SlimNets: An Exploration of Deep Model Compression and Acceleration
Deep neural networks have achieved increasingly accurate results on a wide variety of complex tasks. However, much of this improvement is due to the growing use and availability of computational resources (e.g use of GPUs, more layers, more parameters, etc). Most state-of-the-art deep networks, despite performing well, over-parameterize approximate functions and take a significant amount of time to train. With increased focus on deploying deep neural networks on resource constrained devices like smart phones, there has been a push to evaluate why these models are so resource hungry and how they can be made more efficient. This work evaluates and compares three distinct methods for deep model compression and acceleration: weight pruning, low rank factorization, and knowledge distillation. Comparisons on VGG nets trained on CIFAR10 show that each of the models on their own are effective, but that the true power lies in combining them. We show that by combining pruning and knowledge distillation methods we can create a compressed network 85 times smaller than the original, all while retaining 96% of the original model’s accuracy.
Mod-DeepESN: Modular Deep Echo State Network
Neuro-inspired recurrent neural network algorithms, such as echo state networks, are computationally lightweight and thereby map well onto untethered devices. The baseline echo state network algorithms are shown to be efficient in solving small-scale spatio-temporal problems. However, they underperform for complex tasks that are characterized by multi-scale structures. In this research, an intrinsic plasticity-infused modular deep echo state network architecture is proposed to solve complex and multiple timescale temporal tasks. It outperforms state-of-the-art for time series prediction tasks.
Fusion Subspace Clustering: Full and Incomplete Data
Modern inference and learning often hinge on identifying low-dimensional structures that approximate large scale data. Subspace clustering achieves this through a union of linear subspaces. However, in contemporary applications data is increasingly often incomplete, rendering standard (full-data) methods inapplicable. On the other hand, existing incomplete-data methods present major drawbacks, like lifting an already high-dimensional problem, or requiring a super polynomial number of samples. Motivated by this, we introduce a new subspace clustering algorithm inspired by fusion penalties. The main idea is to permanently assign each datum to a subspace of its own, and minimize the distance between the subspaces of all data, so that subspaces of the same cluster get fused together. Our approach is entirely new to both, full and missing data, and unlike other methods, it directly allows noise, it requires no liftings, it allows low, high, and even full-rank data, it approaches optimal (information-theoretic) sampling rates, and it does not rely on other methods such as low-rank matrix completion to handle missing data. Furthermore, our extensive experiments on both real and synthetic data show that our approach performs comparably to the state-of-the-art with complete data, and dramatically better if data is missing.
Bayesian Classification of Multiclass Functional Data
We propose a Bayesian approach to estimating parameters in multiclass functional models. Unordered multinomial probit, ordered multinomial probit and multinomial logistic models are considered. We use finite random series priors based on a suitable basis such as B-splines in these three multinomial models, and classify the functional data using the Bayes rule. We average over models based on the marginal likelihood estimated from Markov Chain Monte Carlo (MCMC) output. Posterior contraction rates for the three multinomial models are computed. We also consider Bayesian linear and quadratic discriminant analyses on the multivariate data obtained by applying a functional principal component technique on the original functional data. A simulation study is conducted to compare these methods on different types of data. We also apply these methods to a phoneme dataset.
Reconstructing Strings from Substrings: Optimal Randomized and Average-Case Algorithms


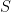
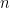
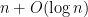

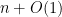
corr2D – Implementation of Two-Dimensional Correlation Analysis in R
In the package corr2D two-dimensional correlation analysis is implemented in R. This paper describes how two-dimensional correlation analysis is done in the package and how the mathematical equations are translated into R code. The paper features a simple tutorial with executable code for beginners, insight into at the calculations done before the correlation analysis, a detailed look at the parallelization of the fast Fourier transformation based correlation analysis and a speed test of the calculation. The package corr2D offers the possibility to preprocess, correlate and postprocess spectroscopic data using exclusively the R language. Thus, corr2D is a welcome addition to the toolbox of spectroscopists and makes two-dimensional correlation analysis more accessible and transparent.
