Recently I’ve implemented, together with Arnaud Rachez, the SAGA[] algorithm in the lightning machine learning library (which by the way, has been recently moved to the new scikit-learn-contrib project). The lightning library uses the same API as scikit-learn but is particularly adapted to online learning. As for the SAGA algorithm, its performance is similar to other variance-reduced stochastic algorithms such as SAG[] or SVRG[] but it has the advantage with respect to SAG[] that it allows non-smooth penalty terms (such as $\ell_1$ regularization). It is implemented in lightning as SAGAClassifier and SAGARegressor.
We have taken care to make this implementation as efficient as possible. As for most stochastic gradient algorithms, a naive implementation takes 3 lines of code and is straightforward to implement. However, there are many tricks that are time-consuming and error-prone to implement but make a huge difference in efficiency.
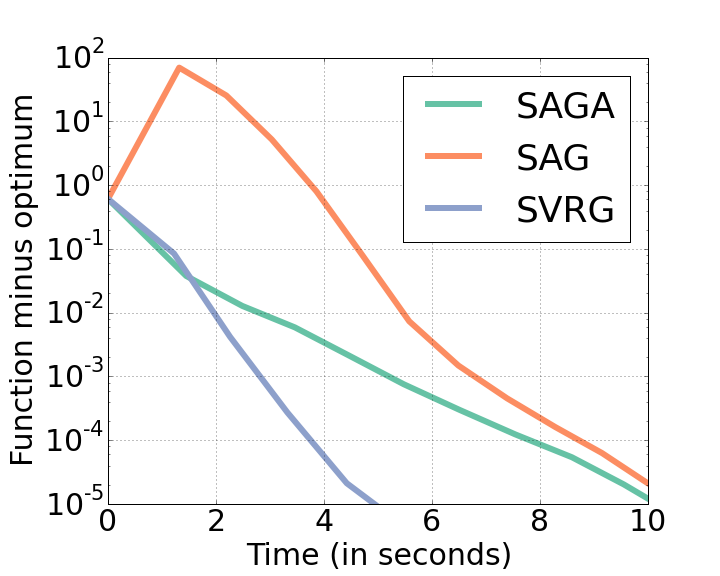
A small example, more as a sanity check than to claim anything. The following plot shows the suboptimality as a function of time for three similar methods: SAG, SAGA and SVRG. The dataset used in the RCV1 dataset (test set, obtained from the libsvm webpage), consisting of 677.399 samples and 47.236 features. Interestingly, all methods can solve this rather large-scale problem within a few seconds. Within them, SAG and SAGA have a very similar performance and SVRG seems to be reasonably faster.