Introduction
Zacco asked in Stan discourse whether leave-one-out (LOO) cross-validation is valid for phylogenetic models. He also referred to Dan’s excellent blog post which mentioned iid assumption. Instead of iid it would be better to talk about exchangeability assumption, but I (Aki) got a bit lost in my discourse answer (so don’t bother to go read it). I started to write this blog post to clear my thoughts and extend what I’ve said before, and hopefully produce a better answer.
TL;DR
The question is when leave-one-out cross-validation or leave-one-group-out cross-validation is valid for model comparison. The short answer is that we need to think about what is the joint data generating mechanism, what is exchangeable, and what is the prediction task. LOO can be valid or invalid, for example, for time-series and phylogenetic modelling depending on the prediction task. Everything said about LOO applies also to AIC, DIC, WAIC, etc.
iid and exchangeability
Dan wrote
To see this, we need to understand what the LOO methods are using to select models. It is the ability to predict a new data point coming from the (assumed iid) data generating mechanism. If two models asymptotically produce the same one point predictive distribution, then the LOO-elpd criterion will not be able to separate them.
This is well put, although iid is stronger than necessary assumption. It would be better to assume exchangeability which doesn’t imply independence. Exchangeability assumption thus extends in which cases LOO is applicable. The details of difference between iid and exchangeability is not that important for this post, but I recommend interested readers to see Chapter 5 in BDA3. Instead of iid vs exchangeability, I’ll focus here on prediction tasks and data generating mechanisms.
Basics of LOO
LOO is easiest to understand in the case where we have a joint distribution 
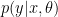

We are interested in predicting a new data point coming from the data generating mechanism

When we don’t know 

We would like to evaluate how good this predictive distribution is by comparing it to observed 



The usual forgotten assumption is that 
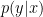
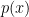





then the posterior factorizes as

We can analyze the second factor by itself with no loss of information.
For the predictive performance estimate we however need to know how the future 

Data generating mechanisms
Dan wrote
LOO-elpd can fail catastrophically and silently when the data cannot be assumed to be iid. A simple case where this happens is time-series data, where you should leave out the whole future instead.
This is a quite common way to describe the problem, but I hope this can be more clear by discussing more about the data generating mechanisms.
Sometimes 


If
LOO can be used in case of fixed 

Time series
We could assume future be fixed, chosen by design, or deterministic, but so that 

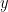

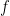



We can also have time series, where we don’t want to predict for the future and thus the focus is only on the observed time points
LOO-elpd can fail or doesn’t fail for time-series depending on your prediction task. LOO is not great if you want to estimate the performance of extrapolation to future, but having a time series doesn’t automatically invalidate the use of cross-validation.
Multilevel data and models
Dan wrote
Or when your data has multilevel structure, where you really should leave out whole strata.
For multilevel structure, we can start from a simple example with individual observations from 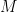

where 



Sometimes we assume we haven’t observed all groups and want to make predictions for 

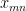
On the other hand, if we poll people in all states of USA, there will be no new states (at least in near future) and some or all
Phylogenetic models and non-factorizable priors
Zacco’s discourse question was related to phylogenetic models.
Wikipedia says
In biology, phylogenetics is the study of the evolutionary history and relationships among individuals or groups of organisms (e.g. species, or populations). These relationships are discovered through phylogenetic inference methods that evaluate observed heritable traits, such as DNA sequences or morphology under a model of evolution of these traits. The result of these analyses is a phylogeny (also known as a phylogenetic tree) – a diagrammatic hypothesis about the history of the evolutionary relationships of a group of organisms. The tips of a phylogenetic tree can be living organisms or fossils, and represent the “end”, or the present, in an evolutionary lineage.
This is a similar to above hierarchical model, but now we assume a non-factorizable prior for theta

and if we have a model for
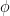

Again LOO is valid, if we focus on new observations in the current groups (e.g. observed species). Alternatively we could consider prediction for new individuals in a new group (e.g. species) and use leave-one-group-out cross-validation. I would assume we might have extra information about some
Prediction in scientific inference
Zacco wrote also
In general, with a phylogenetics model there is only very rarely interest in predicting new data points (ie. unsampled species). This is not to say that predicting these things would not be interesting, just that in the traditions of this field it is not commonly done.
It seems quite common in many fields to have a desire to have some quantity to report as an assessment of how good the model is, but not to consider whether that model would generalize to new observations. The observations are really the only thing we have observed and something we might observe more in the future. Only in toy problems, we might be able to observe also usually unknown model structure and parameters. All model selection methods are inherently connected to the observations, and instead of thinking the model assessment methods as black boxes (cough information criteria cough) it’s useful to think how the model can help us to predict something.
In hierarchical models there are also different parts we can focus, and the depending on the focus, benefit of some parts can sometimes be hidden beyond benefits of other parts. For example, in a simple hierarchical model described above, if we have a plenty of individual observations in each group, then the hierarchical prior does have only weak effect if we leave one observation out and LOO is then assessing mostly the lowest level model part 
Or spatial data, where you should leave out large-enough spatial regions that the point you are predicting is effectively independent of all of the points that remain in the data set.
This would be sensible if we assume that future locations are spatially disconnected from the current locations, or if the focus is specifically in non-spatial model part
Information criteria
Zacco wrote
My general impression from your 2017 paper is that WAIC has fewer issues with exchangeability.
It’s unfortunate that we didn’t make it more clear in that paper. I naïvely trusted too much that people would read also the cited theoretical 87 pages long paper (Vehtari & Ojanen, 2012), but I now do understand that some repetition is needed. Akaike’s (1974) original paper made the clear connection to the prediction task of predicting 
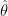
Unfortunately most of the time, information criteria are presented as fit + complexity penalty without any reference to the prediction task, assumptions about exchangeability, data generating mechanism or which part of the model is in the focus. This, combined with the difficult to interpret unit of the resulting quantity, has lead to the fact that information criteria are used as black box measure. As the assumptions are hidden, people think they are always valid (if you already forgot: WAIC and LOO have the same assumptions).
I prefer LOO over WAIC because of better diagnostics and better accuracy in difficult cases (see, e.g., Vehtari, Gelman, Gabry, 2017; -step-ahead cross-validation.
Bonus
In our paper Using Stacking to Average Bayesian Predictive Distributions we used LOO, but we can do Bayesian stacking also with other forms of cross-validation like leave-one-group-out or