We are excited to share the latest report and prototype from our machine intelligence R team: Multi-Task Learning.

Wax on.. face off!
When humans learn new tasks, we take advantage of knowledge we’ve gained from learning, or having learned, related tasks. Take the 1984 movie Karate Kid, where Mr. Miyagi takes on Daniel as his martial arts student. He begins Daniel’s training by having him complete various lengthy menial chores, from waxing cars to sanding floors. When Daniel expresses frustration, Mr. Miyagi reveals that these chores, by training his muscle memory, will help Daniel master martial arts blocks. This fictional example is a great illustration of how humans draw on mastery of related tasks when learning new tasks.
Machines struggle to take advantage of such task relationships. To date, most machine learning algorithms are trained to master one—and only one—task. Because such single-task-trained algorithms only know one task, they do not, and cannot, benefit from the relationships between tasks.
Multi-task learning is an alternative approach to training machine learning algorithms that allows machines to master more than one task; machines gain the ability to benefit from task relationships. Machine learning becomes, a little bit more, like human learning - capable of taking on more complex challenges involving richer representations of reality.
The Benefits of Multi-Task Learning
Newsie, the prototype that accompanies this report, classifies news articles
into categories (e.g., news, sports, entertainment). It was trained using
multi-task learning to correctly classify buttoned-up broadsheet articles
(Task 1) and more sensationalist tabloid ones (Task 2).
Newsie’s article view shows how the model arrives at the classification on a word-by-word level. From surrounding sentences to place of publication, context changes word meaning. Enabled by multi-task learning, Newsie provides users with a window into the differences in coverage and language use across the buttoned-up and sensationalist press; it puts current news into perspective.
The ability to perform a fine-grained analysis of the news is just one way of using the emerging capabilities of multi-task learning. Our report and prototype is valuable for anyone looking for better solutions to complex classification problems, efficient model performance, reduced model maintenance, or the ability to train one model on several different, related sets of data (as we did for Newsie): multi-task learning has many benefits, some of them quite subtle. To inspire future applications, in a recent post, we reviewed the successes of multi-task learning across a range of applications and industries. From healthcare and finance to robotics and agriculture, multi-task learning has the potential to take classification to the next level.
Multi-Task Learning, Why Now?
Like many concepts in machine learning, multi-task learning is not new; Rich Caruana’s review article from 1997 (!) remains one of the best introductions to the topic. Instead, multi-task learning is newly exciting.
Multi-task learning is an approach to training machines, not an algorithm. From decision trees and random forests to neural networks, we can train these algorithms using multi-task learning. But, simpler algorithms, such as decision trees and random forests, require strongly related task to reap the benefits of multi-task learning; they lack the capacity to benefit from complex relationships between loosely related tasks. By contrast, neural networks can learn complex relationships in data, including complex relationships between (loosely related) tasks. We explore different architectures for multi-task neural networks highlighting the value of recent technical innovations, such as adversarial learning, popularized by Generative Adversarial Networks, and skip connections, used to train very deep networks, for multi-task networks. Neural networks make multi-task learning newly exciting.
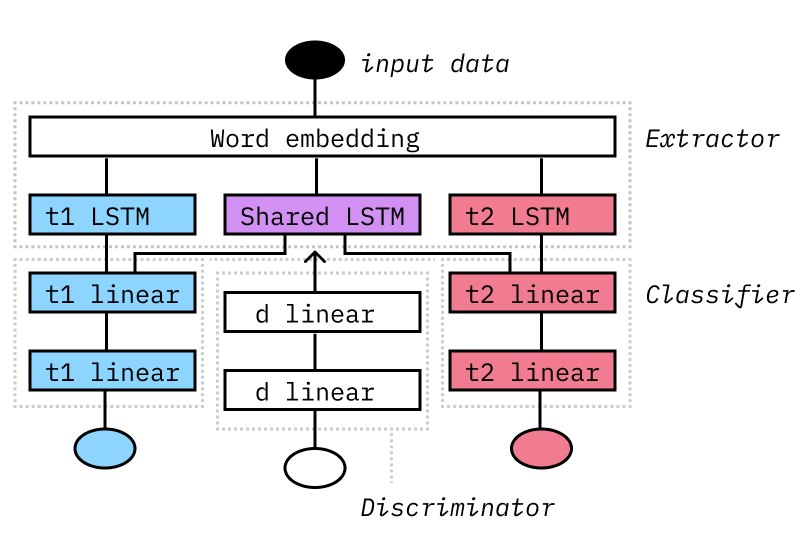
Combined with multi-task learning, adversarial learning allows us to learn task-agnostic representation, representations that support all tasks and yet contain no task-specific information (here, the shared LSTM).
We demonstrate how current, modular deep learning framework simplify the task of architecting a multi-task neural network. Multi-task learning not only offers better solutions for complex problems, it has become easier to implement, too.
Hear us speak about multi-task learning:
Or listen to a talk recorded at RAAIS (Research & Applied AI Summit).
For an in-depth introduction, we recommend a recording of our public webinar on this topic.
Interested in accessing the report? Register here to learn more about Cloudera Fast Forward Labs Advising & Research.