In my previous MapD post, I loaded electricity data into MapD Community Edition, intentionally ignoring the what of the data to keep that post from being too overwhelming. Now let’s take a step back and explain the dataset, show how to format the data using Python that was loaded into MapD, then use the MapD Immerse UI to build a simple dashboard.
PJM Metered Load Data
I started off my career at PJM doing long-term electricity demand forecasting, to help power engineers do transmission line studies for reliability and to support expansion of the electrical grid in the U.S. Because PJM is a quasi-government agency, they provide over 25 years of hourly electricity usage for the Eastern and Central U.S., both in aggregate and by local power region (roughly, the local power company territories).
However, just because the data is available doesn’t mean it’s convenient, and unfortunately, the data are stored as Excel spreadsheets. This is easily remedied using pandas (v0.22.0, python3.6):
1 | |
The code is a bit verbose, if only because I didn’t want to spend time to figure out how to programmatically determine how many tabs each workbook has. But the concept is the same each time: read an Excel file, get the data into a dataframe, then convert the data to long form. So instead of having 26 columns (Date, Zone, Hr1-Hr24), we have 4 columns, which is quite frequently a more convenient way to access the data (especially when using SQL).
The final statement writes out a CSV of approximately 4MM rows, the same dataset that was loaded using mapdql in the first post.
Top 10 Usage Days By Season
One of the metrics I used to monitor as part of my job was the top 5/top 10 peak electricity use days per Summer (high A/C usage) and Winter (electric space heating) seasons. Back in those days, I used to use SAS against an enterprise database and the results would come back eventually…
Obviously, it’s not a fair comparison to compare today’s GPUs vs. late ’90s enterprise databases in terms of performance, but back then it did take a non-trivial amount of effort to run this query to keep the report updated. With MapD, I can do the same report in ~100ms:
1 | |
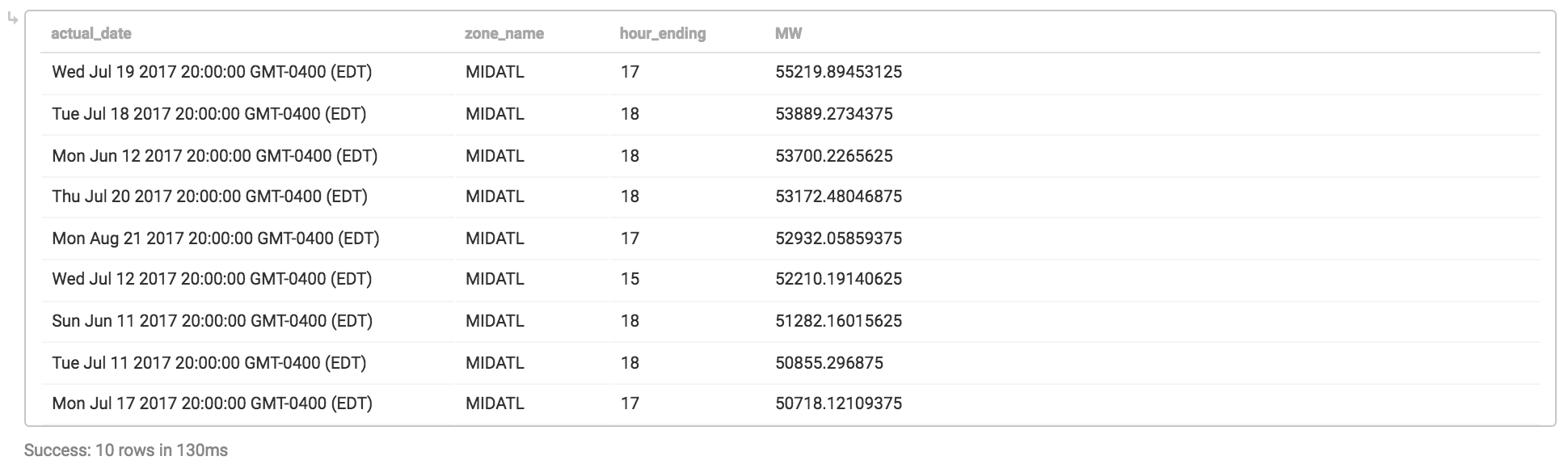
The thing about returning an answer in 100ms or so is that its fast enough where calling these results from a webpage/dashboard would be very responsive; that’s where MapD Immerse comes in.
