
“I am a student of computer science/engineering. How do I get into the field of machine learning/deep learning/AI?”
It’s never been easier to get started with machine learning. In addition to structured MOOCs, there is also a huge number of incredible, free resources available around the web. Here are just a few that have helped me:
-
Start with some cool videos on YouTube. Read a couple of good books or articles. For example, have you read “The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World”? And I can guarantee you’ll fall in love with this cool interactive page about machine learning?
-
Learn to clearly differentiate between buzzwords first — machine learning, artificial intelligence, deep learning, data science, computer vision, robotics. Read or listen to the talks, given by experts, on each of them. Watch this amazing video by Brandon Rohrer, an influential data scientist. Or this video about the clear definition and difference of various rolesassociated with data science.
-
Have your goal clearly set for what you want to learn. And then, go and take that Coursera course. Or take the other one from Univ. of Washington, which is pretty good too.
-
Follow some good blogs : KDnuggets, Mark Meloon’s blog about data science career, Brandon Rohrer’s blog, Open AI’s blog about their research,
Is Python a good language of choice for Machine Learning/AI?
Familiarity and moderate expertise in at least one high-level programming language is useful for beginners in machine learning. Unless you are a Ph.D. researcher working on a purely theoretical proof of some complex algorithm, you are expected to mostly use the existing machine learning algorithms and apply them in solving novel problems. This requires you to put on a programming hat.
There’s a lot of debate on the ‘best language for data science’. While the debate rage, grab a coffee and read this insightful article to get an idea and see your choices. Or, check out this post on KDnuggets. For now, it’s widely believed that Python helps developers to be more productive from development to deployment and maintenance. Python’s syntax is simpler and of a higher level when compared to Java, C, and C++. It has a vibrant community, open-source culture, hundreds of high-quality libraries focused on machine learning, and a huge support base from big names in the industry (e.g. Google, Dropbox, Airbnb, etc.). This article will focus on some essential hacks and tricks in Python focused on machine learning.
Fundamental Libraries to know and master
There are few core Python packages/libraries you need to master for practicing machine learning effectively. Very brief description of those are given below,
Numpy
Short for Numerical Python, NumPy is the fundamental package required for high performance scientific computing and data analysis in the Python ecosystem. It’s the foundation on which nearly all of the higher-level tools such as Pandas and scikit-learn are built. TensorFlow uses NumPy arrays as the fundamental building block on top of which they built their Tensor objects and graphflow for deep learning tasks. Many NumPy operations are implemented in C, making them super fast. For data science and modern machine learning tasks, this is an invaluable advantage.

Pandas
This is the most popular library in the scientific Python ecosystem for doing general-purpose data analysis. Pandas is built upon Numpy array thereby preserving the feature of fast execution speed and offering many data engineering features including:
-
Reading/writing many different data formats
-
Selecting subsets of data
-
Calculating across rows and down columns
-
Finding and filling missing data
-
Applying operations to independent groups within the data
-
Reshaping data into different forms
-
Combing multiple datasets together
-
Advanced time-series functionality
-
Visualization through Matplotlib and Seaborn

Matplotlib and Seaborn
Data visualization and storytelling with your data are essential skills that every data scientist needs to communicate insights gained from analyses effectively to any audience out there. This is equally critical in pursuit of machine learning mastery too as often in your ML pipeline, you need to perform exploratory analysis of the data set before deciding to apply particular ML algorithm.
Matplotlib is the most widely used 2-D Python visualization library equipped with a dazzling array of commands and interfaces for producing publication-quality graphics from your data. Here is an amazingly detailed and rich article on getting you started on Matplotlib.
