, multi-period, multi-step ahead supermarket sales forecasting provides examples that demonstrate improved forecast accuracy in multiple metrics, and illustrates the benefits of full probabilistic models for forecast accuracy evaluation and comparison. Keywords: Bayesian forecasting; decouple/recouple; dynamic binary cascade; forecast calibration; intermittent demand; multi-scale forecasting; predicting rare events; sales per transaction; supermarket sales forecasting
Cache Telepathy: Leveraging Shared Resource Attacks to Learn DNN Architectures
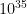
Retrieve and Refine: Improved Sequence Generation Models For Dialogue
Sequence generation models for dialogue are known to have several problems: they tend to produce short, generic sentences that are uninformative and unengaging. Retrieval models on the other hand can surface interesting responses, but are restricted to the given retrieval set leading to erroneous replies that cannot be tuned to the specific context. In this work we develop a model that combines the two approaches to avoid both their deficiencies: first retrieve a response and then refine it — the final sequence generator treating the retrieval as additional context. We show on the recent CONVAI2 challenge task our approach produces responses superior to both standard retrieval and generation models in human evaluations.
Testing Graph Clusterability: Algorithms and Lower Bounds

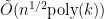
KGCleaner : Identifying and Correcting Errors Produced by Information Extraction Systems

• A novel method for predicting and mapping the presence of sun glare using Google Street View• Spatial and Spectral Features Fusion for EEG Classification during Motor Imagery in BCI• FaceOff: Anonymizing Videos in the Operating Rooms• Deep Learning Super-Resolution Enables Rapid Simultaneous Morphological and Quantitative Magnetic Resonance Imaging• Starting Movement Detection of Cyclists Using Smart Devices• Smart Device based Initial Movement Detection of Cyclists using Convolutional Neuronal Networks• Neural Machine Translation Inspired Binary Code Similarity Comparison beyond Function Pairs• Online UAV Path Planning for Joint Detection and Tracking of Multiple Radio-tagged Objects• Deep Morphing: Detecting bone structures in fluoroscopic X-ray images with prior knowledge• Character-Level Language Modeling with Deeper Self-Attention• Mining Threat Intelligence about Open-Source Projects and Libraries from Code Repository Issues and Bug Reports• A Hassle-Free Machine Learning Method for Cohort Selection of Clinical Trials• RoadNet-v2: A 10 ms Road Segmentation Using Spatial Sequence Layer• Image Registration and Predictive Modeling: Learning the Metric on the Space of Diffeomorphisms• Quantum Algorithms for Autocorrelation Spectrum• Hybrid multilane models for highway traffic• Dynamic programming for optimal stopping via pseudo-regression• Mind Your Language: Learning Visually Grounded Dialog in a Multi-Agent Setting• Stochastic on-time arrival problem in transit networks• Measuring Market Performance with Stochastic Demand: Price of Anarchy and Price of Uncertainty• A Domain Guided CNN Architecture for Predicting Age from Structural Brain Images• Pixel Objectness: Learning to Segment Generic Objects Automatically in Images and Videos• Computing Equilibria in Atomic Splittable Polymatroid Congestion Games with Convex Costs• What is wrong with style transfer for texts?• A Survey on Methods and Theories of Quantized Neural Networks• A $q$-analogue of the identity $\sum_{k=0}^\infty\frac{(-1)^k}{(2k+1)^3}=\frac{π^3}{32}$• Cross-Cultural and Cultural-Specific Production and Perception of Facial Expressions of Emotion in the Wild• Locally-adaptive Bayesian nonparametric inference for phylodynamics• Extracting Inter-community Conflicts in Reddit• Background information for meta-analysis evaluation, Info 00-Info 06• Murmur Detection Using Parallel Recurrent & Convolutional Neural Networks• Large Graph Exploration via Subgraph Discovery and Decomposition• Extrapolating Treatment Effects in Multi-Cutoff Regression Discontinuity Designs• Social media and mobility landscape: uncovering spatial patterns of urban human mobility with multi source data• Completeness results for metrized rings and lattices• Multimodal Deep Neural Networks using Both Engineered and Learned Representations for Biodegradability Prediction• On Passivity, Reinforcement Learning and Higher-Order Learning in Multi-Agent Finite