** Wed 25 January 2017
Over the last year, I have been working with the Apache Parquet community to
build out parquet-cpp, a first class C++ Parquet file reader/writer
implementation suitable for use in Python and other data applications. Uwe
Korn and I have built the Python interface and integration with pandas
within the Python codebase (pyarrow) in Apache Arrow.
This blog is a follow up to my 2017 Roadmap post.
Design: High performance columnar data in Python
The Apache Arrow and Parquet C++ libraries are complementary technologies that we’ve been engineering to work well together.
Arrow C++ libraries provide memory management, efficient IO (files, memory maps, HDFS), in-memory columnar array containers, and extremely fast messaging (IPC / RPC). I will write more about Arrow’s messaging layer in another blog post.
The Parquet C++ libraries are responsible for encoding and decoding the
Parquet file format. We have implemented a libparquet_arrow library that
handles transport between in-memory Arrow data and the low-level Parquet
reader/writer tools
PyArrow provides a Python interface to all of this, and handles fast conversions to pandas.DataFrame.
One of the primary goals of Apache Arrow is to be an efficient, interoperable columnar memory transport layer.
You can read about the Parquet user API in the PyArrow codebase. The libraries are available from conda-forge at:
Performance Benchmarks: PyArrow and fastparquet
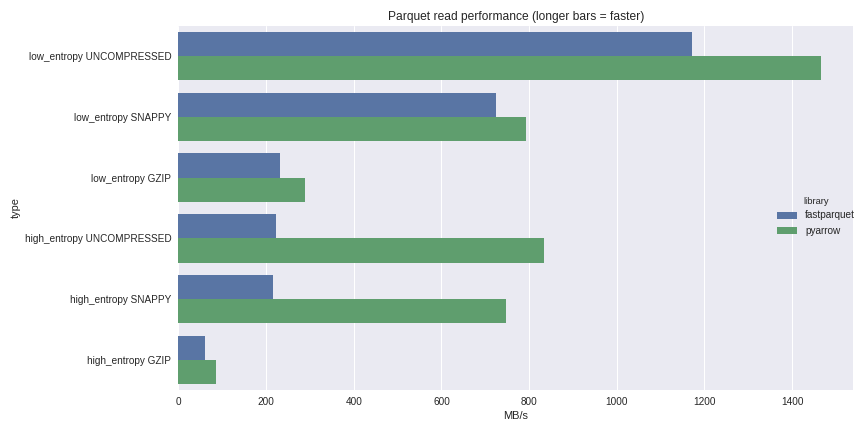
To get an idea of PyArrow’s performance, I generated a 512 megabyte dataset of numerical data that exhibits different Parquet use cases. I generated two variants of the dataset:
High entropy: all of the data values in the file (with the exception of null values) are distinct. This dataset occupies 469 MB on disk.
Low entropy: the data exhibits a high degree of repetition. This data encodes and compresses to a very small size: only 23 MB with Snappy compression. If you write the file with dictionary encoding, it is even smaller. Because decoding such files become more CPU bound than IO bound, you can typically expect higher data throughput from low entropy data files.
I wrote these files for the 3 main compression styles in use: uncompressed, snappy, and gzip. I then compute the wall clock time to obtain a pandas DataFrame from disk.
fastparquet is a newer Parquet file reader/writer implementation for Python users created for use in the Dask project. It is implemented in Python and uses the Numba Python-to-LLVM compiler to accelerate the Parquet decoding routines. I also installed that to compare with alternative implementations.
The code to read a file as a pandas.DataFrame is similar:
The green bars are the PyArrow timings: longer bars indicate faster performance / higher data throughput. Hardware is a Xeon E3-1505 laptop.
I just updated these benchmarks on February 1, 2017 against the latest codebases.
Development status
We are in need of help on Windows builds and packaging. Also, keeping the conda-forge packages up to date is very time consuming. Of course, we’re looking for both C++ and Python developers to contribute to the codebases in general.
So far, we have focused on having a production-quality implementation of the file format with strong performance reading and writing flat datasets. We are starting to move onto handling nested JSON-like data natively in parquet-cpp using Arrow as the container for the nested columnar data.
Recently Uwe Korn has just implemented some support for the List Arrow
type in conversions to pandas:
Benchmarking code
Here is the code