Can several wrongs make a right? While it may seem counter-intuitive, this is possible, sometimes even preferable, in designing predictive models for complex problems such as crime prediction.
In the film Minority Report, police officers were able to predict and prevent murders before they happened. While current technology is nowhere near, predictive policing has been implemented in some cities to identify locations with high crime. Location-based crime records could be coupled with other data sources, such as income levels of residents, or even the weather, to forecast crime occurrence. In this chapter we build a simple random forest to forecast crime in San Francisco, California, USA.
Random forests combine the predictions of multiple decision trees. Recall from our previous chapter that in constructing a decision tree, the dataset is repeatedly divided into subtrees, guided by the best combination of variables. However, finding the right combination of variables can be difficult. For instance, a decision tree constructed based on a small sample might be not be generalizable to future, large samples. To overcome this, multiple decision trees could be constructed, by randomizing the combination and order of variables used. The aggregated result from these forest of trees would form an ensemble, known as a random forest.
Random forest predictions are often better than that from individual decision trees. The chart below compares the accuracy of a random forest to that of its 1000 constituent decision trees. Only 12 out of 1000 individual trees yielded an accuracy better than the random forest. In other words, there is a 99% certainty that predictions from a random forest would be better than that from an individual decision tree.
 Histogram showing the accuracy of 1000 decision trees. While the average accuracy of decision trees is 67.1%, the random forest model has an accuracy of 72.4%, which is better than 99% of the decision trees.
Histogram showing the accuracy of 1000 decision trees. While the average accuracy of decision trees is 67.1%, the random forest model has an accuracy of 72.4%, which is better than 99% of the decision trees.
Past research show that crime tends to occur on hotter days. Open data from the San Francisco Police Department (SFPD) and National Oceanic and Atmospheric Administration (NOAA) were used to test this hypothesis. The SFPD data contains information on crimes, including location, date, and crime category. The NOAA data provides information on daily temperature and precipitation in the city.
 A heat map of crime levels in San Francisco. Colors indicate crime severity, which can be very low (gray), low (yellow), moderate (orange), or high (red)
A heat map of crime levels in San Francisco. Colors indicate crime severity, which can be very low (gray), low (yellow), moderate (orange), or high (red)
Realistically, SFPD can only afford to concentrate extra patrols in certain areas due to limited manpower. Hence, the model is tasked to select about 30% of the rectangles each day that it predicts to have the highest probability of a violent crime occurring, so that SFPD can increase patrol in these areas. Data from 2014 to 2015 was used to train the model, while data in 2016 (Jan – Aug) was used to test the model’s accuracy.
A random forest of 1000 decision trees successfully predicted 72.4% of all the violent crimes that happened in 2016 (Jan – Aug). A sample of the predictions can be seen below:
 Crime predictions for 7 consecutive days in 2016. Circles denote locations where a violent crime is predicted to happen. Solid circles denote correct predictions. Crosses denote locations where a violent crime happened, but was not predicted by the model.
Crime predictions for 7 consecutive days in 2016. Circles denote locations where a violent crime is predicted to happen. Solid circles denote correct predictions. Crosses denote locations where a violent crime happened, but was not predicted by the model.
Random forest also allows us to see which variables contribute most to its prediction accuracy. Based on the chart below, crime appears to be best forecasted using crime history, location, day of the year and maximum temperature of the day.

Top 12 variables contributing to the random forest’s accuracy in predicting crime.
A random forest is an example of an ensemble, which is a combination of predictions from different models. In an ensemble, predictions could be combined either by majority-voting or by taking averages. Below is an illustration of how an ensemble formed by majority-voting yields more accurate predictions than the individual models it is based on:
 Example of three individual models attempting to predict 10 outputs of either Blue or Red. The correct predictions are Blue for all 10 outputs. An ensemble formed by majority voting based on the three individual models yields the highest prediction accuracy.
Example of three individual models attempting to predict 10 outputs of either Blue or Red. The correct predictions are Blue for all 10 outputs. An ensemble formed by majority voting based on the three individual models yields the highest prediction accuracy.
For this effect to work however, models included in the ensemble must not make the same kind of mistakes. In other words, the models must be uncorrelated. This is achieved via a technique called bootstrap aggregating (bagging).
