Now that Kaggle’s Denoising Dirty Documents Competition has closed, it’s time to start posting the secrets to getting a very good score in this competition. In this blog, I describe how to take advantage of the first of two information leakages that I used.

Information leakage occurs in predictive modelling when the training and test data includes values that would not be known at the time a prediction was being made. For example, I once worked on a direct marketing sales propensity modelling project where our predictive model fitted the training data far too well, making us suspicious. We eventually tracked it down to an incorrectly designed data extract that used status values as at the data extraction date, instead of as at the date at which a prediction would have been run. The sale of the product to the customer changed the value of that data field, so the data needed to be the value of the data field before the sale occurred. In real life projects, information leakage is a bad thing because it overstates the model accuracy. Therefore you need to ensure that it does not occur; otherwise your predictive model will not perform well. In data science competitions, information leakage is something to be taken advantage of. It enables you to obtain a higher score.
The first information leakage in this competition comes from how the training data was created. There are only 8 different page backgrounds. There are 2 coffee cup stains, 2 folded pages, 2 watermarks and 2 crumpled pages.

This gives us a huge advantage in removing the background and the stains. Instead of using an uncertain estimate based upon only a single image, we can group together the images so that each group has the same background. Then, for each pixel location, calculate the brightest pixel across all of the images in that group, and use the brightest value as the pixel brightness in the background. You can find a couple of scripts on Kaggle that do this.
The problem is that you can’t do the same for the test images because they have different backgrounds, and they have only four different backgrounds. You can’t have known this without manually looking at the test images, and that break the rules prohibiting manual processing of the test images.

You can also run into troubles if your model just assumes that the test images are arranged so that there are 8 different background images that repeat every 8 images.
A better solution is to let your model decide which images can be grouped together, and let your model decide which background belongs with each image. The way to do this is to apply a median filter to each image, to obtain an estimate of the background of each image, and then group the median images together according to similarity.
The script above calculates the median filter for each image and stores it in a folder. I have used a filter size of 25 pixels because I want broad patterns of the background, and I want the text removed.
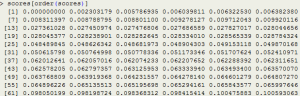
Now that I have the median images, I can iterate through each training image and link it to other images that have similar median images. I have used RMSE as a measure of similarity. The cutoff RMSE of 2.5% was determined by looking at the range of RMSE values and looking for a natural break.
One of the tricks in the script above was that I didn’t simply subtract the background from the image. If I had done that, then the result would not be consistent in areas where the stains occur:


Notice that in the image above, the writing is faded where the stain was dark. That’s because it was created with the code:
Where the background is dark, there is less opportunity for the writing to contrast against the background. To fix this, I changed the above script to be:
By dividing the difference by the background brightness, I have rescaled the contrast to allow for the limitation on the maximum contrast at this location. The result is shown below: This time the writing has consistent darkness across the entire image, regardless of the brightness of the background pixels.
This time the writing has consistent darkness across the entire image, regardless of the brightness of the background pixels.
My competition submission consisted of 4 stages, and this leakage-based background removal was the first stage. The final stage also took advantage of an information leakage. But you will have to wait for a couple of blogs to see what that was…
Like this:
Like Loading…
Related