Image classification and object detection in images are hot topics these days, thanks to a combination of improvements in algorithms, datasets, frameworks, and hardware. These improvements democratized the technology and gave us the ingredients for creating our own solution for image classification.
Object detection in images is one of the most important features of applications that do these activities, as shown in the image following:
-
People pathing and object tracking
-
Alerts for product repositioning in physical shops
-
Visual search (searching using an image as input)
The state-of-the-art technologies for image classification and object detection are based on deep learning (DL). DL is a subarea of machine learning (ML) that is focused on algorithms for handling neural networks (NN) with many layers, or deep neural networks. ML, in turn, is a subarea of artificial intelligence (AI), a computer-science discipline.

Although anyone can access these technologies, it’s still hard to put the pieces together in an end-to-end solution that supports a real business process. Amazon Rekognition might be your first choice, given it is a ready to use service that offers a simple API that provides highly accurate facial analysis and facial recognition on your images and videos. Also, you can detect, analyze, and compare faces for a wide variety of user verification, people counting, and public safety use cases and more. Take a look on the Amazon Rekognition documentation and see how easy is to add all these features to you application with simple API calls.
However, if your business challenge requires a custom Image Classification, you’ll need a platform that supports the whole pipeline for creating your Machine Learning model. That’s what Amazon SageMaker was made for. Amazon SageMaker is a fully managed service that supports all of the steps of a ML model’s development: data exploration and building, training, and deploying ML models. With Amazon SageMaker, you can pick and use any of the built-in algorithms, reducing the time to market and the development cost. For more information, see Using Built-in Algorithms with Amazon SageMaker.
Creating a custom image classifier
Your goal in this blog post is to create an image classifier for identifying clothing pieces and accessories. You have several images of these items, and we want a model that can look at them and say (predict) what object each image contains. Amazon SageMaker already has a built-in image classification algorithm. With it, you just need to prepare your dataset (the image collection and the respective labels for each object) and start training your model.
You’ll use a public dataset called Fashion-MNIST, a new image dataset for benchmarking ML algorithms. The dataset consists of a training set of 60,000 examples and a test set of 10,000 examples. Each example is a 28×28 grayscale image associated with a label or class. The dataset has 10 classes: T-shirt or top, trouser, pullover, dress, coat, sandal, shirt, sneaker, bag, and ankle boot. The following image shows a sample of the dataset.

You have the dataset and Amazon SageMaker for helping you train the fashion predictive model. But what computational resources do you need, and how long it will take to deploy the model in production?
An instance like a p2.xlarge comes with NVIDIA Tesla K80 GPU, which has 12 GB of VRAM. GPUs are great for DL, whose training algorithms execute matrix operations like sums and multiplications. A GPU can execute these operations much faster than a CPU since GPUs have multiple cores specialized for parallel tasks. Tesla K80 training a Resnet152 (we’ll talk about that soon) can achieve about 20 images/second, as shown in the following performance graph.
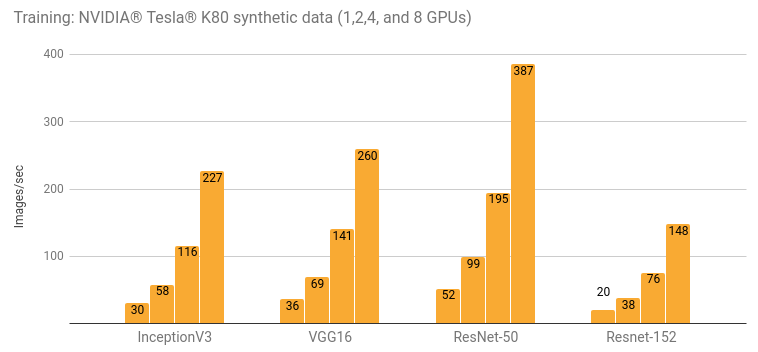
Let’s suppose that you’re training your model with a dataset of 1M images and that you’ll need 100 epochs (or a single pass on the dataset by the training algorithm) to reach your target level of accuracy of 91%. With this setup, it would take about 14 hours per epoch or 58 days in total to complete the training.
Can you do better? Sure! How?
-
Use a better GPU like NVIDIA Tesla V100 by changing the instance type from P2 to P3. Tesla V100 is 14 times faster than a K80. This upgrade can reduce the training time significantly.
-
Use a P2 or P3 instance with more than one GPU. For example, a 16xlarge instance has eight V100 GPUs. You could divide your training workload by eight, proportionally reducing the time to market.
-
Launch more than one training instance. Suppose that you have a huge dataset for training your model, and an instance with 8 GPUs is still taking more time than you can afford. You can tell Amazon SageMaker to execute a training job in two or more instances by setting the train_instance_count parameter of the tensorflow.TensorFlow class. Not only can you can parallelize your job inside an instance while distributing the load through several GPUs, but you can count on a farm of GPUs spread across multiple instances. For more information, see Step 2: Train a Model on Amazon SageMaker Using TensorFlow Custom Code.
-
Apply a technique called transfer learning. Transfer learning uses a model that has already consumed several hours of training. You can customize it and retrain it to adapt it to your needs.
As you can see, you can configure Amazon SageMaker to provide an environment flexible enough to support your day-to-day ML pipeline scenario.
Understanding transfer learning
Before we move on, let’s look at Resnet, a NN topology that can achieve a high accuracy in image classification. It won the 2015 ImageNet Large Scale Visual Recognition Challenge for best object classifier, and it’s one of the most commonly used NNs for computer vision problems.