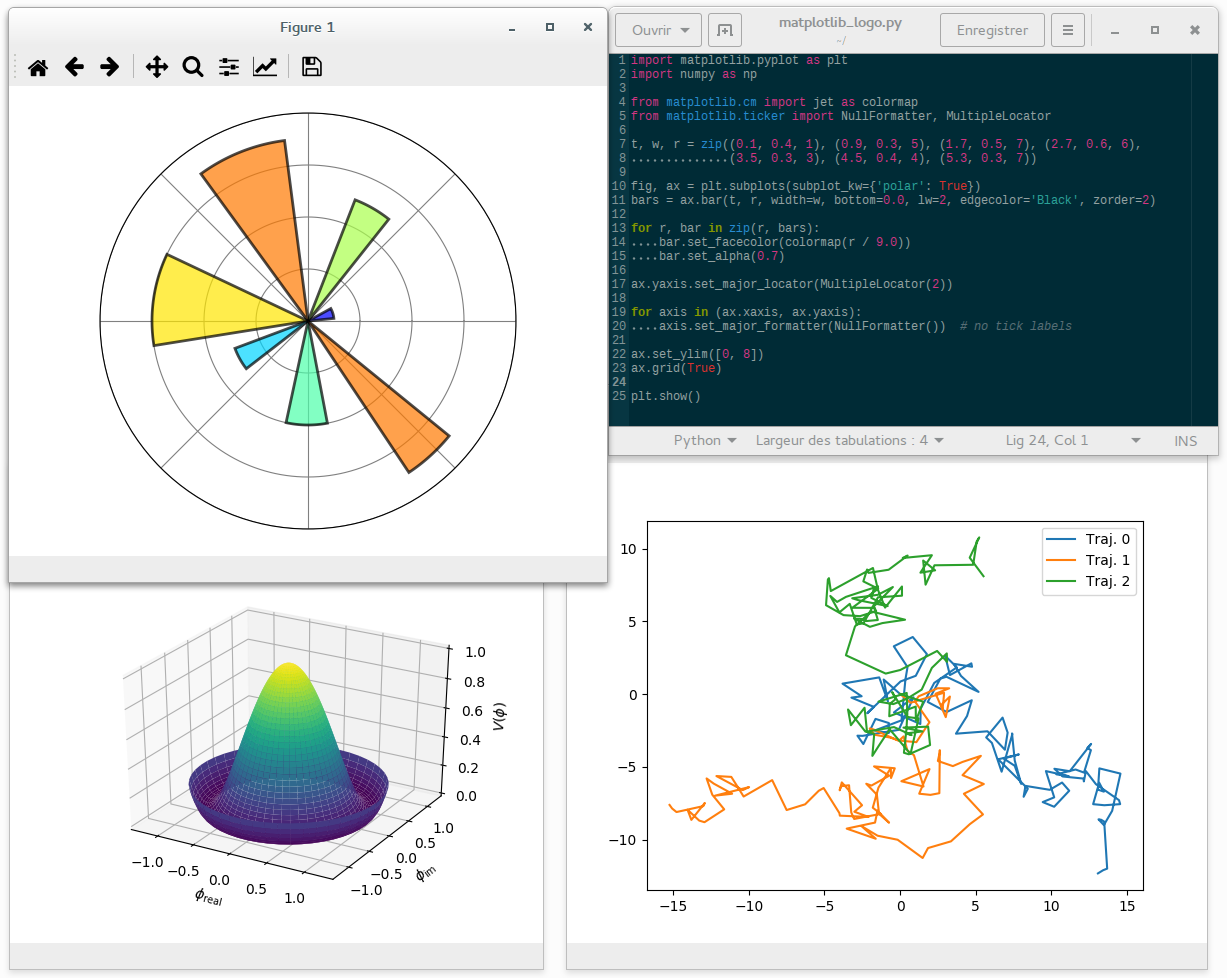
Seaborn is another great visualization library focused on statistical plotting. It’s worth learning for machine learning practitioners. Seaborn provides an API (with flexible choices for plot style and color defaults) on top of Matplotlib, defines simple high-level functions for common statistical plot types, and integrates with the functionality provided by Pandas. Here is a great tutorial on Seaborn for beginners.
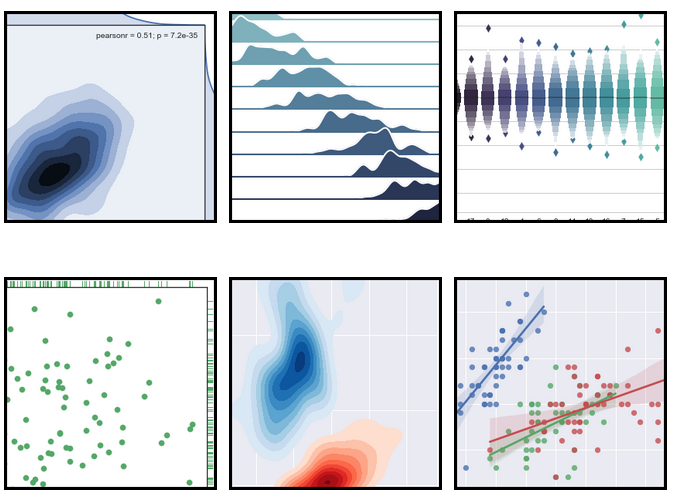 Example of Seaborn plots
Example of Seaborn plots
Scikit-learn
Scikit-learn is the most important general machine learning Python package you must master. It features various classification, regression, and clustering algorithms, including support vector machines, random forests, gradient boosting, k-means, and DBSCAN, and is designed to inter-operate with the Python numerical and scientific libraries NumPy and SciPy. It provides a range of supervised and unsupervised learning algorithms via a consistent interface. The vision for the library has a level of robustness and support required for use in production systems. This means a deep focus on concerns such as ease of use, code quality, collaboration, documentation, and performance. Look at this gentle introduction to machine learning vocabulary as used in the Scikit-learn universe. Here is another article demonstrating a simple machine learning pipeline method using Scikit-learn.