RecoGym: A Reinforcement Learning Environment for the problem of Product Recommendation in Online Advertising
Recommender Systems are becoming ubiquitous in many settings and take many forms, from product recommendation in e-commerce stores, to query suggestions in search engines, to friend recommendation in social networks. Current research directions which are largely based upon supervised learning from historical data appear to be showing diminishing returns with a lot of practitioners report a discrepancy between improvements in offline metrics for supervised learning and the online performance of the newly proposed models. One possible reason is that we are using the wrong paradigm: when looking at the long-term cycle of collecting historical performance data, creating a new version of the recommendation model, A/B testing it and then rolling it out. We see that there a lot of commonalities with the reinforcement learning (RL) setup, where the agent observes the environment and acts upon it in order to change its state towards better states (states with higher rewards). To this end we introduce RecoGym, an RL environment for recommendation, which is defined by a model of user traffic patterns on e-commerce and the users response to recommendations on the publisher websites. We believe that this is an important step forward for the field of recommendation systems research, that could open up an avenue of collaboration between the recommender systems and reinforcement learning communities and lead to better alignment between offline and online performance metrics.
High-dimensional regression in practice: an empirical study of finite-sample prediction, variable selection and ranking
Penalized likelihood methods are widely used for high-dimensional regression. Although many methods have been proposed and the associated theory is now well-developed, the relative efficacy of different methods in finite-sample settings, as encountered in practice, remains incompletely understood. There is therefore a need for empirical investigations in this area that can offer practical insight and guidance to users of these methods. In this paper we present a large-scale comparison of penalized regression methods. We distinguish between three related goals: prediction, variable selection and variable ranking. Our results span more than 1,800 data-generating scenarios, allowing us to systematically consider the influence of various factors (sample size, dimensionality, sparsity, signal strength and multicollinearity). We consider several widely-used methods (Lasso, Elastic Net, Ridge Regression, SCAD, the Dantzig Selector as well as Stability Selection). We find considerable variation in performance between methods, with results dependent on details of the data-generating scenario and the specific goal. Our results support a `no panacea’ view, with no unambiguous winner across all scenarios, even in this restricted setting where all data align well with the assumptions underlying the methods. Lasso is well-behaved, performing competitively in many scenarios, while SCAD is highly variable. Substantial benefits from a Ridge-penalty are only seen in the most challenging scenarios with strong multi-collinearity. The results are supported by semi-synthetic analyzes using gene expression data from cancer samples. Our empirical results complement existing theory and provide a resource to compare methods across a range of scenarios and metrics.
The Quest for the Golden Activation Function
Deep Neural Networks have been shown to be beneficial for a variety of tasks, in particular allowing for end-to-end learning and reducing the requirement for manual design decisions. However, still many parameters have to be chosen in advance, also raising the need to optimize them. One important, but often ignored system parameter is the selection of a proper activation function. Thus, in this paper we target to demonstrate the importance of activation functions in general and show that for different tasks different activation functions might be meaningful. To avoid the manual design or selection of activation functions, we build on the idea of genetic algorithms to learn the best activation function for a given task. In addition, we introduce two new activation functions, ELiSH and HardELiSH, which can easily be incorporated in our framework. In this way, we demonstrate for three different image classification benchmarks that different activation functions are learned, also showing improved results compared to typically used baselines.
Mobile big data analysis with machine learning
This paper investigates to identify the requirement and the development of machine learning-based mobile big data analysis through discussing the insights of challenges in the mobile big data (MBD). Furthermore, it reviews the state-of-the-art applications of data analysis in the area of MBD. Firstly, we introduce the development of MBD. Secondly, the frequently adopted methods of data analysis are reviewed. Three typical applications of MBD analysis, namely wireless channel modeling, human online and offline behavior analysis, and speech recognition in the internet of vehicles, are introduced respectively. Finally, we summarize the main challenges and future development directions of mobile big data analysis.
