For my first act, two topics related to sequential data that should come up if you search google for “Cinderella science”, which you might do if you’re ever looking for stories of uncredited hard work that ultimately worked out (if only with the help of a fairy godmother).
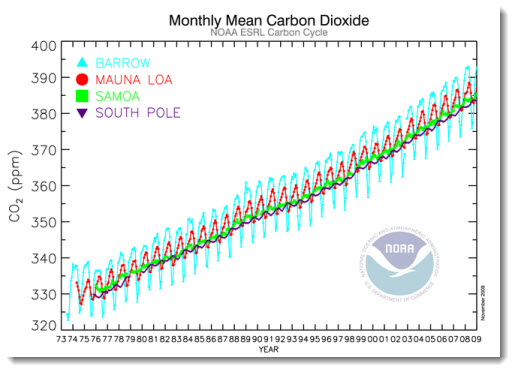
One is just a reference to something I feel more people should know about and is the source of the above photo. The photo is of Charles Keeling, the scientist credited with setting up CO2 monitoring in Mauna Loa, Hawaii, which he did in the 1960’s, before it was cool. I found his story in this commentary in Nature about the ups and downs of the thankless work involved in getting everything going. Understandably, it was a hard sell initially, as it doesn’t test a sexy falsifiable hypothesis. But in the end, it was the years of data from Keeling’s initial work that provided the evidence for the significant gradual changes in our atmospheric composition. Kind of makes me wonder whether we really need to have the same conversation again in the context of motivating exploratory space research?
For the uninitiated, the resulting time series is gorgeous.
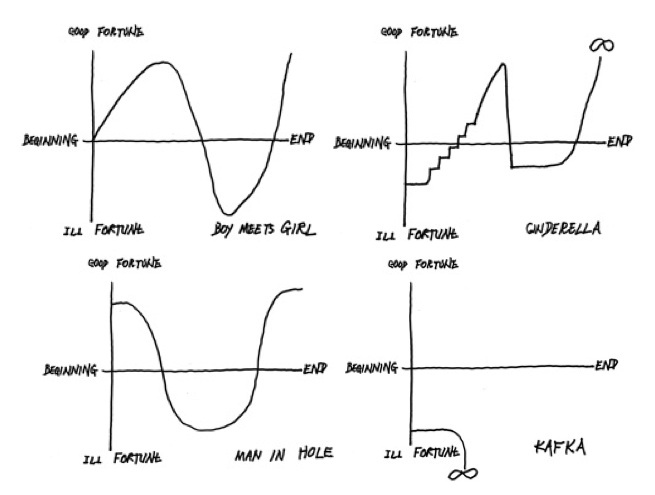
The second topic I wanted to mention probably doesn’t come up in the top google search results, but I think it ought to. There’s this paper on the analysis of plot progressions in Project Gutenberg‘s fiction collection claiming that there are just 6 fundamental plot types. Seemingly everywhere the paper is mentioned, The Atlantic, MIT Technology Review, New York Magazine, etc., it comes with this snippet from a Kurt Vonnegut lecture, where Vonnegut anticipates similar results decades earlier. But what’s a bit unsatisfying for me, is that no one really validates the plot arcs that Vonnegut didn’t even need a model to recognize.
I set out to reproduce the last of the arcs that Vonnegut describes – the Cinderella narrative (top right in the four plots below).
So what does it take to distill this expected profile from the text? I started with Mathew Jockers “syuzhet” R package (which incidentally his blog also links the Vonnegut lecture). The package provides pretty much everything we need: functions to parse a text into sentences, parse those sentences into word tokens, map tokens to sentiment values from various sources, then pool (read average/max) the sentiments at the sentence level, and finally obtain a smoothed narrative profile. After downloading “CINDERELLA; Or, THE LITTLE GLASS SLIPPER.” from Proj. Gutenberg and copy-pasting a few lines from the syuzhet vignette, can confirm without breaking a sweat, things for the most part check out.
Tada, stamp collected!!
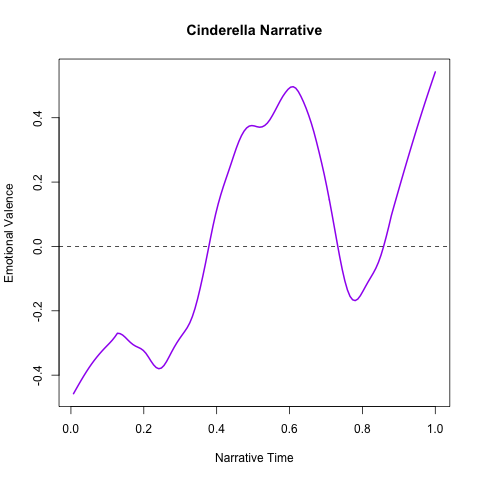
Kind of surprising that assigning sentiments to individual words from a manually curated dataset can produce these results, but I guess sometimes smoothing sequential data can work magic.
What might be the global warming equivalent in the world of these narrative arcs?