Recently I decided to get more serious about my data science skills. So I decided to practice my skills, which led me to Kaggle.
The experience has been very positive.
When I arrived at Kaggle, I was confused about what to do and how everything works. This article will help you to overcome the confusion that I experienced.
I joined the Redefining Cancer Treatment contest because it was for a noble cause. As well, the data was more manageable because it was text based.
Where to code
What makes Kaggle great is that you don’t need a cloud server that creates results for you. Kaggle has a feature where you can run scripts and notebooks inside Kaggle for free, as long as they finish executing within an hour. I used Kaggle’s notebooks for many of my submissions, and experimented with many variables.
Overall it was a great experience.
 That new Kernels button is your friend!
That new Kernels button is your friend!
For the contests, you need to use images or have a large corpus of text. And you will need a fast personal computer (PC) or a cloud container. My PC is crappy, so I used Amazon Web Services’ (AWS) c4.2xlarge instance. It was powerful enough for the text and costed only $0.40 per hour. I also had a free $150 credit from the GitHub student developer pack, so I didn’t need to worry about the cost.
Later when I took part in the Dog Breed Identification playground contest, I worked a lot with images, so I had to upgrade my instance to g2.2xlarge. It costed $0.65 per hour, but it had graphics processing unit (GPU) power, so that it could compute thousands of images in just a few minutes.
The instance g2.2xlarge was still not large enough to hold all of the data I worked with, so I cached the intermediate data as files and deleted the data from RAM. I did this by using del <variable name> to avoid ResourceExhaustionError or MemoryError . Both were equally disheartening.
How to get started with Kaggle competitions
It’s not as scary as it sounds. The Discussion and Kernel tabs for every contest are a marvellous way to get started. A few days after the start of a contest, you will see several starter kernels appear in the Kernel tab. You can use these to get started.
Instead of handling the loading and creation of submissions, just deal with the manipulation of data. I prefer the XGBoost starter kernels. Their codes are always short and are ranked high on leaderboards.
Extreme Gradient Boosting (XGBoost) is based on the decision tree model. It is very fast and amazingly accurate, even on default variables. For large data I prefer to use Light Gradient Boosting Machine (LightGBM). It is similar in concept to the XGBoost, but approaches the problem a bit differently. There is a catch, it is not as accurate. So you can experiment using LightGBM, and when you know it is working great, switch to XGBoost (they have a similar API).
Check the discussions every few days to see if someone has found a new approach. If someone does, use it in your script and test to see if you benefit from it.
How to go up in the leaderboard
So you have your starter code cooked and want to rise higher? There are many possible approaches:
-
Cross validation (CV): Always split the training data into 80% and 20%. That way when you train on 80% of the data, you can manually cross-check with 20% of the data to see if you have a good model. To quote the discussion board on Kaggle, “Always trust your CV more than the leaderboard.� The leaderboard has 50% to 70% of actual test set, so you cannot be sure about the quality of your solution based on the percentages. Sometimes your model might be great overall, but bad on the data, specifically in the public test set.
-
Cache your intermediate data: You will do less work next time by doing this. Focus on a specific step rather than running everything from the start. Almost all python objects can be
pickled, but for efficiency, always use.save()and.load()functions of the library you are using for your code. -
Use GridSearchCV : It is a great module that allows you to provide a set of variable values. It will try all possible combinations until it finds the optimal set of values. This is a great automation for optimization. A finely tuned XGBoost can beat a generic neural network in many problems.
-
Use the model appropriate to the problem: Using a knife in a gunfight is not a good idea. I have a simple approach: For text data, use XGBoost or Keras LSTM. For image data, use Pre-trained Keras model (I use Inception most of the time) with some custom bottleneck layers.
-
Combine models: Using a kitchen knife for everything is not enough. You need a Swiss army knife. Try combining various models to get even more accurate information. For example, Inception plus the Xceptionmodel work great for image data. Combined models take a lot of RAM, which g2.2xlarge might not provide. So avoid them unless you really want to get that accuracy boost.
