Are youJava Developer and eager to learn more about Deep Learning and his applications, but you are not feeling like learning another language at the moment ? Are you facing lack of the support or confusion with Machine Learning and Java?
Well you are not alone , as a Java Developer with more than 10 years of experience and several java certification I understand the obstacles and how you feel.
From my experience I know what obstacles a Java software engineering faces with the Deep Learning so I can be of a great help to you in making the journey with deep learning an exciting experience.
In this post we are going to develop a Neural Network with Java for training and detecting Handwritten Digits(0-9). A real application is build using Java and Apache Spark MLib .Feel free to check out the source code and experiment on your own(fairly short instructions at the end).
Biologically Motivated
Neural Network as their name suggests are motivated from Brain Biological Neurons. Although the brain is a highly complicated organ and some of his function still remain mystery to us , the cells which is made of Neurons are fairly simple. I am quoting the explanation from this site :
The neuron is broken up into two major regions:
- A region for receiving and processing incoming information from other cells
- A region for conducting and transmitting information to other cells
The type of information that is received, processed and transmitted by a neuron depends on its location in the nervous system. For example, neurons located in the occipital lobe process visual information, whereas neurons in the motor pathways process and transmit information that controls the movement of muscles. However, regardless of the type of information, all neurons have the same basic anatomical structure.

Basically Neurons are made of an input(dendrites) , computational unit(cell body, nucleus)and output(axon). So signals(pulse of electricity spikes) come from other neuron axons to some of the dendrites, than the neuron processes the signals and finally transmits the signals though his axon to some of other neurons dendrites.Basically something like the picture below suggest(source):

So the question is can we copy this fairly simple model to a more computer friendly model? After all that is what computers do best getting inputs , processing them and outputting.
Imitating the Nature
So what we will need is a model which take inputs , transforms them and outputs in a form which is ready for other similar models to consume. A good candidate model will may be like below:

With blue we mark the neuron and green the inputs.
So basically the model is processing some inputs numbers likeX1 X2 … Xn and than outputting the result. We need of course to clarify how we are going to process the inputs. In my knowledge how the real Neuron processes the signal is not known. Anyway we can use some well known function seen at previous posts at Logistic Regression the Sigmoid Function. Just to recall the Sigmoid Function looks like below:

Sigmoid function is outputting approx. 1 when inputs tend to be greater than zero and approx. 0 when values tend to be smaller than zero.
So lets take an example how our model looks so fare:

With blue we mark the neuron and green the inputs.
Since the summation of all our inputs is negative(-5 in figure is zero) the output is 0. On the other hand if the outputs will be like X1=10 ,X2=-20, X3=30 ,X4=-5 the output will be 1.
Multiple Outputs
So fare so good but as we saw the Neuron had multiple outputs not only one as our simple model suggests. And the outputs are not just clones of one but each is different. To adapt our model we will introduce the concept of weights Θ. So before output is transmitted we will multiply by some weights(Θ). Lets see below how our model looks like now:

With blue we mark the neuron and green the inputs.
Now we are able to produce multiple different outputs just by multiplying by weights(Θ). As the figure suggested we multiply the output 1(25 in sigmoid function is 1) with weights(Θ) and got 3, -5 and 10 as outputs.
Is worth to notice that even if the inputs are the same the outputs differs from the previous model -5->0 to 25->1 .This happens because of the impact weights(Θ) introduce into the model. Since we gave a lot of importance to X2 by multiplying with weight Θ2=2 the model produces a positive result now. In a few words weights(Θ) besides gave us a model supporting multiple outputs also gave a way to greatly impact the model itself(output).
Multiple Neurons(Network)
Till now the model processes multiple inputs with sigmoid function and produces multiple outputs by multiplying with weights(Θ). Although similar in a sense to the biological neuron this is an isolated model. After wall we have billions of neurons connected and communicating all the time. So now is time to connect our model in a a network.
So fare we connected multiple inputs with only one neuron which in his hand produces multiple outputs(unconnected). We can enrich our model by connecting the inputs not only with one neuron by with many of them. This model will look like below:

With blue we mark the neurons and green the inputs.
The model now looks more like a network as it gives the the flexibility of connecting different inputs with different neurons. Although the model is not yet complete as in reality Neurons on their hand can connect with other Neurons and this Neurons with others and son on… It is time to do a final modification to the model by introducing another Layer of Neurons which is connected with previous Neurons.

