63% of people use Gensim at work, and 48% work for a commercial company. The most popular industries are Media & Advertising, IT and Customer Support. Plus there’s a number of people applying Gensim in Medical, Legal, HR and Fintech.
Unsurprisingly, there’s also big adoption in the research community where users apply Gensim in computer science, the cognitive sciences and humanities, neuroscience, law, finance and accounting (!).
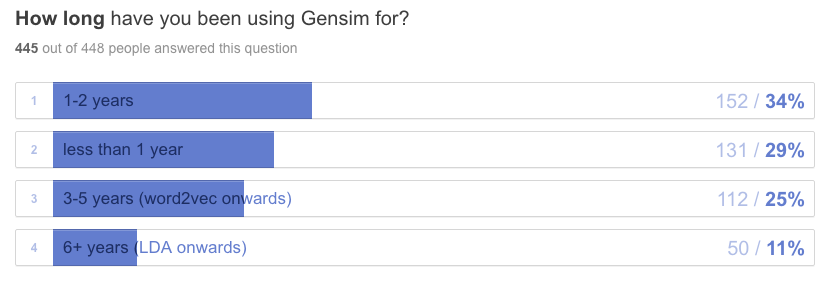
Most people are relative newcomers, having used Gensim for less than 2 years. But there’s also a solid core of veterans: 11% have been using Gensim for more than 6 years!
I always wondered how people keep up with new Gensim features and developments. Recently, we started publishing more descriptive changelog releases on Github (example here), and I’m happy users have gotten used to it already.
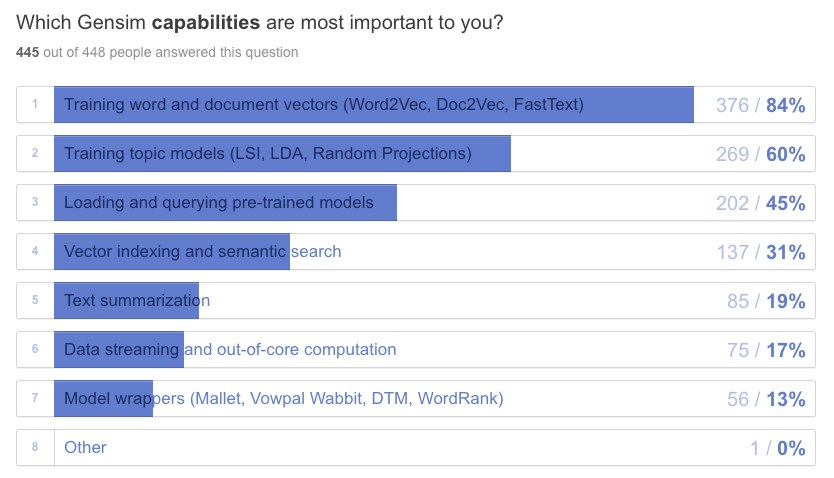
Representation learning is a hot topic in ML right now, and most people are indeed interested in deep learning, embeddings and document/sentence vectors. Unsupervised learning is the core mission of Gensim, so no surprise here. We’ll shift our implementations more from optimized Cython to PyTorch/Tensorflow, for easier-to-read-and-modify models.
I was surprised that data streaming was important to only 17% of respondents. This tells me that people either train their unsupervised models on small in-memory datasets (really?), or we failed to communicate streaming and generators properly. Is streaming and online learning too advanced, do developers know how to do it? If puzzled, read our data streaming tutorial. We need better docs.
Wrappers of 3rd party NLP packages (VowpalWabbit, Sklearn, Mallet…) are used by 13% of people. To be honest, I thought it would be even less: we were planning to retire the wrappers altogether, because they are a headache to maintain (users come to us with 3rd party bugs, grrr).
Where next, Gensim?