The Lyapunov Neural Network: Adaptive Stability Certification for Safe Learning of Dynamic Systems
Learning algorithms have shown considerable prowess in simulation by allowing robots to adapt to uncertain environments and improve their performance. However, such algorithms are rarely used in practice on safety-critical systems, since the learned policy typically does not yield any safety guarantees and thus the required exploration may cause physical harm to the robot or its environment. In this paper, we present a method to learn accurate safety certificates for nonlinear, closed-loop dynamic systems. Specifically, we construct a neural network Lyapunov function and a training algorithm that adapts it to the shape of the largest safe region in the state space. The algorithm relies only on knowledge of inputs and outputs of the dynamics, rather than on any specific model structure. We demonstrate our method by learning the safe region of attraction for a simulated inverted pendulum. Furthermore, we discuss how our method can be used in safe learning algorithms together with statistical models of dynamic systems.
• Young-Capelli bitableaux, Capelli immanants in U(gl(n)) and the Okounkov quantum immanants• Detector monitoring with artificial neural networks at the CMS experiment at the CERN Large Hadron Collider• Nonuniform Markov geometric measures• Code-Switching Detection with Data-Augmented Acoustic and Language Models• Some large polyominoe’s perimeter: a stochastic analysis• The impact of imbalanced training data on machine learning for author name disambiguation• Optimal control of a Vlasov-Poisson plasma by an external magnetic field• The ISRS GN Model, an Efficient Tool in Modeling Ultra-Wideband Transmission in Point-to-Point and Network Scenarios• Analyzing Diffusion and Flow-driven Instability using Semidefinite Programming• Towards fully automated protein structure elucidation with NMR spectroscopy• Traj2User: exploiting embeddings for computing similarity of users mobile behavior• Parameter estimation for optimal path planning in internal transportation• Prediction of Optimal Drug Schedules for Controlling Autophagy• Perturbation bounds of Markov semigroups on abstract states spaces• The Erdos-Szekeres problem and an induced Ramsey question• Estimation and Control Using Sampling-Based Bayesian Reinforcement Learning• On the sizes of vertex-$k$-maximal $r$-uniform hypergraphs• From Thumbnails to Summaries – A single Deep Neural Network to Rule Them All• Compositional (In)Finite Abstractions for Large-Scale Interconnected Stochastic Systems• Developing Robot Driver Etiquette Based on Naturalistic Human Driving Behavior• A Multi-channel Network with Image Retrieval for Accurate Brain Tissue Segmentation• Quantum Supremacy Lower Bounds by Entanglement Scaling• From Bloch Oscillations to Many Body Localization in Clean Interacting Systems• Using Machine Learning for Scientific Discovery in Electronic Quantum Matter Visualization Experiments• Space Complexity of Implementing Large Shared Registers• Describing Quasi-Graphic Matroids• Deep Reinforcement Learning for Distributed Dynamic Power Allocation in Wireless Networks• Low-Latency Neural Speech Translation• Semantic Classification of 3D Point Clouds with Multiscale Spherical Neighborhoods• Order batching for picker routing using a distance approximation• A Littlewood-Paley description of modelled distributions• Wavelet Sparse Regularization for Manifold-Valued Data• Neural Arithmetic Logic Units• Composite α-μ Based DSRC Channel Model Using Large Data Set of RSSI Measurements• Squeezed Complexes• A Learning-Based Framework for Two-Dimensional Vehicle Maneuver Prediction over V2V Networks• Orthogonal Time Frequency Space Modulation• Cooperative Group Optimization with Ants (CGO-AS): Leverage Optimization with Mixed Individual and Social Learning• Inference of Users Demographic Attributes based on Homophily in Communication Networks• Open Category Detection with PAC Guarantees• Optimal control of