With blue we mark the neurons and green the inputs.
Now we have a model which can easily grow to a big network and can even have different shapes. Is worth to mention that Neurons of Layer 1 are just inputs for Neurons of Layer 2. Sigmoid Function was applied once in Layer 1 multiplied by weights(Θ) and than applied again inLayer 2 and maybe if another layer will be added would be applied again depending how deep we want to go.
How to use the model(Hypothesis)
So fare we have build a model which is quite similar to real Neuron Networks as it can process multiple inputs is able to transmit multiple outputs to other neurons connected to the network. What we are missing is how to train the model so it can help us predict or solve problems.
As we saw previously in Logistic Regression and SVM we will need a model which generates a hypothesis first. To be able to train you will need first to generate some answer called hypothesis and than evaluate how well this is doing in comparison to what we want or real value. After evaluating or getting the feedback we need to adjust the model so it will produce a better hypothesis or one which generates answers closer to real values. Of course first the hypothesis can be very fare from what we want but anyway all starts with an hypothesis.
For Neural Networks(NN) the hypothesis is identical to Logistic Regression so it is represented by Sigmoid Function:

Z is the function explained in topic Insight.
Z is also identical to what is explained at Logistic Regression Insight with only one difference that we have multiple Z at NN in comparison to one in LR(Logistic Regression).To understand that lets see the formal representation of Z for LR:
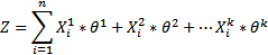
n**-> number of examplesk-> number of featuresθj -> weight for feature jXji -> the i-th example X with feature j
In the cancer prediction example we can write like below(age, diet, genome are features and the numbers are weights Θ):

One can easily notice that the weights Θare defining how much a feature is contributing to final prediction or hypothesis so better weights Θ **better or hypothesis will do in comparison to real values.** Now lets see why we have multiple Z for NN by taking only one Neuron first:

As we can see the above calculation for multiple outputs and one neuron is the same as logistic regression: Z=Θ1 * X1 + Θ2 * X2 + …. Θn * Xn and where sig(Z)** **
One can easily spot that adding another neuron will lead to all inputs connecting to that neuron and as consequence having another Z2born like below:

Not only we have a new Z for a new connected neuron but also the weights Θchanged from a Vector(Θi ) to a Matrix like Θij where iis denoting the input and jthe neuron that we are connecting to. There is one last piece missing, adding another layer of Neurons and connect outputs of Neurons on Layer 1 to Neurons of Layer 2.

Beside that the picture become a bit more messy we can notice that also now we have multiple Zi per each layer so Zij where idenotes the neuron and jdenotes the layer this neurons belong to. Notice that also we mark Θkij with extra kjust to represent the layer which the weight is contributing to. Differently from LG we just have multiple Z’s and h(X)’s but Z and h(x)(sig(Z) or hypothesis) itself stays the same:
So NN introduce for each layer a hypothesis(Sig(Z) ) per neuron in comparison to LG which had only one hypothesis and tried to fit all data there.Is like NN are trying to figure out the solution step by step instead of all at once. Each hypothesis’s output is multiplied by Θand entered as input to another neuron which on his hand produces another hypothesis and so on… until we have the final output which we can interpret as the answer.

Cost Function
As we mention earlier once we have a hypothesis we need a another method or function which tells us how good our hypothesis is in comparison with real value we have from labeled data. The function is called cost function and is just doing the average squared difference of the hypothesis with real data value , identical to LG (ignoring regularizing parameters):

where yi is the real value or category like spam or not spam 1 or 0 and h(x) is the hypothesis and m the number of examples we have for training.
Supposing we have only one output the formula stays identical with LG. It just of course hΘ(xi) is calculated differently. Here hΘ(xi) is referring to the final hypothesis but as we know this hypothesis has gone to a long way of calculations and re calculations from layer to layer and neuron to neuron.Something like hΘ(hΘ(hΘ(hΘ(x1))))…(plus other hΘ and multiplying by Θ).
How about for different outputs? Well is not changing much we just need another loop for each outputyik (where k refers to the output k and m is number of outputs):