Some hidden gems of Scikit-learn
Scikit-learn is a great package to master for machine learning beginners and seasoned professionals alike. However, even experienced ML practitioners may not be aware of all the hidden gems of this package which can aid in their task significantly. I am trying to list few of these relatively lesser known methods/interfaces available in scikit-learn.
Pipeline : This can be used to chain multiple estimators into one. This is useful as there is often a fixed sequence of steps in processing the data, for example feature selection, normalization and classification. Here is more info about it.
Grid-search : Hyper-parameters are parameters that are not directly learnt within estimators. In scikit-learn they are passed as arguments to the constructor of the estimator classes. It is possible and recommended to search the hyper-parameter space for the best cross validation score. Any parameter provided when constructing an estimator may be optimized in this manner. Read more about it here.
Validation curves : Every estimator has its advantages and drawbacks. Its generalization error can be decomposed in terms of bias, variance and noise. The bias of an estimator is its average error for different training sets. The variance of an estimator indicates how sensitive it is to varying training sets. Noise is a property of the data. It is very helpful to plot the influence of a single hyperparameter on the training score and the validation score to find out whether the estimator is overfitting or underfitting for some hyperparameter values. Scikit-learn has a built-in method to help here.
One-hot encoding of categorial data : It is an extremely common data preprocessing task to transform input categorical features in one-in-k binary encodings for using in classification or prediction tasks (e.g. logistic regression with mixed numerical and text features). Scikit-learn offers powerful yet simple methods to accomplish this. They operate directly on Pandas dataframe or Numpy arrays thereby freeing the user to write any special map/apply function for these transformations.
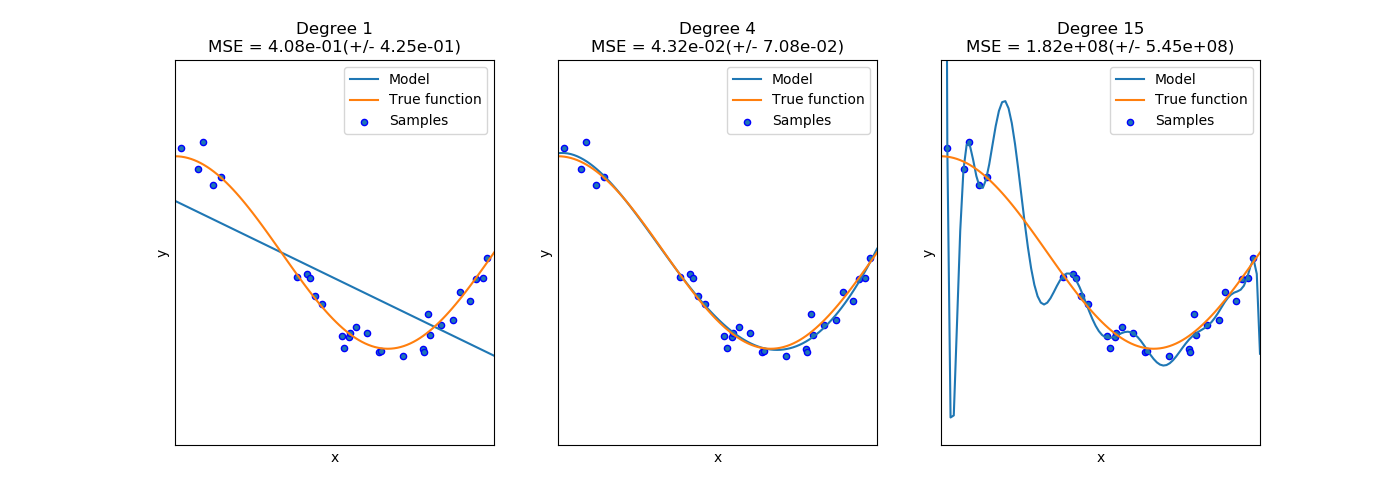
Polynomial feature generation : For countless regression modeling tasks, often it is useful to add complexity to the model by considering nonlinear features of the input data. A simple and common method to use is polynomial features, which can get features’ high-order and interaction terms. Scikit-learn has a ready-made function to generate such higher-order cross-terms from a given feature set and user’s choice of highest degree of polynomial.
