Sequence labeling tasks attempt to assign a categorical label to each member in the sequence. In natural language processing, where a sequence generally refers to a sentence, examples of sequence labeling include named entity recognition (NER), part-of-speech tagging (POS) and error detection. NER, as the name implies, tries to recognize names in a sentence and classify them into pre-defined labels such as Person and Organization. POS tagging assigns labels such as noun, verb, and adjective to each word, while error detection identifies grammatical errors in sentences. In many of these tasks, the relevant labels in the dataset are very sparse and most of the words contribute very little to the training process. But why let the data go to waste?
A recent paper proposes using multitask learning to make more use of the available data. In addition to assigning labels to each token (or words, loosely), the authors propose a model that also predicts the surrounding words in the dataset. By adding the secondary unsupervised objective, “the model is required to learn more general patterns of semantic and syntactic composition, which can be reused in order to predict individual labels more accurately”.
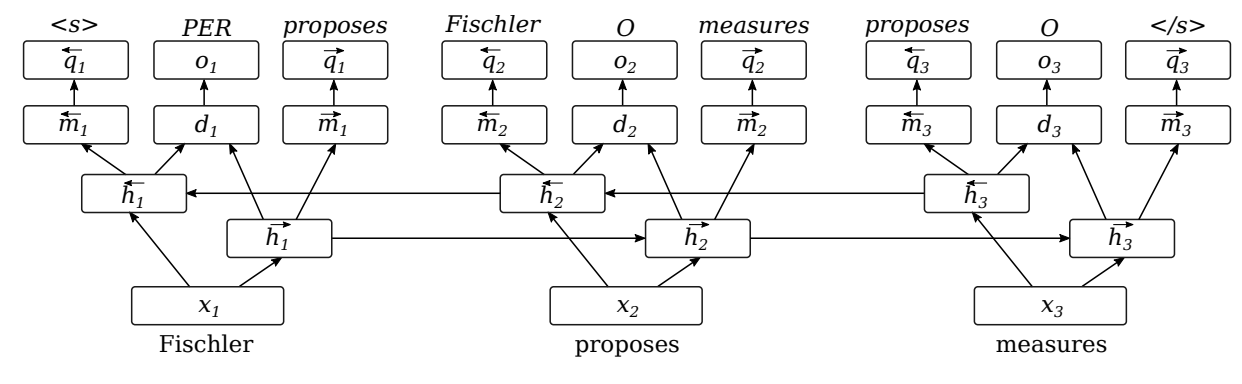
For the sequence modeling neural network, the authors take one sentence as input and use a bidirectional Long Short Term Memory network (LSTM) to assign a label to every token in the sentence. Each sentence is first tokenized and the resulting tokens are mapped into a sequence of word embeddings before being fed into the LSTM. Two LSTM components, moving in opposite directions (forward and backward) through the sentence, are then used for constructing context-dependent representations for every word. The hidden representations from both LSTMs are concatenated in order to obtain a context-specific representation for each word. This concatenated representation is passed through a feed-forward layer, allowing the model to learn features based on both context directions. To predict a label for each token, the authors use either a softmax or conditional random field (CRF) output architecture. Softmax predicts each label independently. CRF, on the other hand, handles dependencies between subsequent labels by looking for the best label sequence.
To predict the surrounding words, the authors cannot use the concatenated (forward and backward) representation because it contains information on both the previous word and next word. Instead, they use the pre-concatenated version. The hidden representation from the forward-moving LSTM is used to predict the next word; the hidden representation from the backward-moving LSTM is used to predict the previous word.
The architecture was evaluated on a range of datasets, covering the tasks of error detection, named entity recognition, chunking, and POS-tagging. Introducing a secondary task resulted in consistent performance improvements on every benchmark. The largest benefit was observed on the task of error detection - perhaps due to the very sparse and unbalanced label distribution in the dataset.