In random forest, bagging is used to create thousands of decision trees with minimal correlation. (See a recap on How Decision Trees Work.) In bagging, a random subset of the training data is selected to train each tree. Furthermore, the model randomly restricts the variables which may be used at the splits of each tree. Hence, the trees grown are dissimilar, but they still retain certain predictive power.
The diagram below shows how variables are restricted at each split:
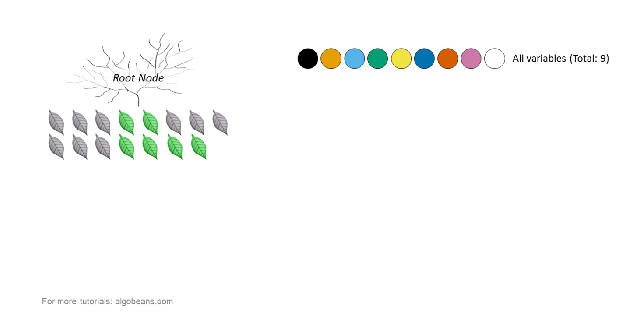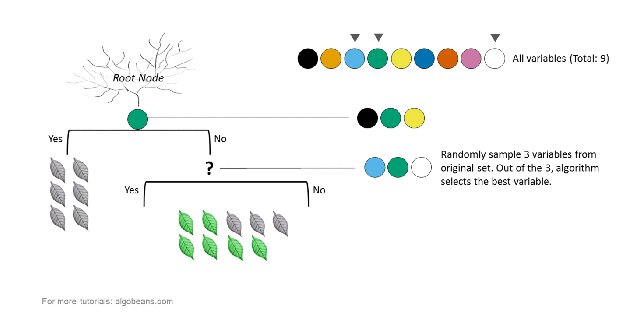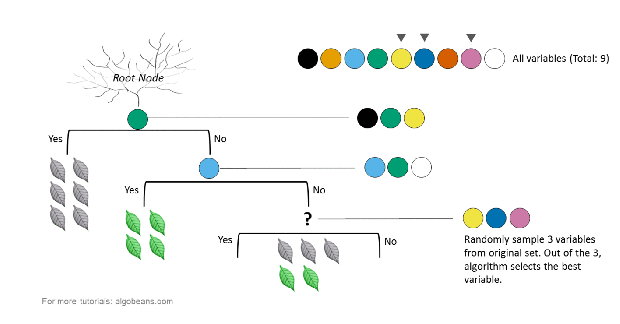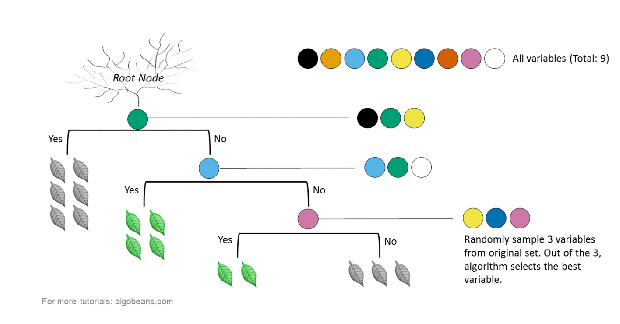
How a tree is created in a random forest
In the above example, there are 9 variables represented by 9 colors. At each split, a subset of variables is randomly sampled from the original 9. Within this subset, the algorithm chooses the best variable for the split. The size of the subset was set to the square root of the original number of variables. Hence, in our example, this number is 3.
Black box. Random forests are considered “black-boxes”, because they comprise randomly generated decision trees, and are not guided by explicitly guidelines in predictions. We do not know how exactly the model came to the conclusion that a violent crime would occur at a specific location, instead we only know that a majority of the 1000 decision trees thought so. This may bring about ethical concerns when used in areas like medical diagnosis.
Extrapolation. Random forests are also unable to extrapolate predictions for cases that have not been previously encountered. For example, given that a pen costs $2, 2 pens cost $4, and 3 pens cost $6, how much would 10 pens cost? A random forest would not know the answer if it had not encountered a situation with 10 pens, but a linear regression model would be able to extrapolate a trend and deduce the answer of $20.
Did you learn something useful today? We would be glad to inform you when we have new tutorials, so that your learning continues!
Sign up below to get bite-sized tutorials delivered to your inbox:
![]()
Copyright © 2015-Present Algobeans.com. All rights reserved. Be a cool bean.
Like this:
Like Loading…
Related