the mean field game equilibrium for a pedestrian tourists’ flow model• On nested infinite occupancy scheme in random environment• Tverberg-Type Theorems with Trees and Cycles as (Nerve) Intersection Patterns• Container solutions for HPC Systems: A Case Study of Using Shifter on Blue Waters• Direct Sparse Odometry with Rolling Shutter• Spectral Mixture Kernels with Time and Phase Delay Dependencies• Data Augmentation for Robust Keyword Spotting under Playback Interference• Forest Learning Universal Coding• Jumping champions and prime gaps using information-theoretic tools• All $(96,20,4)$ difference sets and related structures• The Delta square conjecture• Parametric analysis of semidefinite optimization• Weather Classification: A new multi-class dataset, data augmentation approach and comprehensive evaluations of Convolutional Neural Networks• MLCapsule: Guarded Offline Deployment of Machine Learning as a Service• Hybrid Beamforming NOMA for mmWave Communications• Ergodic Theorems for the Shift Action and Pointwise Versions of The Abért–Weiss Theorem• Saccadic Predictive Vision Model with a Fovea• Classification of Building Information Model (BIM) Structures with Deep Learning• Physics-Based Generative Adversarial Models for Image Restoration and Beyond• Recursive Geman-McClure method for implementing second-order Volterra filter• A Nonparametric Bayesian Model for Synthesising Residential Solar Generation and Demand• Mixture Matrix Completion• A Class of Weighted TSPs with Applications• Matrix optimization on universal unitary photonic devices• Induction of Non-Monotonic Logic Programs to Explain Boosted Tree Models Using LIME• A Scan Procedure for Multiple Testing• Sequence Discriminative Training for Deep Learning based Acoustic Keyword Spotting• A golden ratio inequality for vertex degrees of graphs• Object Localization and Size Estimation from RGB-D Images• On the tails of the limiting QuickSort density• Power Allocation Strategies for Secure Spatial Modulation• Multi-threshold Change Plane Model: Estimation Theory and Applications in Subgroup Identification• Robust Tracking with Model Mismatch for Fast and Safe Planning: an SOS Optimization Approach• Energy-Efficiency Gains of Caching for Interference Channels• Almost sure well-posedness for the cubic nonlinear Schrödinger equation in the super-critical regime on $\TTT^d$, $d\geq 3$• Adaptive Temporal Encoding Network for Video Instance-level Human Parsing• Investigating accuracy of pitch-accent annotations in neural network-based speech synthesis and denoising effects• Deep Learning for Radio Resource Allocation in Multi-Cell Networks• On the achievability of blind source separation for high-dimensional nonlinear source mixtures• PCN: Point Completion Network• Winner-Take-All as Basic Probabilistic Inference Unit of Neuronal Circuits• Double Supervised Network with Attention Mechanism for Scene Text Recognition• Memristor-based Synaptic Sampling Machines• Synapse: Synthetic Application Profiler and Emulator• Linguistic Search Optimization for Deep Learning Based LVCSR• Multi-Shot Distributed Transaction Commit (Extended Version)• Triangle Estimation using Polylogarithmic Queries• Online Temporal Calibration for Monocular Visual-Inertial Systems• OntoSenseNet: A Verb-Centric Ontological Resource for Indian Languages• Evaluating the Readability of Force Directed Graph Layouts: A Deep Learning Approach• A diagonal PRP-type projection method for convex constrained nonlinear monotone equations• Improved Quantum Information Set Decoding• On the Harborth constant of $C_3 \oplus C_{3n}$• Rational Optimization for Nonlinear Reconstruction with Approximate $\ell_0$ Penalization• Inlining External Sources in Answer Set Programs• Higher Order Langevin Monte Carlo Algorithm• Removal of the points that do not support an E-optimal experimental design• Approximate Probabilistic Neural Networks with Gated Threshold Logic• Limit theorems for some skew products with mixing base maps• Dynamic Adaptation on Non-Stationary