I stumbled upon Max Jaderberg’s Synthetic Gradients paper while thinking about different forms of communication between neural modules. It’s a simple idea: rather than compute gradients through backpropagation, we can train a model to predict what those gradients will be, and use our prediction to update our weights. It’s dynamic programming for neural networks.
This is the kind of idea I like because, if it works, it expands our modeling capabilities substantially. It would allow us to connect and train various neural modules asynchronously. Whether this turns out to be useful remains to be seen. I wanted to try using this in my own work and didn’t find a Tensorflow implementation to my liking, so here is mine. I also take this opportunity to (attempt to) answer one of the questions I had while reading the paper: why not use synthetic loss instead of synthetic gradients? Supposing we had multiple paths in a DAG architecture—then a synthetic loss (or better, advantage) would give us an interpretable measure of the “quality” of a part of the input, whereas synthetic gradients do not (without additional assumptions).
Below, we use Tensorflow to implement the fully-connected MNIST experiment, as well as the convolutional CIFAR 10 experiment. The Synthetic Gradients paper itself is a non-technical and easy read, so I’m not going go into any detail about what exactly it is we’re doing. Jaderberg’s blog post may be helpful on this front. I also enjoyed Delip Rao’s blog post and follow-up.### Implementation
Imports and data
1 | |
(xtr, ytr), (xte, yte) = tf.keras.datasets.mnist.load_data(path=’mnist.npz’) xtr = xtr.reshape([-1,784]).astype(np.float32) / 255. xte = xte.reshape([-1,784]).astype(np.float32) / 255.
1 | |
def reset_graph(): if ‘sess’ in globals() and sess: sess.close() tf.reset_default_graph()
1 | |
Synthetic grad / loss wrappers and more utilities
Synthetic loss is just like synthetic gradients except we are predicting a scalar loss and then computing the gradients with respect to that loss. I thought this work similarly to the synthetic gradients, but it doesn’t seem to work at all (discussed below).
1 | |
MNIST Experiment
Note: the paper claims that the learning rate was not optimized, but I found that the results are quite sensitive to changes in the learning rate.
1 | |
def train(graph, iters = 25000, batch_size = 256): g = graph res_tr = [] res_te = [] batches_per_epoch = len(xtr)//batch_size num_epochs = iters // batches_per_epoch with tf.Session() as sess: sess.run(g[‘init’]) for epoch in range(num_epochs): x, y = shuffle(xtr, ytr) acc = 0 for i in range(batches_per_epoch): feed_dict = {g[‘x’]: x[ibatch_size:(i+1)batch_size], g[‘y’]: y[ibatch_size:(i+1)batch_size]} acc_, _ = sess.run([g[‘accuracy’], g[‘ts’]], feed_dict) acc += acc_ if (i+1) % batches_per_epoch == 0: res_tr.append(acc / batches_per_epoch)
acc_te = 0 for j in range(10): feed_dict = {g[‘x’]: xte[j1000:(j+1)1000], g[‘y’]: yte[j1000:(j+1)1000], g[‘training’]: False} acc_te += sess.run(g[‘accuracy’], feed_dict) acc_te /= 10.