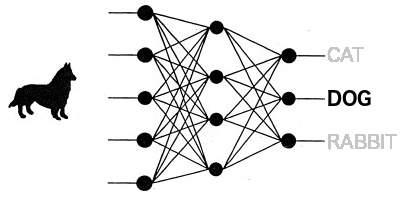
Topologies like Resnet are called a convolutional neural network (CNN) because the network’s input layers execute convolution operations on the input image. A convolution is a mathematical function that emulates the visual cortex of an animal. A CNN has several convolution layers that learn image filters. These filters extract features from the input images such as edges, parts, and bodies. These features are then routed through the hidden or inner layers to the output layer. In the context of image classification, the output layer has one output per category.
Consider a trained neural network capable of classifying a dog, as shown in the following image. The convolution layers extract some features from the dog image, and the rest of the layers route these features to the correct output of the last layer with a high confidence.
Transfer learning is a technique used for reducing the time required for training a new model. Instead of training your model from scratch, you can use a modified pre-trained model and continue training it with your dataset. That’s why it’s called transfer learning: the knowledge learned by one NN is transferring to another NN.
It means, for instance, that if you want a model that can classify cars brand/model/year and you already have a pre-trained model, it makes sense to change it a little bit and retrain it with your own dataset in order to create a new model that will solve this new problem.
The Amazon SageMaker built-in algorithm for image classification is already prepared for transfer learning. You just need to set a given parameter to true, and your model will use this technique.
Creating an end-to-end solution for image classification
You have an idea of which business problems you can solve with what you’ve seen so far, but how do you do it?
You can download the Jupyter notebook used in this hands on to see all the details of this experiment. Here we’ll see only the most relevant parts of this ML development pipeline for your fashion image classifier. The first step is preparing the dataset.
Preparing the dataset
The Amazon SageMaker built-in Image Classification algorithm requires that the dataset be formatted in RecordIO. RecordIO is an efficient file format that feeds images to the NN as a stream. Since Fashion MNIST comes formatted in IDX, you need to extract the raw images to the file system. Then you convert the raw images to RecordIO, and finally you upload them to Amazon Simple Storage Service (Amazon S3).
To prepare the dataset:
-
Download the dataset.
-
Unpack the images from IDX to raw JPEG grayscale images of 28×28 pixels.
-
Organize the images into 10 distinct directories, one per category.
-
Create two .lst files using a RecordIO tool (im2rec). One file is for the training portion of the dataset (70%). The other is for testing (30%).
-
Generate both .rec files from the .lst
-
Copy both .rec files to an Amazon S3 bucket.
For converting the dataset from IDX to raw JPEG files, you need to save the IDX files to a directory called samples and use a Python package called python-mnist.
pip install python-mnist
1 | |
read all the images from the directory fashion_mnist/ and create the .lst files
python $IM2REC –list=1 –recursive=1 –shuffle=1 –test-ratio=0.3 –train-ratio=0.7 fashion_mnist fashion_mnist/
read the .lst files and create the .rec files
python $IM2REC –num-thread=4 –pass-through=1 fashion_mnist_train.lst fashion_mnist python $IM2REC –num-thread=4 –pass-through=1 fashion_mnist_test.lst fashion_mnist
1 | |
import json import numpy as np import boto3 runtime = boto3.Session().client(service_name=’sagemaker-runtime’)
set the object categories array
object_categories = [‘AnkleBoot’,’Bag’,’Coat’,’Dress’,’Pullover’,’Sandal’,’Shirt’,’Sneaker’,’TShirtTop’,’Trouser’]
Load the image bytes
img = open(‘test_data/item1_thumb.jpg’, ‘rb’).read()
Call your model for predicting which object appears in this image.
response = runtime.invoke_endpoint( EndpointName=endpoint_name, ContentType=’application/x-image’, Body=bytearray(img) )
read the prediction result and parse the json
result = response[‘Body’].read() result = json.loads(result)
which category has the highest confidence?
pred_label_id = np.argmax(result)
print( “%s (%f)” % (object_categories[pred_label_id], result[pred_label_id] ) )
1 | |
Shirt (0.794700) TShirtTop (0.999502) AnkleBoot (0.999889) Sneaker (0.999952) Bag (0.795328)
1 | |
{ “Version”: “2012-10-17”, “Statement”: [ { “Sid”: “VisualEditor0”, “Effect”: “Allow”, “Action”: “sagemaker:InvokeEndpoint”, “Resource”: “arn:aws:sagemaker:*:XXXXXXXXXXXX:endpoint/your-endpoint-name-here” } ] } ```
Another way to expose your endpoint to your application users is to encapsulate it in an API using API Gateway. You can delegate to API Gateway all of the security controls that you already defined to your applications and manage your environment the same way.
Conclusion
Amazon SageMaker helps you create a powerful solution for your image-classification needs. You can focus on the creation process and the business problem itself while Amazon SageMaker gives you a flexible and elastic infrastructure for supporting your ML pipeline.
Get a Jupyter notebook and start improving your application and your final users’ experience with a new image classifier.
About the Author
 Samir Araújo is an AI Solutions Architect at AWS. He helps customers creating AI solutions for solving their business challenges, using the AWS platform. He has been working on several AI projects related to Computer Vision, Natural Language Processing, Inference, etc. He likes playing with hardware/programming projects in his free time and he has a particular interest for robotics.
Samir Araújo is an AI Solutions Architect at AWS. He helps customers creating AI solutions for solving their business challenges, using the AWS platform. He has been working on several AI projects related to Computer Vision, Natural Language Processing, Inference, etc. He likes playing with hardware/programming projects in his free time and he has a particular interest for robotics.