Locke Data’s great blog is Markdown-based. What this means is that all blog posts exist as Markdown files: you can see all of them here. They then get rendered to html by some sort of magic cough blogdown cough we don’t need to fully understand here. For marketing efforts, I needed a census of existing blog posts along with some precious information. Here is how I got it, in other words here is how I rectangled the website GitHub repo and live version to serve our needs.
Note: This should be applicable to any Markdown-based blog!
To find out what a blog post is about, I read its tags and categories, that live in the YAML header of each post, see for instance this one. Just a note, thank you, participants in this Stack Overflow thread.
Getting all blog posts names and path
I used the gh package to interact with GitHub V3 API.
1 | |
Here is the table I got:
1 | |
There are 169 posts in this table.
Getting all blog post image links
In a blogdown blog, you do not need to be consistent with image naming, as long as you give the correct link inside your post. Images used on Steph’s blog live here and their names often reflect the blog post name, but not always. I thought it could be useful to have a table of all blog posts images. I wrote a function that downloads the content of each post and extract image links.
1 | |
Let’s see what it does for one path.
1 | |
| path | img |
|---|---|
| content/posts/2013-05-11-setting-up-wordpress-on-azure.md | azurescreenshot1_ujw0yl_finrxl.png |
Ok then I simply needed to apply it to all posts.
1 | |
Having this table, one could run some analysis of the number of images by post, extract pictures when promoting a post, and tidy a website. I think Steph’s filenames are good, but I could imagine renaming files based on the blog post they appear in if it had not been done previously (and changing the link inside posts obviously), but hey why clean if one can link the data anyway.
Getting all tags and categories
The code here is similar to the previous one but slightly more complex because I wrote the post content inside a temporary .yaml file in order to read it using rmarkdown::yaml_front_matter.
1 | |
I’ll illustrate this with one post:
1 | |
[1] “content/posts/2013-05-11-setting-up-wordpress-on-azure.md”
1 | |
info <- purrr::map_df(gh_posts$path, get_one_yaml) gh_posts <- dplyr::left_join(gh_posts, info, by = “path”)
readr::write_csv(gh_posts, path = “data/gh_posts.csv”)
1 | |
library(“magrittr”)
get links and tags
sitemap <- xml2::read_xml(“https://itsalocke.com/blog/sitemap.xml”) %>% xml2::as_list() %>% .$urlset
probably re-inventing the wheel
get_one <- function(element, what){ one <- unlist(element[[what]]) if(is.null(one)){ one <- “” }
one }
tibble with everything
sitemap <- tibble::tibble(url = purrr::map_chr(sitemap, get_one, “loc”), date = purrr::map_chr(sitemap, get_one, “lastmod”))
only blog posts