res_te.append(acc_te)
print(“\rEpoch {}/{}: {:4f} (TR) {:4f} (TE)”\ .format(epoch, num_epochs, acc/batches_per_epoch, acc_te), end=’’) acc = 0
return res_tr, res_te
1 | |
t = time.time() g = build_graph_mnist_fcn() # baseline _, res_baseline = train(g) print(“\nTook {} seconds!”.format(time.time() - t))
1 | |
t = time.time() g = build_graph_mnist_fcn(no_bprop=True) _, res_no_bprop = train(g) print(“\nTook {} seconds!”.format(time.time() - t))
1 | |
t = time.time() g = build_graph_mnist_fcn(sl=True) _, res_sl = train(g) print(“\nTook {} seconds!”.format(time.time() - t))
1 | |
t = time.time() g = build_graph_mnist_fcn(sg=True) _, res_sg = train(g) print(“\nTook {} seconds!”.format(time.time() - t))
1 | |
t = time.time() g = build_graph_mnist_fcn(sg=True, conditioned=True) _, res_sgc = train(g) print(“\nTook {} seconds!”.format(time.time() - t))
1 | |
plt.figure(figsize=(10,6)) plt.plot(res_baseline, label=”backprop”) plt.plot(res_no_bprop, label=”no bprop”) plt.plot(res_sg, label=”sg”) plt.plot(res_sgc, label=”sg + c”) plt.plot(res_sl, label=”sl”) plt.title(“Synthetic Gradients on MNIST”) plt.xlabel(“Epoch”) plt.ylabel(“Accuracy”) plt.ylim([0.5,1.]) plt.legend()
1 | |
(xtr, ytr), (xte, yte) = tf.keras.datasets.cifar10.load_data() xtr = xtr.astype(np.float32) / 255. ytr = ytr.reshape([-1]) xte = xte.astype(np.float32) / 255. yte = yte.reshape([-1])
1 | |
def build_graph_cifar_cnn(sg=False): reset_graph() g = {} g[‘training’] = training = tf.placeholder_with_default(True, [])
g[‘x’] = x = tf.placeholder(tf.float32, [None, 32, 32, 3], name=’x_placeholder’) g[‘y’] = y = tf.placeholder(tf.int64, [None], name=’y_placeholder’)
h1, h1vs = layer_conv_bn_relu(x, 128, 5, ‘same’, ‘max’, training=training) if sg: _, sg1, gvs1, svars1 = sg_wrapper(x, h1, h1vs, model_two_layer_conv)
h2, h2vs = layer_conv_bn_relu(h1, 128, 5, ‘same’, ‘avg’, training=training) if sg: sg1_target, sg2, gvs2, svars2 = sg_wrapper(h1, h2, h2vs, model_two_layer_conv) h = tf.reshape(h2, [-1, 9*128])
logit_layer = tf.layers.Dense(10) logits = logit_layer(h) logit_vs = logit_layer.trainable_variables g[‘loss’] = loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=y)
if sg: sg2_target, gvs3 = loss_grads_with_target(loss, logit_vs, h2) gvs_sg = model_grads([(sg1, sg1_target, svars1), (sg2, sg2_target, svars2)])
with tf.control_dependencies(tf.get_collection(tf.GraphKeys.UPDATE_OPS)): opt = tf.train.AdamOptimizer(3e-5) if sg: g[‘ts’] =\ opt.apply_gradients(gvs1 + gvs2 + gvs3 + gvs_sg) else: g[‘ts’] =\ opt.minimize(loss)
g[‘accuracy’] = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(logits, 1), y), tf.float32)) g[‘init’] = tf.global_variables_initializer()
return g
1 | |
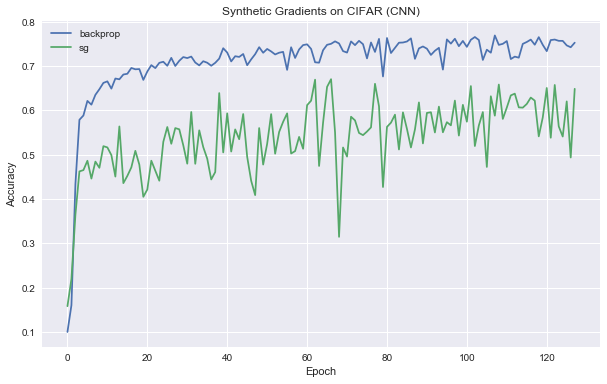
Epoch 127/128: 0.774700 (TR) 0.648300 (TE) Took 943.7978417873383 seconds
1 | |
Epoch 127/128: 0.901683 (TR) 0.752400 (TE) Took 584.2685778141022 seconds
1 | |