### ICCV 2015: Twenty one hottest research papers
“Geometry vs Recognition” becomes ConvNet-for-X Computer Vision used to be cleanly separated into two schools: geometry and recognition. Geometric methods like structure from motion and optical flow usually focus on measuring objective real-world quantities like 3D “real-world” distances directly from images and recognition techniques like support vector machines and probabilistic graphical models traditionally focus on perceiving high-level semantic information (i.e., is this a dog or a table) directly from images.
The world of computer vision is changing fast has changed. We now have powerful convolutional neural networks that are able to extract just about anything directly from images. So if your input is an image (or set of images), then there’s probably a ConvNet for your problem. While you do need a large labeled dataset, believe me when I say that collecting a large dataset is much easier than manually tweaking knobs inside your 100K-line codebase. As we’re about to see, the separation between geometric methods and learning-based methods is no longer easily discernible.
By 2016 just about everybody in the computer vision community will have tasted the power of ConvNets, so let’s take a look at some of the hottest new research directions in computer vision.
ICCV 2015’s Twenty One Hottest Research Papers
To no surprise, this year’s ICCV is filled with lots of ConvNets, but this time the applications of these Deep Learning tools are being applied to much much more creative tasks. Let’s take a look at the following twenty one ICCV 2015 research papers, which will hopefully give you a taste of where the field is going.
1. Ask Your Neurons: A Neural-Based Approach to Answering Questions About Images Mateusz Malinowski, Marcus Rohrbach, Mario Fritz
“We propose a novel approach based on recurrent neural networks for the challenging task of answering of questions about images. It combines a CNN with a LSTM into an end-to-end architecture that predict answers conditioning on a question and an image.”
2. Aligning Books and Movies: Towards Story-Like Visual Explanations by Watching Movies and Reading Books Yukun Zhu, Ryan Kiros, Rich Zemel, Ruslan Salakhutdinov, Raquel Urtasun, Antonio Torralba, Sanja Fidler
 “To align movies and books we exploit a neural sentence embedding that is trained in an unsupervised way from a large corpus of books, as well as a video-text neural embedding for computing similarities between movie clips and sentences in the book.”
“To align movies and books we exploit a neural sentence embedding that is trained in an unsupervised way from a large corpus of books, as well as a video-text neural embedding for computing similarities between movie clips and sentences in the book.”
3. Learning to See by Moving Pulkit Agrawal, Joao Carreira, Jitendra Malik
“We show that using the same number of training images, features learnt using egomotion as supervision compare favourably to features learnt using class-label as supervision on the tasks of scene recognition, object recognition, visual odometry and keypoint matching.”
4. Local Convolutional Features With Unsupervised Training for Image Retrieval Mattis Paulin, Matthijs Douze, Zaid Harchaoui, Julien Mairal, Florent Perronin, Cordelia Schmid
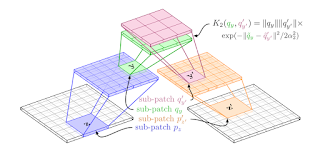
“We introduce a deep convolutional architecture that yields patch-level descriptors, as an alternative to the popular SIFT descriptor for image retrieval.”
5. Deep Networks for Image Super-Resolution With Sparse Prior Zhaowen Wang, Ding Liu, Jianchao Yang, Wei Han, Thomas Huang