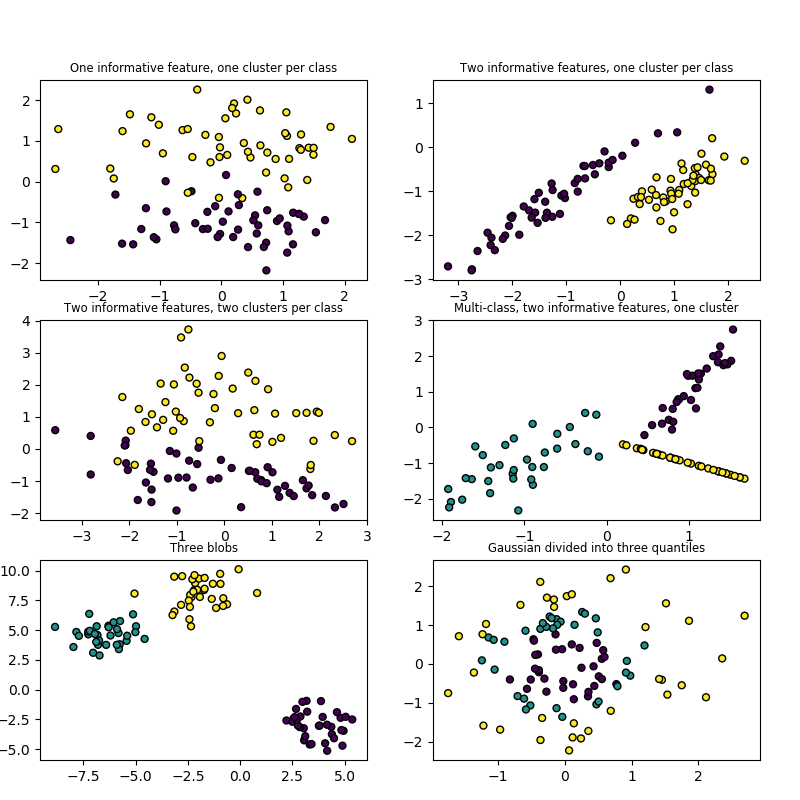
Dataset generators : Scikit-learn includes various random sample generators that can be used to build artificial datasets of controlled size and complexity. It has functions for classification, clustering, regression, matrix decomposition, and manifold testing.
Practicing Interactive Machine Learning
Project Jupyter was born out of the IPython Project in 2014 and evolved rapidly to support interactive data science and scientific computing across all major programming languages. There is no doubt that it has left one of the biggest degrees of impact on how a data scientist can quickly test and prototype his/her idea and showcase the work to peers and open-source community.
However, l earning and experimenting with data become truly immersive when user can interactively control the parameters of the model and see the effect (almost) real-time. Most of the common rendering in Jupyter are static.
But you want more control, you want to change variables at the simple swipe of your mouse, not by writing a for-loop. What should you do? You can use IPython widget.
Widgets are eventful python objects that have a representation in the browser, often as a control like a slider, text box, etc., through a front-end (HTML/JavaScript) rendering channel.
In this article, I demonstrate a simple curve fitting exercise using basic widget controls. In a follow-up article, that is extended further in the realm of interactive machine learning techniques.
Deep Learning Frameworks
This article gloss over some essential tips for jump-starting your journey to the fascinating world of machine learning with Python. It does not cover deep learning frameworks like TensorFlow, Keras, or PyTorch as they merit deep discussion about themselves exclusively. You can read some great articles about them here but we may come back later with a dedicated discussion about these amazing frameworks.
Summary
Thanks for reading this article. Machine learning is currently one of the most exciting and promising intellectual fields, with applications ranging from e-commerce to healthcare and virtually everything in between. There are hypes and hyperbole, but there is also solid research and best practices. If properly learned and applied, this field of study can bring immense intellectual and practical rewards to the practitioner and to her/his professional task.
It’s impossible to cover even a small fraction of machine learning topics in the space of one (or ten) articles. But hopefully, the current article has piqued your interest in the field and given you solid pointers on some of the powerful frameworks, already available in the Python ecosystem, to start your machine learning tasks.
If you have any questions or ideas to share, please contact the author at tirthajyoti[AT]gmail.com. Also you can check author’s GitHub repositories for other fun code snippets in Python, R, or MATLAB and machine learning resources. If you are, like me, passionate about machine learning/data science, please feel free to add me on LinkedIn or follow me on Twitter.