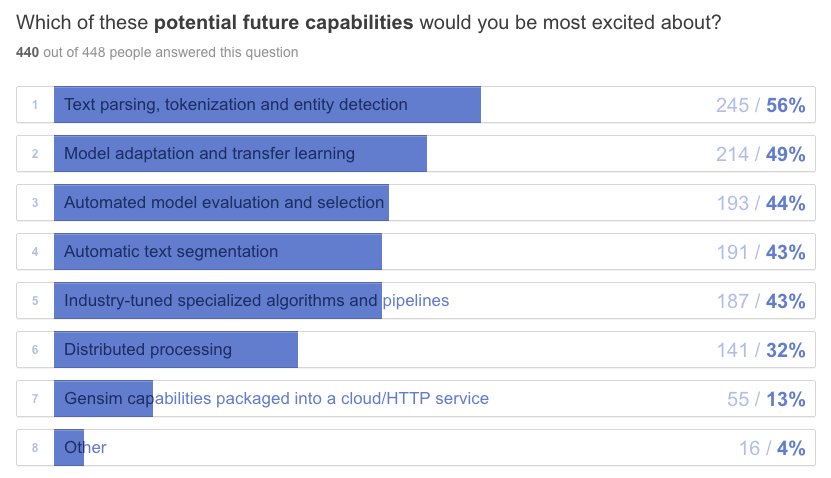
OK, new capabilities. Exciting! This was a tight contest, with people interested in just about everything on the plate.
First, some good news regarding distributed processing and performance improvements in Gensim. We have “multiple streams API” planned for this year’s Google Summer of Code. This basically means we’ll refactor the algorithms in Gensim to accept multiple streams on input (as opposed to a single stream now), which should improve performance across the board. This will allow easier distributed processing, as well as “unblock” performance use-cases where the single-stream I/O is the bottleneck now (word2vec dictionary building, text preprocessing, etc).
The comments underneath this question (yes, I read them all) gave us several cool tips for new additions. From automatic topic labelling (work-in-progress, PR #2003), to new exciting algos that reduce space and improve quality (#1619 sent2vec, #2011 word2bits, #1827 soft cosine similarity, #2007 online non-negative matrix factorization) or performance (#2035 distributed processing with Dask). Model selection is tricky, but we hear you and will try to improve the overall pipeline process, too.
As always, the challenge is to implement something robust that actually works (as opposed to just looks cool in a conference paper), so with each PR, we’re doing replication studies, benchmarking and optimizations.
To manage expectations: right now, we want to focus on the documentation and tightening the existing functionality. So please be patient as we work through this wish-list.
Finally, we’re already working on automated text segmentation, adaptive models, transfer learning and industry-specialized pipelines (contract management, eDiscovery, patent search, customer support). But this is a part of our commercial product for fast large-scale semantic indexing and search, scaletext.com, and won’t be open sourced (we have to make a living too!). You can subscribe to our ScaleText Newsletter here.
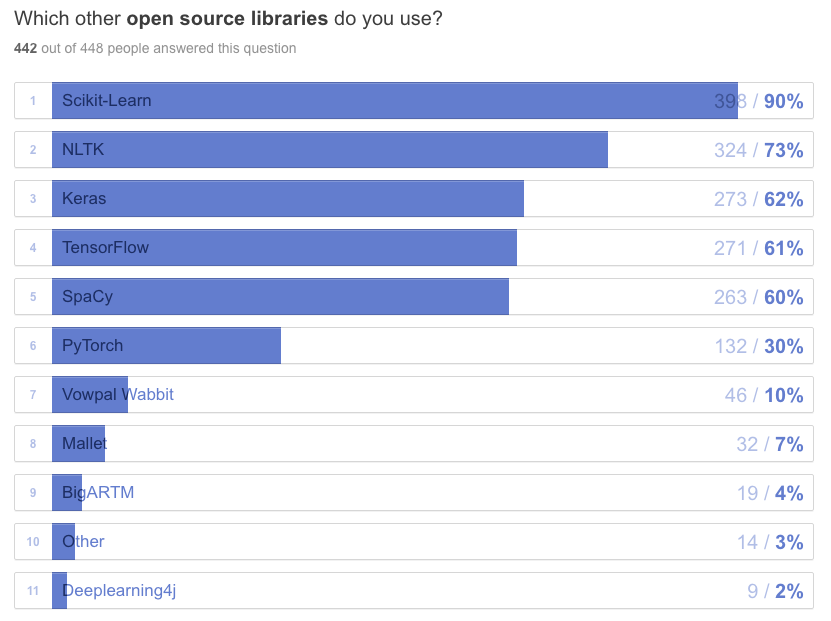
When it comes to integrations, Scikit-learn is still the king of machine learning in Python. Many comments also called for a tighter integration with TensorFlow, Keras and spaCy.
