Suppose you work for a business that has paying customers. You want to know how much money your customers are likely to spend to inform decisions on customer acquisition and retention budgets. You’ve done a bit of research, and discovered that the figure you want to calculate is commonly called the customer lifetime value. You google the term, and end up on a page with ten results (and probably some ads). How many of those results contain useful, non-misleading information? As of early 2017, fewer than half. Why is that? How can it be that after nearly 20 years of existence, Google still surfaces misleading information for common search terms? And how can you calculate your customer lifetime value correctly, avoiding the traps set up by clever search engine marketers? Read on to find out!
Background: Misleading search results and fake news
While Google tries to filter obvious spam from its index, it still relies to a great extent on popularity to rank search results. Popularity is a function of inbound links (weighted by site credibility), and of user interaction with the presented results (e.g., time spent on a result page before moving on to the next result or search). There are two obvious problems with this approach. First, there are no guarantees that wrong, misleading, or inaccurate pages won’t be popular, and therefore earn high rankings. Second, given Google’s near-monopoly of the search market, if a page ranks highly for popular search terms, it is likely to become more popular and be seen as credible. Hence, when searching for the truth, it’d be wise to follow Abraham Lincoln’s famous warning not to trust everything you read on the internet.

Google is not alone in helping spread misinformation. Following Donald Trump’s recent victory in the US presidential election, many people have blamed Facebook for allowing so-called fake news to be widely shared. Indeed, any popular media outlet or website may end up spreading misinformation, especially if – like Facebook and Google – it mainly aggregates and amplifies user-generated content. However, as noted by John Herrman, the problem is much deeper than clearly-fabricated news stories. It is hard to draw the lines between malicious spread of misinformation, slight inaccuracies, and plain ignorance. For example, how would one classify Trump’s claims that climate change is a hoax invented by the Chinese? Should Twitter block his account for knowingly spreading outright lies?
Wrong customer value calculation by example
Fortunately, when it comes to customer lifetime value, I doubt that any of the top results returned by Google is intentionally misleading. This is a case where inaccuracies and misinformation result from ignorance rather than from malice. However, relying on such resources without digging further is just as risky as relying on pure fabrications. For example, see this infographic by Kissmetrics, which suggests three different formulas for calculating the average lifetime value of a Starbucks customer. Those three formulas yield very different values ($5,489, $11,535, and $25,272), which the authors then say should be averaged to yield the final lifetime value figure. All formulas are based on numbers that the authors call constants, despite the fact that numbers such as the average customer lifespan or retention rate are clearly not constant in this context (since they’re estimated from the data and used as projections into the future). Indeed, several people have commented on the flaws in Kissmetrics’ approach, which is reminiscent of the Dilbert strip where the pointy-haired boss asks Dilbert to average and multiply wrong data.

My main problem with the Kissmetrics infographic is that it helps feed an illusion of understanding that is prevalent among those with no statistical training. As the authors fail to acknowledge the fact that the predictions produced by the formulas are inaccurate, they may cause managers and marketers to believe that they know the lifetime value of their customers. However, it’s important to remember that all models are wrong (but some models are useful), and that the lifetime value of active customers is unknowable since it involves forecasting of uncertain quantities. Hence, it is reckless to encourage people to use the Kissmetrics formulas without trying to quantify how wrong they may be on the specific dataset they’re applied to.
Fader and Hardie: The voice of reason
Notably, the work of Peter Fader and Bruce Hardie on customer lifetime value isn’t directly referenced on the first page of Google results. This is unfortunate, as they have gone through the effort of making their models accessible to people with no academic background, e.g., using Excel spreadsheets and YouTube videos. However, it is clear that they are not optimising for search engine rankings, as I found out about their work by adding search terms that the average marketer is unlikely to use (e.g., Python and Bayesian). While surveying Fader and Hardie’s large body of work is beyond the scope of this article, it is worth summarising their criticism of the lifetime value formula that is taught in introductory marketing courses.
The formula discussed by Fader and Hardie is 
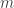

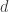
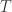
The true lifetime value is unknown while the customer is still active, so the formula is actually for the expected lifetime value, i.e., 


-
The formula assumes a constant retention rate. However, it is often the case that retention increases with tenure, i.e., customers who have been with the company for a long time are less likely to churn than recently-acquired customers.
-
It isn’t always possible to calculate a retention rate, as the point at which a customer churns isn’t observed for many products. For example, Starbucks doesn’t know whether customers who haven’t made a purchase for a while have decided to never visit Starbucks again, or whether they’re just going through a period of inactivity. Further, given the ubiquity of Starbucks, it is probably safe to assume that all past customers have a non-zero probability of making another purchase (unless they’re physically dead).
According to Fader and Hardie, “the bottom line is that there is no ‘one formula’ that can be used to compute customer lifetime value“. Therefore, teaching the above formula (or one of its variants) misleads people into thinking that they know how to calculate the lifetime value of customers. Hence, they advocate going back to the definition of lifetime value as “the present value of the future cashflows attributed to the customer relationship“, and using a probabilistic approach to generate estimates of the expected lifetime value for each customer. This conclusion also appears in a more accessible series of blog posts by Custora, where it is claimed that probabilistic modelling can yield significantly more accurate estimates than naive formulas.
Getting serious with the lifetimes package
As mentioned above, Fader and Hardie provide Excel implementations of some of their models, which produce individual-level lifetime value predictions. While this is definitely an improvement over using general formulas, better solutions are available if you can code (or have access to people who can do coding for you). For example, using a software package makes it easy to integrate the lifetime value calculation into a live product, enabling automated interventions to increase revenue and profit (among other benefits). According to Roberto Medri, this approach is followed by Etsy, where lifetime value predictions are used to retain customers and increase their value.
An example of a software package that I can vouch for is the Python lifetimes package, which implements several probabilistic models for lifetime value prediction in a non-contractual setting (i.e., where churn isn’t observed – as in the Starbucks example above). This package is maintained by Cameron Davidson-Pilon of Shopify, who may be known to some readers from his Bayesian Methods for Hackers book and other Python packages. I’ve successfully used the package on a real dataset and have contributed some small fixes and improvements. The documentation on GitHub is quite good, so I won’t repeat it here. However, it is worth reiterating that as with any predictive model, it is important to evaluate performance on your own dataset before deciding to rely on the package’s predictions. If you only take away one thing from this article, let it be the reminder that it is unwise to blindly accept any formula or model. The models implemented in the package (some of which were introduced by Fader and Hardie) are fairly simple and generally applicable, as they rely only on the past transaction log. These simple models are known to sometimes outperform more complex models that rely on richer data, but this isn’t guaranteed to happen on every dataset. My untested feeling is that in situations where clean and relevant training data is plentiful, models that use other features in addition to those extracted from the transaction log would outperform the models provided by the lifetimes package (if you have empirical evidence that supports or refutes this assumption, please let me know).

Conclusion: You’re better than that
Accurate estimation of customer lifetime value is crucial to most businesses. It informs decisions on customer acquisition and retention, and getting it wrong can drive a business from profitability to insolvency. The rise of data science increases the availability of statistical and scientific tools to small and large businesses. Hence, there are few reasons why a revenue-generating business should rely on untested customer value formulas rather than on more realistic models. This extends beyond customer value to nearly every business endeavour: Relying on fabrications is not a sustainable growth strategy, there is no way around learning how to be intelligently driven by data, and no amount of cheap demagoguery and misinformation can alter the objective reality of our world.
Like this:
Like Loading…