Games• Distributed GNE seeking under partial-decision information over networks via a doubly-augmented operator splitting approach• Decentralized Equalization with Feedforward Architectures for Massive MU-MIMO• Kernel Flows: from learning kernels from data into the abyss• Self-avoiding walk, spin systems, and renormalisation• Interacting elephant random walks• Risk Sensitive Multiple Goal Stochastic Optimization, with application to Risk Sensitive Partially Observed Markov Decision Processes• Allocation of Graph Jobs in Geo-Distributed Cloud Networks• Fast Convergence for Object Detection by Learning how to Combine Error Functions• Binary disorder in quantum Ising chains and induced Majorana zero modes• Global Density Analysis for an Off-Lattice Cellular Automata Model• Rigidity of symmetric frameworks in normed spaces• CLAIRE: A distributed-memory solver for constrained large deformation diffeomorphic image registration• Generative Invertible Networks (GIN): Pathophysiology-Interpretable Feature Mapping and Virtual Patient Generation• Convex relaxation approaches for strictly correlated density functional theory• ScarGAN: Chained Generative Adversarial Networks to Simulate Pathological Tissue on Cardiovascular MR Scans• Shared Multi-Task Imitation Learning for Indoor Self-Navigation• Alternating Iterative Secure Structure between Beamforming and Power Allocation for UAV-aided Directional Modulation Networks• On the approximability of the stable matching problem with ties of size two• Multicast Triangular Semilattice Network• Relaxation algorithms for matrix completion, with applications to seismic travel-time data interpolation• A machine-learning solver for modified diffusion equations• Adaptive Sampling for Convex Regression• Weight Learning in a Probabilistic Extension of Answer Set Programs• Hybrid Powerline/Wireless Diversity for Smart Grid Communications: Design Challenges and Real-time Implementation• An Extension of Waring’s Problem in Z_{p^k}• Learning Linear Transformations for Fast Arbitrary Style Transfer• Text-to-Image-to-Text Translation using Cycle Consistent Adversarial Networks• Constructions of maximally recoverable local reconstruction codes via function fields• A Ramsey-type theorem for the matching number regarding connected graphs• Machine Learning for Heterogeneous Ultra-Dense Networks with Graphical Representations• SciSports: Learning football kinematics through two-dimensional tracking data• Moving Object Segmentation in Jittery Videos by Stabilizing Trajectories Modeled in Kendall’s Shape Space• Spectral bounds for non-uniform hypergraphs using weighted clique expansion• A Method for Quickly Bounding the Optimal Objective Value of an OPF Problem using a Semidefinite Relaxation and a Local Solution• Explicit construction of optimal locally recoverable codes of distance 5 and 6 via binary constant weight codes• Deep Retinex Decomposition for Low-Light Enhancement• Commutation matrices and Commutation tensors• Learning A Shared Transform Model for Skull to Digital Face Image Matching• Effect of filter shape on excess noise performance in continuous variable quantum key distribution with Gaussian modulation• Automatic Airway Segmentation in chest CT using Convolutional Neural Networks• Two constructions of optimal pairs of linear codes for resisting side channel and fault injection attacks• Bringing Together Dynamic Geometry Software and the Graphics Processing Unit• NFFT meets Krylov methods: Fast matrix-vector products for the graph Laplacian of fully connected networks• The joint distribution of pin-point plant cover data: a reparametrized Dirichlet – multinomial distribution• DeepNeuro: an open-source deep learning toolbox for neuroimaging• Cracked Polytopes and Fano Toric Complete Intersections• Jump inequalities via real interpolation• Unsupervised learning of foreground object detection• On the stability and applications of distance-based flexible formations• Delayed Dynamical Systems: Networks, Chimeras and Reservoir Computing• Oriented first passage percolation in the mean field limit, 2. The extremal process• Hashing with Linear Probing and Referential Integrity• AFEL-REC: A Recommender System for Providing Learning Resource Recommendations in Social Learning Environments• Risk-based optimal portfolio of an insurer with regime switching and noisy memory• On the optimal investment-consumption and life insurance selection problem with an external stochastic factor• The Optimal Constant in Generalized Hardy’s Inequality• Looking