Building A Dashboard Using MapD Immerse
Rather than copy/pasting the query in and running it, it’s pretty easy to build an automated report using the Immerse dashboard builder. I’m limited to a single data source because I’m using MapD Community Edition, but in just a few minutes I was able to create the following dashboard:
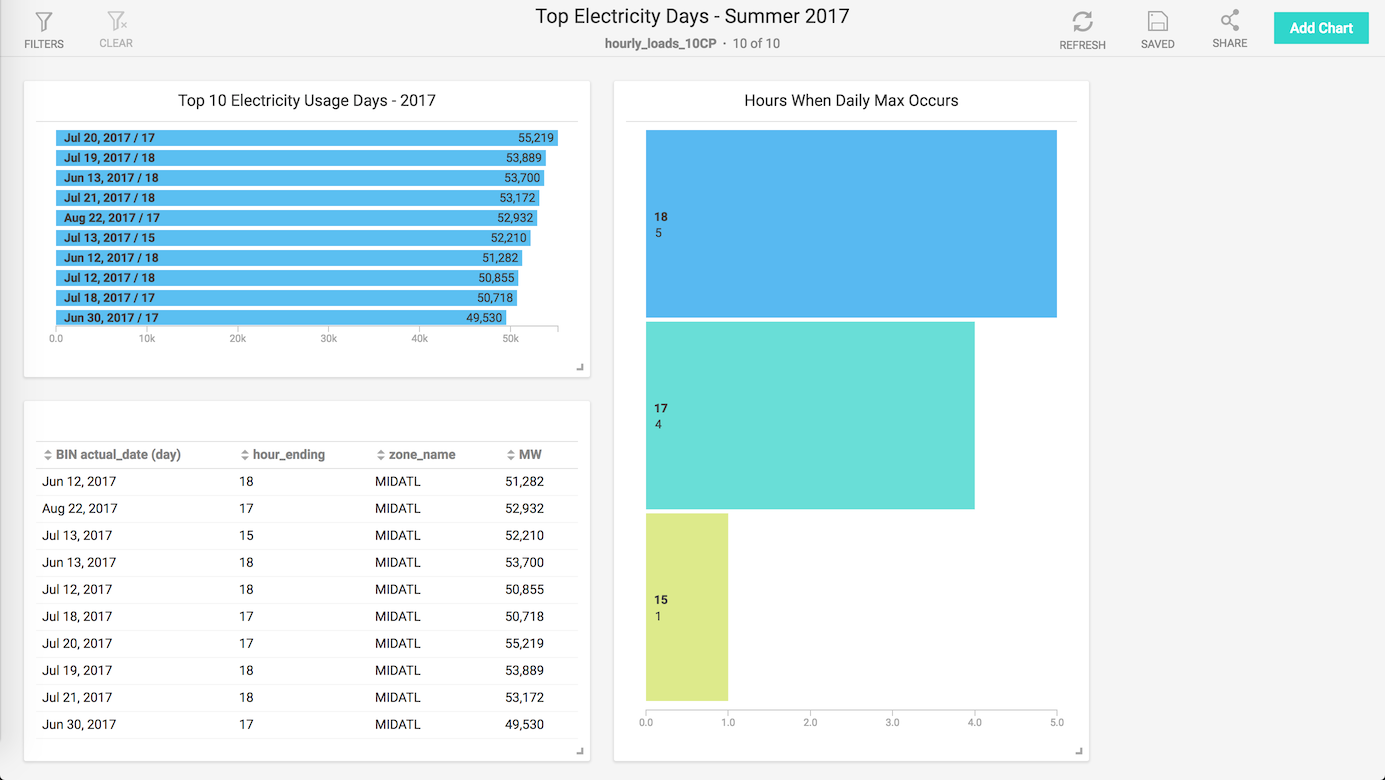
I took the query from above and built a view to encapsulate the query, so I didn’t have to worry about the with statement or joins, I could just use the view as if the results were pre-calculated. From there, adding in a results table and two bar charts was fairly quick (in the same drag-and-drop style of Tableau or other BI/reporting tools).
While this dashboard is pretty rudimentary in its design, were this data source set up as real-time using Apache Kafka or similar, this chart would always be up-to-date for use on a TV screen or as a browser bookmark without any additional data or web engineering.
Obviously, many dashboarding tools exist, but its important to note that no pre-aggregation or column indexing or other standard database performance tricks are being employed (outside of specialized hardware and fast GPU RAM caching). Even with 10 dashboard tiles updating serially 100ms at a time, you are still in the 1-2s page load time, on par with the fastest-loading dynamic webpages on the internet.
Programmatic analytics using pymapd
While dashboarding can be very effective for keeping senior management up-to-date, the real value of data is unlocked with more in-depth analytics and segmentation. In my next blog post, I’ll cover how to access MapD using pymapd in Python, doing more advanced visualizations and maybe even some machine learning…