Visual Domains• Binary Weighted Memristive Analog Deep Neural Network for Near-Sensor Edge Processing• Numerical Asymptotic Results in Game Theory Using Sergeyev’s Infinity Computing• Deeply Self-Supervising Edge-to-Contour Neural Network Applied to Liver Segmentation• Online Aggregation of Unbounded Losses Using Shifting Experts with Confidence• The LANER: optical networks as complex lasers• Similarity forces and recurrent components in human face-to-face interaction networks• Attentional Aggregation of Deep Feature Sets for Multi-view 3D Reconstruction• Tempered Fractional Poisson Processes and Fractional Equations with Z-Transform• Sparse and Dense Data with CNNs: Depth Completion and Semantic Segmentation• Hidden thermal structure in Fock space• Fleet Sizing in Vehicle Sharing Systems with Service Quality Guarantees• A note on Metropolis-Hasting for sampling across mixed spaces• Asymptotically and computationally efficient tensorial JADE• Weakly Supervised Localisation for Fetal Ultrasound Images• Analysis of the Threshold for the Displacement to the Power of Random Sensors• Negatively Reinforced Balanced Urn Schemes• Identifying exogenous and endogenous activity in social media• Classification of EEG Signal based on non-Gaussian Neutral Vector• Dirichlet Mixture Model based VQ Performance Prediction for Line Spectral Frequency• Filtered Stochastic Galerkin Methods For Hyperbolic Equations• Benefit of Self-Stabilizing Protocols in Eventually Consistent Key-Value Stores: A Case Study• Finding perfect matchings in random cubic graphs in linear time• A Systematic Comparison of Dynamic Load Balancing Algorithms for Massively Parallel Rigid Particle Dynamics• Efficient Bayesian Inference of Sigmoidal Gaussian Cox Processes• Algorithms for Noisy Broadcast under Erasures• Esthetic Numbers and Lifting Restrictions on the Analysis of Summatory Functions of Regular Sequences• RGB Video Based Tennis Action Recognition Using a Deep Weighted Long Short-Term Memory• Cycle partitions of regular graphs• Energy-Efficient Multi-Cell Multigroup Multicasting with Joint Beamforming and Antenna Selection• Geometry-Based Multiple Camera Head Detection in Dense Crowds• Maximum Likelihood based Direct Position Estimation for Mobile Stations in Dense Multipath• A Topological Obstruction to Almost Global Synchronization on Riemannian Manifolds• Lean tree-cut decompositions: obstructions and algorithms• Optimal model points portfolio in Life Insurance• Normalization Before Shaking Toward Learning Symmetrically Distributed Representation Without Margin in Speech Emotion Recognition• An Adaptive Partial Sensitivity Updating Scheme for Fast Nonlinear Model Predictive Control• Supervised classification for object identification in urban areas using satellite imagery• Stretched Exponential Relaxation• Chaotic temperature and bond dependence of four-dimensional Gaussian spin glasses with partial thermal boundary conditions• Semi-blind source separation with multichannel variational autoencoder• Parallelization of the FFT on SO(3)• BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation• Last passage percolation in an exponential environment with discontinuous rates• Algorithmic thresholds for tensor PCA• Cyberbullying Detection — Technical Report 2/2018, Department of Computer Science AGH, University of Science and Technology• Learning Actionable Representations from Visual Observations• Bounding flows for spherical spin glass dynamics• Estimating Passenger Loading on Train Cars Using Accelerometer• Machine Learning of Space-Fractional Differential Equations• Mass equidistribution for random polynomials• Streaming Kernel PCA with $\tilde{O}(\sqrt{n})$ Random Features• Inferring Parameters Through Inverse Multiobjective Optimization• On Finite Monoids over Nonnegative Integer Matrices and Short Killing Words• Data-driven nonsmooth optimization• Diverse Image-to-Image Translation via Disentangled Representations• Distance Magic Index One Graphs
Like this:
Like Loading…
Related