Ideally we want our cost function J to be zero so hypothesis will equal to real value or at least the difference to be as small as possible. In a few words once we find a way to minimize this cost function than we have a model ready to predict as it already learned to generate hypothesis as close as possible to real labeled data values.
Minimizing Cost Function
So fare we have a hypothesis also a function to tell how good the hypothesis is doing in regards to real data. Now we are ready to use the feedback to improve our hypothesis to be more close to labeled data or real data we have. Again here the procedure is the same as LG we simply use Gradient Descent(previous LG post) to minimize the cost function.
First we pick up random values of θ just to have some values,than calculate cost function. Depending on results we can lower our θ values or increase so the cost function is optimize to zero. We repeat this procedure until the cost function is almost zero(0.0001) or is not improving much iteration to iteration.
It uses derivative of cost function to decide if to lower or increaseθ values. Beside the derivative, which is just giving a direction to lower or to increase θ value, it also uses a coefficient α to define how much to change theθ values.
Derivation is also where the LG differs from NN since NN are using a more sophisticated way of calculating the derivative known as Back Propagation Algorithm. Although Back Propagation Algorithm is very interesting , is also heavily mathematically intensive and maybe I will address it in more details in next post. But for now we can think it as a black box which gives use the derivative of the final cost function. After that Gradient Descent can easily minimize so that the hypothesis output and real values can be as similar as possible(ideally the difference is zero).
Application
Data
Data used for building the application were taken from this web site :
MNIST database has 60.000 of training data and 10.000 of test data. The data contain black white hand written digit images of 28X28 pixels. Each pixel contains a number from 0-255 showing the gray scale, 0 while and 255 black.
The way the data are organized is not in any of standard image format. But fortunately there was already a solution reading the data perfectly and surprisingly easy(thanks to StackOverflow comment). Here is how we read the data : for each entry we build a java bean LabeledImage:
It has the Label which is the real digit from 0-9 and Features Vector(used Vector because of MLib requirements ,List,ArrayList will be fine for more general purposes) which represent the pixels in one dimension. So in our case we have 28X28 pixels which contain a number from 0-255 this will mean we have a single array with length 784 containing numbers from 0-255. After reading the data we will have a list of **LabeledImage like List
Configure Neural Network
We described so far the model which had the input, different number of layers which are processing and output.We did not describe the real nature of the input because it was more abstract at that time but now is time to explain in a more specific way.
The input on the model we described(X1…Xn) is the Features Vector onLabeledImageobject.Lets think of one example represented by one LabeledImage object which has inside Features Vectors (is simply a one dimensional vector containing pixels 28X28->784 values from 0 -255). The input of our model is the Features Vectorsso the input size is 784. Of course this is the case of one example so to scale for more examples we simply execute the model for each example. In a few words the inputs X1..Xn are not the examples but the features of your data for one example(n in our case is 784). So to fully train your model you will need to compute cost function,derivative for each example.
The output on the other hand is more easy to reason because we have 10 digits to discover from 0 – 9 so the output is a one dimensional vector of size 10. The values of output vector are probabilities that the input is likely to be one of those digits. So lets say we already trained our model and now we are asking it to predict a 28X28 image(3). The output maybe something like this : [0.01, 0.1, 0.4, 0.95, 0.02, 0.05, 0.03 , 0.1, 0.5 ,0.02]this is translated like : there is 0.1 % probability the input is 0, there is 1% probability the input is 1 , there 40% probability the input is 2 , there is 95% probability the input is 3 and so on… So the index of the item in the vector represent the digit and the value the confidence the model has that the input is that digit.
So fare we have a model with an input of size 784 and an output of a size 10. Now is time to configure the other layers or the hidden layers. Where there is no magic way of deciding we ended choosing two hidden layers : 128 and 64 neurons. Theoretically more layer better it is but the training it will also be much slower. So deciding about layers is mostly based on the desired accuracy of the model. There is room for improvement here maybe in future is worth to try different layers configuration and see what it will work best. Also this can be done automatically and then choosing the best model. The code for training looks like below:
Normalizing Data
When I first tried to train the network the results were a disaster…. only 10% of images were able to detect correctly. Than I notice that the data were not uniform in a sense that one can find values like 0 , 0 ,0 1,2, 200,134,68 …. So I decide to normalize data to have more uniform values between 0 and 1. The formula we already explain on previous post is like below:

Where μi is the average of all the values for feature (i) and si is the range of values (max – min), or the standard deviation.
So what we do is for each feature in our case each pixel value we subtract with the mean of all pixel for that image and divide with difference between max pixel value and min pixel value on that image. The code looks like below:
This implementation is not 100% according the formula we saw above because it normalizes per example/image(average,max,min are calculated on one image pixels). While the formula we saw above requires calculation of average,max,min on all examples/images pixels and than subtract with that average and divide with that max-min each image pixels. Since our example is a simple black and white image this normalization works fine, there are even more simple implementations like deeplearning4j just divides with 255 for hand writing digits Mnist Dataset. Anyway in other applications the above formula should really be applied on all examples and per feature.
Results and Improvements
After applying normalization accuracy increased dramatically to 97%. So only 3% were wrongly detected by the mode. This is a good results taking into account the simplicity of the model and the effort. Almost everything else was handle automatically by the Model and Back Propagation algorithm.
Of course there is plenty room for improvement in here:
-
We can play with the model configuration and layers. So to say we can add layers or more neurons in current two layers and choose the model which increases the accuracy.
-
This is rather a simple Neural Network so is worth trying more advance Neural Networks like : Convolutional Networks which usually give great results.
-
The data are already reprocessed but we can do even better. As is mention here deskewing and centering the images can greatly improve the accuracy of the model. Though this are quite advance image techniques and require great effort to get good results we can use here also some other machine learning algorithms like K – Means.
-
Although not use in this post I think applying PCA is worth trying as we have too many features(784).
-
The application provides the opportunity to draw the digit by yourself and try to see how the algorithm predicts it. Please notice that because we do not use any centering to the drawing as the original images have used in the training the result may be poor if you do not draw in the center. So there is plenty to improve in the centering, bluing and deskewing of the drawing as well.
Run Application
Application can be downloaded and executed without any knowledge of java beside JAVA has to be installed on your computer. You can try it by your self by choosing different options like:
-
training data size default to 30.000 and test data size default to 10.000
-
number of neurons and layers, not yet added(contributions appreciated https://github.com/klevis/DigitRecognizer)
Application already loads a default training executed before hand with accuracy 97% tested in 10.000 of test data and trained with 60.000 images(two layers 128 neurons, 64neurons).
!!Please try to draw in the center as much as possible as the application do not use centering or crop as the data used for training.
We can run the application from source by simply executing the RUN class or if you do not fill to open it with IDE just run mvn clean install exec:java.**
Application was build using Swing as GUI and Spark MLib for the executing the run.bat would show the below GUI:

Found useful , feel free to share