A note on the (many) requests for more text preprocessing capabilities directly into Gensim: There are several excellent packages for NLP. It seems there’s still demand for a fast but flexible Python toolkit (something between NLTK and SpaCy?), but we’ve mostly avoided text preprocessing so far, on purpose. In Gensim, training starts with already preprocessed / tokenized documents, and all models (word2vec, bag-of-words, collocations) work on top of that. Though we may improve the integration with other libraries by means of better tutorials on how to connect the ecosystems effectively, we’re probably not going to go in the direction of “native implementation”.
What sucks about Gensim?

Gensim scores high in reliability, stability and model quality, but clearly its documentation is lacking.
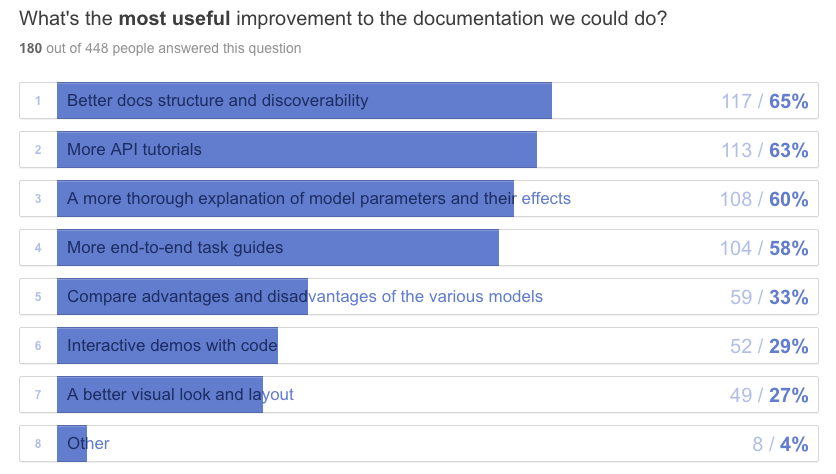
How do we plan to improve the documentation situation?
A massive effort is in underway to improve the API docs, refactoring the documentation in NumPy doc style and extending the parameter descriptions.
In addition, we’ll retire the ancient “Gensim home” at radimrehurek.com/gensim, to be replaced by a new site with better structure: API ref, example gallery, guides, demos. Since our dev team has zero design and web dev skills, this process is taking forever. If you know a good designer eager to show their skills on an open source project, please get in touch with us.
(Or maybe we should wait a bit with the redesign? The existing site is so old school, so retro, that if we wait a little that style may become fashionable again :D )
Preparing input corpora and preprocessing is clearly a common pain point. As mentioned above, we don’t consider text preprocessing Gensim’s core mission, so we’ll handle this by adding extra tutorials and guides on how to integrate with SpaCy, NLTK, and other preprocessing toolkits.
Other comments
It seems most people have not heard of our Gensim-data project, so allow me to plug it again here. This is an open source effort to make NLP experimentation easier and reproducible, by collecting and sharing useful corpora and pretrained models. Anyone is welcome to contribute; our requirements are:
Include a clear motivating use-case: we do not accept any vague “just because” datasets or models. Niche industry datasets are fine and even desirable.
Bundle Python code to load the model or corpus right with the dataset release (so users don’t need to guess the data format or write their own parsers, which is always annoying and error prone).
Immutable dataset upgrades: any changes to the model/corpus imply a new release. Existing datasets are there forever, with exactly the same content, to facilitate reproducibility.
See the datasets already available or read more about how to load them from Gensim.
Finally, your comments at the end of the survey (118 of them!) were truly heart-warming. I really appreciate all the kind words and feedback, this is what keeps us going!
Apologies to the gentleman who used doc2vec and then his computer crashed a few days later. He was afraid to import Gensim again, but I really think it’s unrelated. Please give Gensim another try :-)
And that’s it. You can read the full survey stats here. My major take-away: documentation, documentation, documentation.