Document Similarity with Word Mover’s Distance
While Word2Vec is universally adopted in most modern NLP projects, document embedding and similarity have seen less success. There are many different approaches out there.

Popular document embedding and similarity measures:
-
Doc2Vec
-
Average w2v vectors
-
Weighted average w2v vectors (e.g. tf-idf)
-
RNN-based embeddings (e.g. deep LSTM networks)
I am going to try to explain another approach called Word Mover’s Distance (WMD) by Matt Kusner.
High Level Intuition
I have 2 sentences:
-
Obama speaks to the media in Illinois
-
The president greets the press in Chicago
Removing stop words:
-
Obama speaks media Illinois
-
president greets press Chicago
My sparse vectors for the 2 sentences have no common words and will have a cosine distance of 1. This is a terrible distance score because the 2 sentences have very similar meanings. Word Mover’s Distance solves this problem by taking account of the words’ similarities in word embedding space.
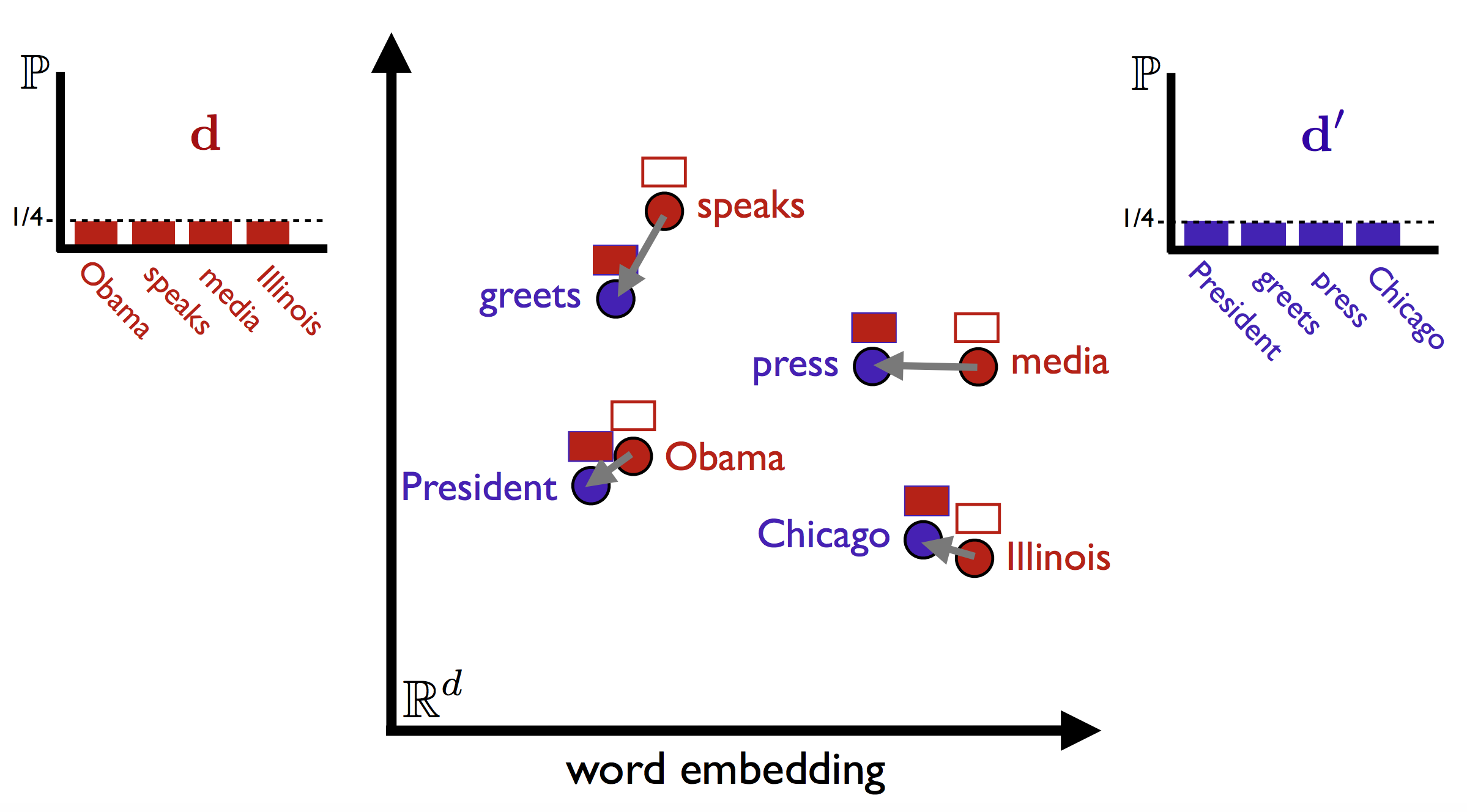
In this particular 2 sentence problem, each word is mapped to their closest counter part and the distance is calculated as the sum of their Euclidean distance.
In practice, WMD is very good at finding short documents (10 words or less) that are similar to each other.
Here are some of my results from training on IMDB.
Original sentence:
1 | |
Results for three:
1 | |
Results for show:
1 | |
Results for best:
1 | |
Flow
It’s very intuitive when all the words line up with each other, but what happens when the number of words are different?
Example:
-
Obama speaks to the media in Illinois –> Obama speaks media Illinois –> 4 words
-
The president greets the press –> president greets press –> 3 words
WMD stems from an optimization problem called the Earth Mover’s Distance, which has been applied to tasks like image search. EMD is an optimization problem that tries to solve for flow.
Every unique word (out of N total) is given a flow of 1 / N. Each word in sentence 1 has a flow of 0.25, while each in sentence 2 has a flow of 0.33. Like with liquid, what goes out must sum to what went in.

Since 1/3 > 1/4, excess flow from words in the bottom also flows towards the other words. At the end of the day, this is an optimization problem to minimize the distance between the words.

T is the flow and c(i,j) is the Euclidean distance between words i and j.
The Tradeoff between Granularity & Complexity
All of my code for this experiemnt is here. Feel free to try it out yourself. If I had more time, I’d definitely experiment more via trying out tf-idf weighed flow and visualizing documents in t-SNE.
Pros of WMD:
-
Very accurate for small documents, KNN methods can beat supervised embedding based ones
-
Interpretable for small documents unlike embeddings
Cons of WMD:
-
No embeddings for a document, meaning a lot of computation to get pairwise distance
-
Slow unless you relax the lower bound
-
Does not scale to large documents because flow become very convoluted between similar words
My personal thoughts are that while WMD has some very nice theoretical properties, currently it doesn’t scale well enough to be adopted in production.