Beyond a Clever Narrative: Visual Context and Attention are Primary Drivers of Affect in Video Advertisements• A note on representation of BSDE-based dynamic risk measures and dynamic capital allocations• Motion Feasibility Conditions for Multi-Agent Control Systems on Lie Groups• Optimal investment-consumption and life insurance with capital constraints• Explaining Queries over Web Tables to Non-Experts• Wirelessly Powered Data Aggregation for IoT via Over-the-Air Functional Computation: Beamforming and Power Control• Joint Ground and Aerial Package Delivery Services: A Stochastic Optimization Approach• On Robustness of Massive MIMO Systems Against Passive Eavesdropping under Antenna Selection• Applying the Closed World Assumption to SUMO-based Ontologies• Large Deviation Principle for Reflected Poisson driven SDEs in Epidemic Models• Random noise increases Kolmogorov complexity and Hausdorff dimension• A Novel Sliding Mode Control for a Class of Affine Dynamic Systems• A topological characterization of Gauss codes• Deep Learning Framework for Digital Breast Tomosynthesis Reconstruction• An Adaptive Primal-Dual Framework for Nonsmooth Convex Minimization• A Simple Primal-Dual Approximation Algorithm for 2-Edge-Connected Spanning Subgraphs• Network Sampling Using K-hop Random Walks for Heterogeneous Network Embedding• Efficient Sum-of-Sinusoids based Spatial Consistency for the 3GPP New-Radio Channel Model• Primal Meaning Recommendation for Chinese Words and Phrases via Descriptions in On-line Encyclopedia• Evaluating Datalog via Tree Automata and Cycluits• Sea of Lights: Practical Device-to-Device Security Bootstrapping in the Dark• An Optimal Policy for Patient Laboratory Tests in Intensive Care Units• Maintaining both availability and integrity of communications: Challenges and guidelines for data security and privacy during disasters and crises• Learning ReLU Networks on Linearly Separable Data: Algorithm, Optimality, and Generalization• Plus-one generated and next to free arrangements of hyperplanes• Improving Generalization via Scalable Neighborhood Component Analysis• Asynchronous Sequential Inertial Iterations for Common Fixed Points Problems with an Application to Linear Systems• CosmoFlow: Using Deep Learning to Learn the Universe at Scale• Analyzing Inverse Problems with Invertible Neural Networks• Optimal probabilities and controls for reflecting diffusion processes• Adversarial Neural Networks for Cross-lingual Sequence Tagging• Simulating Markov random fields with a conclique-based Gibbs sampler• A Novel Method for Determining DOA from Far-Field TDOA or FDOA• Imagining the Unseen: Learning a Distribution over Incomplete Images with Dense Latent Trees• A penalty scheme for monotone systems with interconnected obstacles: convergence and error estimates• Quantifying the Influences on Probabilistic Wind Power Forecasts• Estimating the size of a hidden finite set: large-sample behavior of estimators• Treepedia 2.0: Applying Deep Learning for Large-scale Quantification of Urban Tree Cover• Addressing Johnson graphs, complete multipartite graphs, odd cycles and other graphs• Finding Minimal Cost Herbrand Models with Branch-Cut-and-Price• An Overview and a Benchmark of Active Learning for One-Class Classification• Parallel Statistical and Machine Learning Methods for Estimation of Physical Load• Discrete versus continuous domain models for disease mapping• Adaptive Skip Intervals: Temporal Abstraction for Recurrent Dynamical Models• Probabilistic $K$-mean with local alignment for clustering and motif discovery in functional data• Hedetniemi’s conjecture and strongly multiplicative graphs• Multivariate Density Estimation with Missing Data• Weight-Preserving Simulated Tempering• DNA-based chemical compiler• Improving Hearthstone AI by Combining MCTS and Supervised Learning Algorithms• Clumped Nuclei Segmentation with Adjacent Point Match and Local Shape based Intensity Analysis for Overlapped Nuclei in Fluorescence In-Situ Hybridization Images• On Applying Meta-path for Network Embedding in Mining Heterogeneous DBLP Network• Classifier Ensembles for Dialect and Language Variety Identification• Hierarchical binary CNNs for landmark localization with limited resources• Finding morphology points of electrocardiographic signal waves using wavelet analysis• AMoDSim: An Efficient and Modular Simulation Framework for Autonomous Mobility on Demand• Multispectral Pedestrian Detection via Simultaneous Detection and Segmentation
Like this:
Like Loading…
Related