In a previous post, I looked at how the established value based drafting (VBD) algorithm for picking fantasy football rosters would perform in a league of typical human players. It turned out that we get different performance depending on if we look at ranks of VBD drafters based (i) on expected preseason player forecasts or (ii) on actual points scored by a player that season. Based on preseason forecasts, we could expect a VBD roster to place 2nd in a 12 player league, while using actual player points, VBD is only expected to rank at 4.68. That’s still better than it would do by chance (if VBD came in 6th place), but it’s really only a slight advantage. This made me wonder if it would be all that difficult to improve on VBD using methods similar to those used to train AIs to play video/board games.
The simplest starting point might be taking a value iteration approach similar to the one described in the Mnih et. al Atari games paper from 2013. A pretty accessible introduction to the topic can be found in chapter 12 of David Poole and Alan Mackworth’s free online AI text, but in a nutshell, value iteration learns a game-playing policy by iteratively learning a function, Q(s,a), which captures the value of taking an action, 


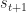
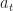
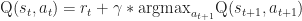
where 
It’s also similar to the VBD algorithm, where the value function has been tuned through trial and error by humans since it’s initial description in 2001. The immediate reward would be 

For the Atari games, Q(s,a) was modeled using a neural network trained on gameplay data. Data was collected using an 
So getting started…
The previous post evaluating VBD has already left me with a more or less reasonable simulator of leagues with typical human drafters and players strictly following VBD. Here, I would just need to extend it with (i) a drafting policy that allows me to act in a way that exploits the value function or explores new roster combinations with some randomly selected actions, (ii) logging experience tuples 
Since the draft simulator is already written in R, I decided to start modeling value with two of the bread and butter models readily available, linear regression with fused lasso regularization through glmnet, and gradient boosted trees through xgboost. Of course, the strength of the Atari paper was the use of the latest and greatest convolutional networks, and maybe it’s worth eventually building up to that, but for a quick first cut, I wanted to try something simple that works out of the box.
States, actions, and rewards in FF drafts.The state of a roster at some point in the draft, 
My goal for this model is to obtain the greatest total points from all starters on the roster, and so the form of the reward would be slightly different than in VBD. Whereas VBD looks at the player’s individual points, I am interested in if a player would improve the overall roster score, so here the immediate reward is: 

For simulating drafts, I used 
The R scripts to learn and evaluate the Q-value functions are here. I used the same three seasons as before (2014-2016) and evaluated performance relative to human and VBD drafters.
Results so far.
With a slight amount of tuning, we converge pretty quickly, and it is straightforward to find a Q-value function that outperforms VBD in a league of humans on data within the same year. At the same time, it is easy to fail miserably at generalizing across years, and in some cases, would probably need to invest a bit more TLC just to beat plain old VBD.
Learning Curves
I first learned a Q function for each season, alternating drafts against all human or all VBD leagues, random sampling draft positions. To do this I used a fixed

Comparison with VBD
To see if this actually managed to improve over the VBD baseline from the previous post, I looked at how rosters selected using the learned values would rank in a draft in a human league compared with how VBD would rank. Using the logged experience from the xgboost exploration above, I retrained the value function either using glmnet or xgboost as the model. At first glance, this seems fine to do since we’re taking an off-policy learning approach anyway, but can revisit this. To look at the ability to generalize, I either trained only on the same year that the model would be evaluated on, or I trained using the other two years.
xgboost always wins within the same year, but across years it only wins in 2016, while VBD is better in the other two years. Since the action representations include the same contrasts used for VBD, this to me suggests that the weights learned using just two years don’t always generalize. Would be interesting to rinse and repeat on like a 20 to 30 year stretch if I could find the data somewhere.

###
Anyway, that’s what I got for a first take on doing this
Here’s a random set of some other things that might eventually be worth trying.
- better preseason predictions / more years of historical data
other league combinations
- more adversary combinations
human drafters with constraints
-
online updates
-
other exploration schemes
-
additional features, encodings of draft position, or use a NN
Like this:
Like Loading…