-
Feature extraction: Make the work easier for the model by extracting multiple simpler features from one feature, or combining several features into one feature. For example, you can extract the country and area code from a phone number. Models are not very intelligent, they are just algorithms that fit data. So make sure that the data is appropriate for optimal fit.
What else to do on Kaggle
Other than being a competition platform for data science, Kaggle is also a platform for exploring datasets and creating kernels that explore insights into the data.
So you can choose any dataset out of the top five that appear on the datasets page, and just go with it. The data might be weird, and you might experience difficulty as a beginner. What matters is that you analyze data and make visualizations relate to it, which contributes to your learning.
Which libraries to use for analysis
For visualizations , explore seaborn and matplotlib librariesFor data manipulation, explore NumPy and pandasFor data preprocessing, explore sklearn.preprocessing module
Pandas’ library has some basic plot functions too, and they are extremely convenient.intel_sorted[“Instruction_Set�].value_counts().plot(kind=’pie’)
The above one line of code made a pie chart with “Instruction_Set.� And the best thing is that it still looks pretty.
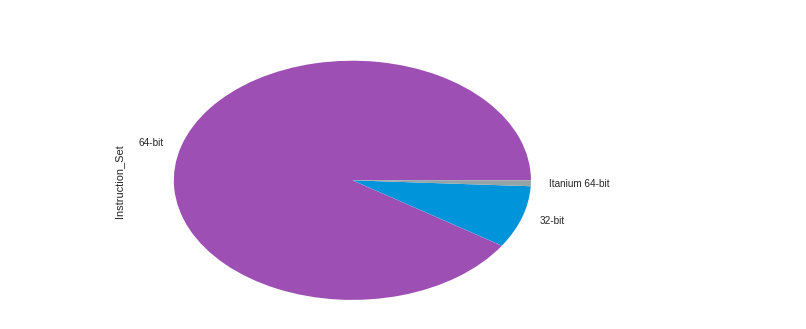 This pie chart shows that Intel has a lot of 64-bit processors
This pie chart shows that Intel has a lot of 64-bit processors
Why do all this
Machine learning is a beautiful field with lots of development going on. Participating in these contests will help you to learn a lot about algorithms and the various approaches to data. I myself learned a lot of these things from Kaggle.
Also, to be able to say, “My AI is in the top 15% for
 *That time when I was in the top 5… at least for a few hours
*That time when I was in the top 5… at least for a few hours  *
*
The graph below represents my kernel’s exploration of the Intel CPU dataset on Kaggle:
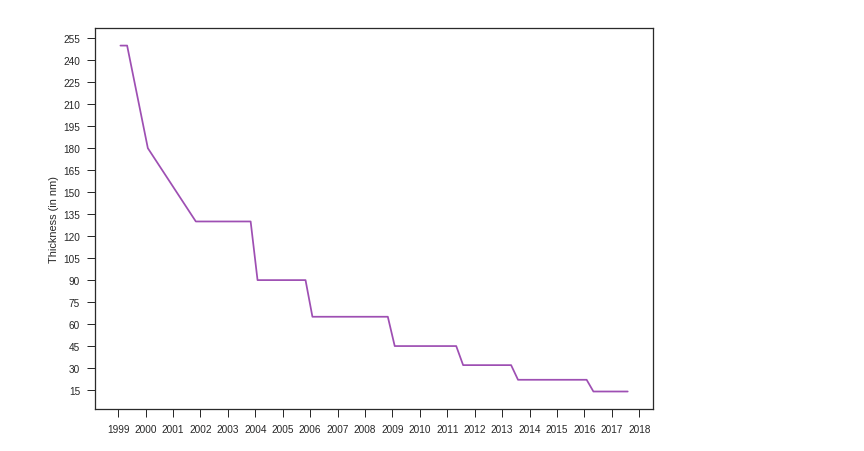 A graph showing the decreasing thickness of a chip
A graph showing the decreasing thickness of a chip
My solution for the Redefining Cancer Treatment contest:
 I ranked number 217 in the contest.
I ranked number 217 in the contest.
That’s all folks.
Thanks for reading. I hope I made you feel more confident about participating in Kaggle’s contests.
See you on the leaderboards.