blog <- dplyr::filter(sitemap, !stringr::str_detect(url, “tags\/”)) blog <- dplyr::filter(blog, !stringr::str_detect(url, “categories\/”)) blog <- dplyr::filter(blog, !stringr::str_detect(url, “statuses\/”)) blog <- dplyr::filter(blog, url != “https://itsalocke.com/blog/stuff-i-read-this-week/”) blog <- dplyr::filter(blog, !stringr::str_detect(url, “https://itsalocke.com/blog/.?\/.?\/”)) blog <- dplyr::filter(blog, url != “https://itsalocke.com/blog/”) blog <- dplyr::filter(blog, url != “https://itsalocke.com/blog/posts/”)
1 | |
head(blog) %>% knitr::kable()
1 | |
gh_info <- readr::read_csv(“data/gh_posts.csv”) gh_info <- dplyr::filter(gh_info, !stringr::str_detect(name, “\.Rmd”))
unique(gh_info$slug)
1 | |
https://github.com/rstudio/blogdown/blob/0c4c30dbfb3ae77b27594685902873d63c2894ad/R/utils.R#L277
dash_filename = function(string, pattern = ‘[^[:alnum:]^\.]+’) { tolower(string) %>% stringr::str_replace_all(“â”, “”) %>% stringr::str_replace_all(“DataOps.? it.?s a thing (honest)”, “dataops–its-a-thing-honest”) %>% stringr::str_replace_all(pattern, ‘-‘) %>% stringr::str_replace_all(‘^-+|-+$’, ‘’)
} gh_info <- dplyr::mutate(gh_info, base = ifelse(!is.na(slug), slug, title), base = dash_filename(base), false_url = paste0(“https://itsalocke.com/blog/”, base, “/”))
1 | |
[1] “https://itsalocke.com/blog/data-manipulation-in-r/”
[2] “https://itsalocke.com/blog/using-blogdown-with-an-existing-hugo-site/”
[3] “https://itsalocke.com/blog/working-with-pdfs-scraping-the-pass-budget/”
[4] “https://itsalocke.com/blog/year-2-of-locke-data/”
[5] “https://itsalocke.com/blog/connecting-to-sql-server-on-shinyapps.io/”
[6] “https://itsalocke.com/blog/how-to-maraaverickfy-a-blog-post-without-even-reading-it/”
1 | |
all_info <- fuzzyjoin::stringdist_left_join(blog, gh_info, by = c(“url” = “false_url”), max_dist = 3) all_info$url[(is.na(all_info$raw))]
1 | |
[1] “Shiny module design patterns: Pass module input to other modules”
[2] “Shiny module design patterns: Pass module inputs to other modules”
[3] “optiRum 0.37.1 now out”
[4] “optiRum 0.37.3 now out”
readr::write_csv(all_info, path = “data/all_info_about_posts.csv”)
1 | |
head(all_info) %>% knitr::kable()
1 | |
library(“ggplot2”) all_info <- dplyr::mutate(all_info, date = anytime::anytime(date.x)) ggplot(all_info) + geom_point(aes(date), y = 0.5, col = “#2165B6”, size = 0.9) + hrbrthemes::theme_ipsum(grid = “Y”)
1 | |
all_info <- dplyr::select(all_info, - base, - false_url) categories_info <- all_info %>% tidyr::gather(“category”, “value”, 11:ncol(all_info)) %>% dplyr::filter(!is.na(value)) %>% dplyr::filter(stringr::str_detect(category, “cat\”)) %>% dplyr::mutate(category = stringr::str_replace(category, “cat\”, “”)) categories <- categories_info %>% dplyr::count(category, sort = TRUE)
knitr::kable(categories)
1 | |
categories_info <- dplyr::mutate(categories_info, date = anytime::anytime(date.x)) ggplot(categories_info) + geom_point(aes(date, category), col = “#2165B6”, size = 0.9) + hrbrthemes::theme_ipsum(grid = “Y”) ```
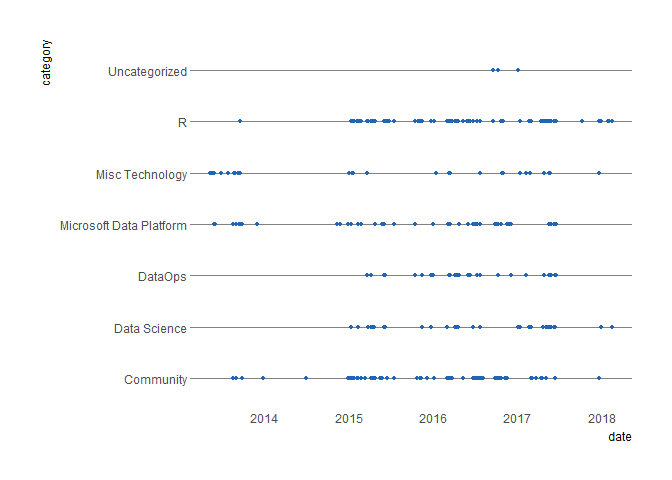
In the most recent period, R and Data Science seem to be getting more love than the other categories.
Let’s see what other/more exciting things we can do with this data, to help make Locke Data blog even better and more read!