“We show that a sparse coding model particularly designed for super-resolution can be incarnated as a neural network, and trained in a cascaded structure from end to end.”
6. High-for-Low and Low-for-High: Efficient Boundary Detection From Deep Object Features and its Applications to High-Level Vision Gedas Bertasius, Jianbo Shi, Lorenzo Torresani
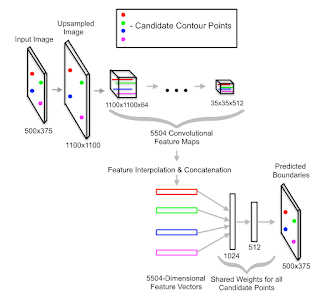
“In this work we show how to predict boundaries by exploiting object level features from a pretrained object-classification network.”
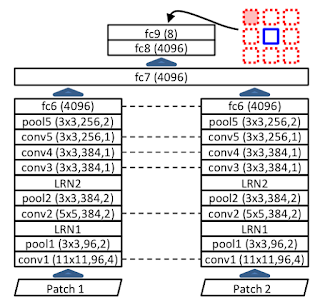
- A Deep Visual Correspondence Embedding Model for Stereo Matching Costs Zhuoyuan Chen, Xun Sun, Liang Wang, Yinan Yu, Chang Huang
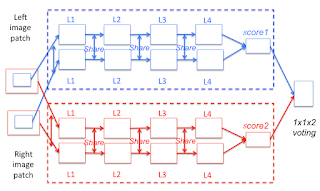
“A novel deep visual correspondence embedding model is trained via Convolutional Neural Network on a large set of stereo images with ground truth disparities. This deep embedding model leverages appearance data to learn visual similarity relationships between corresponding image patches, and explicitly maps intensity values into an embedding feature space to measure pixel dissimilarities.”
8. Im2Calories: Towards an Automated Mobile Vision Food Diary Austin Meyers, Nick Johnston, Vivek Rathod, Anoop Korattikara, Alex Gorban, Nathan Silberman, Sergio Guadarrama, George Papandreou, Jonathan Huang, Kevin P. Murphy

“We present a system which can recognize the contents of your meal from a single image, and then predict its nutritional contents, such as calories.”
9. Unsupervised Visual Representation Learning by Context Prediction Carl Doersch, Abhinav Gupta, Alexei A. Efros
“How can one write an objective function to encourage a representation to capture, for example, objects, if none of the objects are labeled?”
10. Deep Neural Decision Forests Peter Kontschieder, Madalina Fiterau, Antonio Criminisi, Samuel Rota Bulò

“We introduce a stochastic and differentiable decision tree model, which steers the representation learning usually conducted in the initial layers of a (deep) convolutional network.”
11. Conditional Random Fields as Recurrent Neural Networks Shuai Zheng, Sadeep Jayasumana, Bernardino Romera-Paredes, Vibhav Vineet, Zhizhong Su, Dalong Du, Chang Huang, Philip H. S. Torr
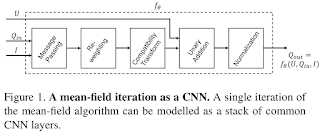
“We formulate mean-field approximate inference for the Conditional Random Fields with Gaussian pairwise potentials as Recurrent Neural Networks.”
12. Flowing ConvNets for Human Pose Estimation in Videos Tomas Pfister, James Charles, Andrew Zisserman
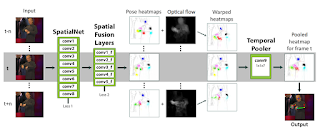
“We investigate a ConvNet architecture that is able to benefit from temporal context by combining information across the multiple frames using optical flow.”
13. Dense Optical Flow Prediction From a Static Image Jacob Walker, Abhinav Gupta, Martial Hebert
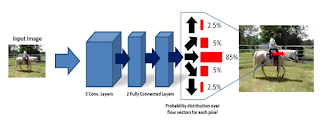 “Given a static image, P-CNN predicts the future motion of each and every pixel in the image in terms of optical flow. Our P-CNN model leverages the data in tens of thousands of realistic videos to train our model. Our method relies on absolutely no human labeling and is able to predict motion based on the context of the scene.”
“Given a static image, P-CNN predicts the future motion of each and every pixel in the image in terms of optical flow. Our P-CNN model leverages the data in tens of thousands of realistic videos to train our model. Our method relies on absolutely no human labeling and is able to predict motion based on the context of the scene.”
14. DeepBox: Learning Objectness With Convolutional Networks Weicheng Kuo, Bharath Hariharan, Jitendra Malik
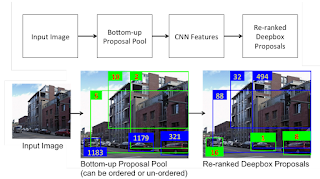
“Our framework, which we call DeepBox, uses convolutional neural networks (CNNs) to rerank proposals from a bottom-up method.”
15. Active Object Localization With Deep Reinforcement Learning Juan C. Caicedo, Svetlana Lazebnik

“This agent learns to deform a bounding box using simple transformation actions, with the goal of determining the most specific location of target objects following top-down reasoning.”
16. Predicting Depth, Surface Normals and Semantic Labels With a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus

“We address three different computer vision tasks using a single multiscale convolutional network architecture: depth prediction, surface normal estimation, and semantic labeling.”
17. HD-CNN: Hierarchical Deep Convolutional Neural Networks for Large Scale Visual Recognition Zhicheng Yan, Hao Zhang, Robinson Piramuthu, Vignesh Jagadeesh, Dennis DeCoste, Wei Di, Yizhou Yu
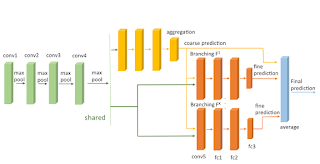
“We introduce hierarchical deep CNNs (HD-CNNs) by embedding deep CNNs into a category hierarchy. An HD-CNN separates easy classes using a coarse category classifier while distinguishing difficult classes using fine category classifiers.”
18. FlowNet: Learning Optical Flow With Convolutional Networks Alexey Dosovitskiy, Philipp Fischer, Eddy Ilg, Philip Häusser, Caner Hazırbaş, Vladimir Golkov, Patrick van der Smagt, Daniel Cremers, Thomas Brox
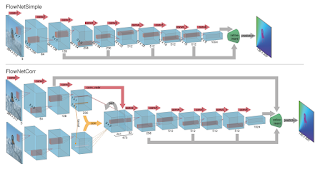
“We construct appropriate CNNs which are capable of solving the optical flow estimation problem as a supervised learning task.”
19. Understanding Deep Features With Computer-Generated Imagery Mathieu Aubry, Bryan C. Russell
 “Rendered images are presented to a trained CNN and responses for different layers are studied with respect to the input scene factors.”
“Rendered images are presented to a trained CNN and responses for different layers are studied with respect to the input scene factors.”
20. PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization Alex Kendall, Matthew Grimes, Roberto Cipolla
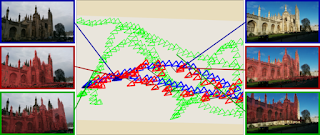
“Our system trains a convolutional neural network to regress the 6-DOF camera pose from a single RGB image in an end-to-end manner with no need of additional engineering or graph optimisation.”
21. Visual Tracking With Fully Convolutional Networks Lijun Wang, Wanli Ouyang, Xiaogang Wang, Huchuan Lu

“A new approach for general object tracking with fully convolutional neural network.”
Conclusion While some can argue that the great convergence upon ConvNets is making the field less diverse, it is actually making the techniques easier to comprehend. It is easier to “borrow breakthrough thinking” from one research direction when the core computations are cast in the language of ConvNets. Using ConvNets, properly trained (and motivated!) 21 year old graduate student are actually able to compete on benchmarks, where previously it would take an entire 6-year PhD cycle to compete on a non-trivial benchmark.
See you next week in Chile! **Update (January 13th, 2016)**
The following awards were given at ICCV 2015.
### Achievement awards
-
PAMI Distinguished Researcher Award (1): Yann LeCun
-
PAMI Distinguished Researcher Award (2): David Lowe
-
PAMI Everingham Prize Winner (1): Andrea Vedaldi for VLFeat
-
PAMI Everingham Prize Winner (2): Daniel Scharstein and Rick Szeliskifor the Middlebury Datasets
-
PAMI Helmholtz Prize (1): David Martin, Charles Fowlkes, Doron Tal, and Jitendra Malik for their ICCV 2001 paper “A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics”.
-
PAMI Helmholtz Prize (2): Serge Belongie, Jitendra Malik, and Jan Puzicha, for their ICCV 2001 paper “Matching Shapes”.
-
Marr Prize: Peter Kontschieder, Madalina Fiterau, Antonio Criminisi, and Samual Rota Bulo, for ”Deep Neural Decision Forests”.
-
Marr Prize honorable mention: Saining Xie and Zhuowen Tu for”Holistically-Nested Edge Detection”.